

作者|冬梅
通常情况下,在 I/O 大会前的几周里,外界不会听到太多 I/O 大会的消息,因为谷歌一般会把最好的模型留到 I/O 大会上发布。但在 Gemini 时代,谷歌很可能会在三月的某个周二突然发布出他们最强的人工智能模型,或者提前一周宣布像 AlphaEvolve 这样的酷炫突破。
因为大模型时代,尽快将最好的模型和产品送到用户手中,是企业技术能力的展现。
北京时间 5 月 21 日凌晨一点,随着多个产品在 2025 谷歌 I/O 大会上发布,现场响起了一波又一波热烈的掌声。
在本场发布会上,作为主题演讲嘉宾,谷歌首席执行官桑达尔·皮查伊在一个多小时的时间里紧锣密鼓地介绍着谷歌在 AI、移动操作系统、搜索等领域的众多更新,这一场发布会上初步统计,Gemini 被提及 95 次,人工智能被提及 92 次。
以下是本场发布会的几个重要更新,首先是模型层面。
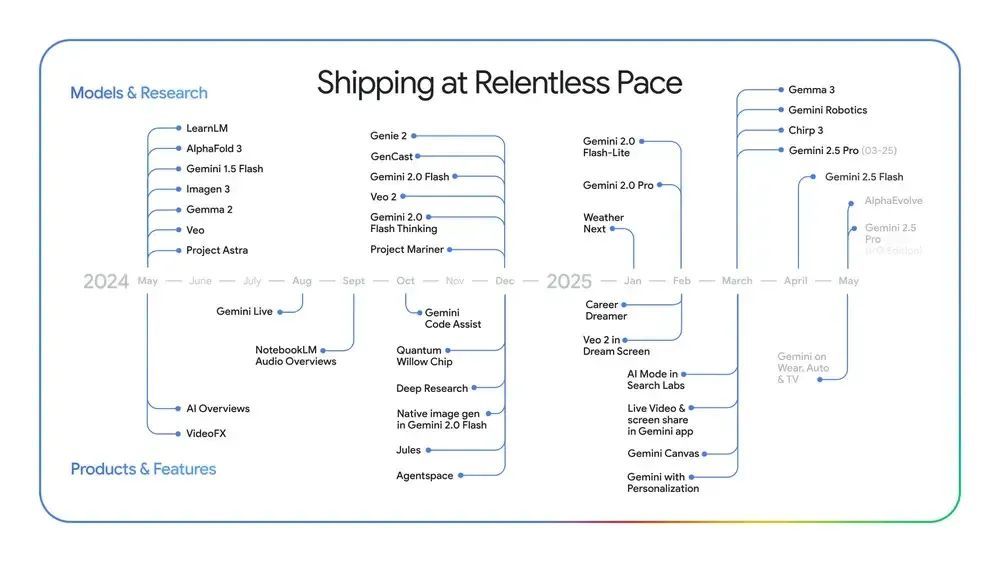
为 Gemini 2.5 Pro 引入 Deep Think 推理模型和更好的 2.5 Flash
此次发布会的高潮部分,是谷歌宣布为 Gemini 2.5 Pro 引入 Deep Think 推理模型和更好的 2.5 Flash。

谷歌在大会上宣布,已开始为 Gemini 2.5 Pro 测试名为“深度思考”(Deep Think)的推理模型。DeepMind 首席执行官 Demis Hassabis 表示,该模型采用“最前沿的研究成果”,使其具备在回应查询前权衡多种假设的能力。
2.5 Pro Deep Think 在目前最难的数学基准测试之一——2025 USAMO 上取得了令人印象深刻的成绩。它在 LiveCodeBench(一项针对竞赛级编程的难度较高的基准测试)上也取得了领先,并在测试多模态推理的 MMMU 上获得了 84.0% 的分数。”
不过谷歌表示,在广泛发布前仍需进行更深入的安全评估并征求专家意见,因此将率先通过 Gemini API 向可信测试者开放。
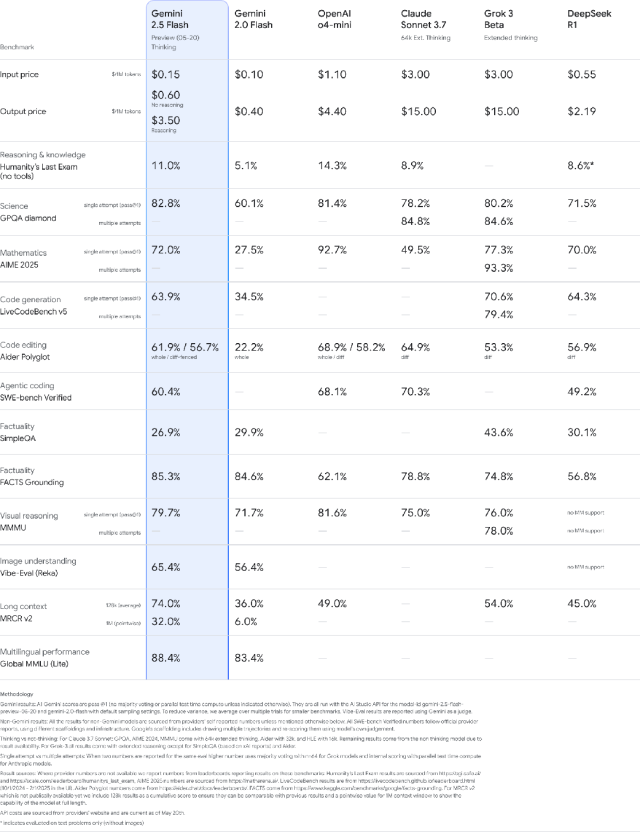
谷歌同时发布了性能更强的 Gemini 2.5 Flash 模型,该版本在速度与效率方面实现显著优化:推理效率提升、令牌消耗减少,在多模态处理、代码生成及长文本理解等基准测试中均超越前代。
2.5 Flash 是谷歌最高效的主力模型,专为速度和低成本而设计——现在它在多个维度上都得到了提升。它在推理、多模态、代码和长上下文等关键基准上都得到了改进,同时效率进一步提升,在我们的评估中,使用的 token 减少了 20-30%。
正式版将于 6 月初推出,目前开发者可通过 Google AI Studio 预览,企业用户可通过 Vertex AI 体验,普通用户则可在 Gemini 应用中试用。
虽然 I/O 大会主要展示的是 2.5 Flash 的效能突破,但谷歌宣布将把该模型的“思考预算”(Thinking Budgets)概念引入更高阶的 2.5 Pro 版本。这项功能允许用户平衡 token 消耗与输出精度 / 速度的关系。
此外,谷歌正将"航海家计划"(Project Mariner)整合至 Gemini API 和 Vertex AI。该项目基于 Gemini 开发,能通过浏览器导航完成用户指定任务,预计今夏向开发者扩大开放。同时,谷歌还通过 Gemini API 为 2.5 Pro/Flash 模型推出文本转语音功能预览版,支持 24 种语言的两种发音人声。
值得一提的是,Gemini 2.5 系列引入了不少新功能。
首先是原生音频输出和 Live API 的改进。Live API 推出了音频视频输入和原生音频输出对话的预览版,因此您可以直接构建对话体验,使用更自然、更具表现力的 Gemini。
它还允许用户控制其语气、口音和说话风格。例如,用户可以让模型在讲故事时使用戏剧性的声音。它还支持使用工具,以便能够代表用户进行搜索。
现在,可以供用户尝试的一系列早期功能包括:
情感对话,模型可以检测用户声音中的情感并做出适当的反应。
主动音频,其中模型将忽略背景对话并知道何时做出回应。
在 Live API 中思考,其中模型利用 Gemini 的思考能力来支持更复杂的任务。
谷歌还将为 2.5 Pro 和 2.5 Flash 版本发布全新的文本转语音功能预览版。这些功能首次支持多扬声器,能够通过原生音频输出实现双声道文本转语音。
与 Native Audio 对话一样,文本转语音功能富有表现力,能够捕捉到非常细微的差别,例如低语。它支持超过 24 种语言,并可在多种语言之间无缝切换。
其次是电脑操作能力提升。谷歌正将 Project Mariner 的电脑操作能力引入 Gemini API 和 Vertex AI。支持多任务处理,最多可同时执行 10 个任务,并且新增 “Learn and Repeat” 功能,让 AI 学会自动完成重复性任务。
第三是显著增强了对安全威胁的防护,例如间接提示注入。这是指恶意指令被嵌入到 AI 模型检索的数据中。谷歌 全新的安全方法 显著提高了 Gemini 在工具使用过程中对间接提示注入攻击的防护率,使 Gemini 2.5 成为我们迄今为止最安全的模型系列。
第四是增加三大实用功能,提升开发者体验:
思维摘要功能升级。Gemini API 和 Vertex AI 现为 2.5 Pro/Flash 模型新增"思维摘要"功能,可将模型原始推理过程结构化输出为带标题、关键细节及操作说明(如工具调用时机)的清晰格式。该设计旨在帮助开发者更直观地理解模型决策逻辑,提升交互可解释性与调试效率。
思考预算机制扩展。继 2.5 Flash 之后,思考预算功能现已覆盖 2.5 Pro 模型,允许开发者通过调节令牌分配来平衡响应质量与延迟成本。用户可自由控制模型思考深度,甚至完全关闭该功能。支持全量思考预算的 Gemini 2.5 Pro 正式版将于未来数周内发布。
Gemini SDK 兼容 MCP 工具。Gemini API 新增对 MCP 的原生 SDK 支持,简化与开源工具集成。谷歌正探索部署 MCP 服务器等托管方案,加速代理应用开发。团队将持续优化模型性能与开发体验,同时加强基础研究以拓展 Gemini 能力边界,更多更新即将推出。
关于谷歌 Gemini 的下一步,谷歌 DeepMind CEO 哈萨比斯表示,他们正努力将其最优秀 Gemini 模型扩展为一个 “世界模型”,使其能像人类大脑一样通过理解和模拟世界来制定计划、想象新体验。
AI Mode 是谷歌搜索的未来
作为谷歌最核心的业务之一,谷歌搜索的每次迭代都会引发行业关注。
谷歌表示, Gemini 模型正在帮助谷歌搜索变得更加智能、代理化和个性化。
自去年推出以来,AI 概览已覆盖超过 15 亿用户,并覆盖 200 个国家和地区。随着人们使用 AI 概览,谷歌发现他们对搜索结果更加满意,搜索频率也更高。在美国和印度等谷歌最大的市场,AI 概览推动了查询类型增长超过 10%,并且这种增长速度会随着时间的推移而持续增长。
皮查伊称,这是过去十年来搜索领域最成功的产品之一。
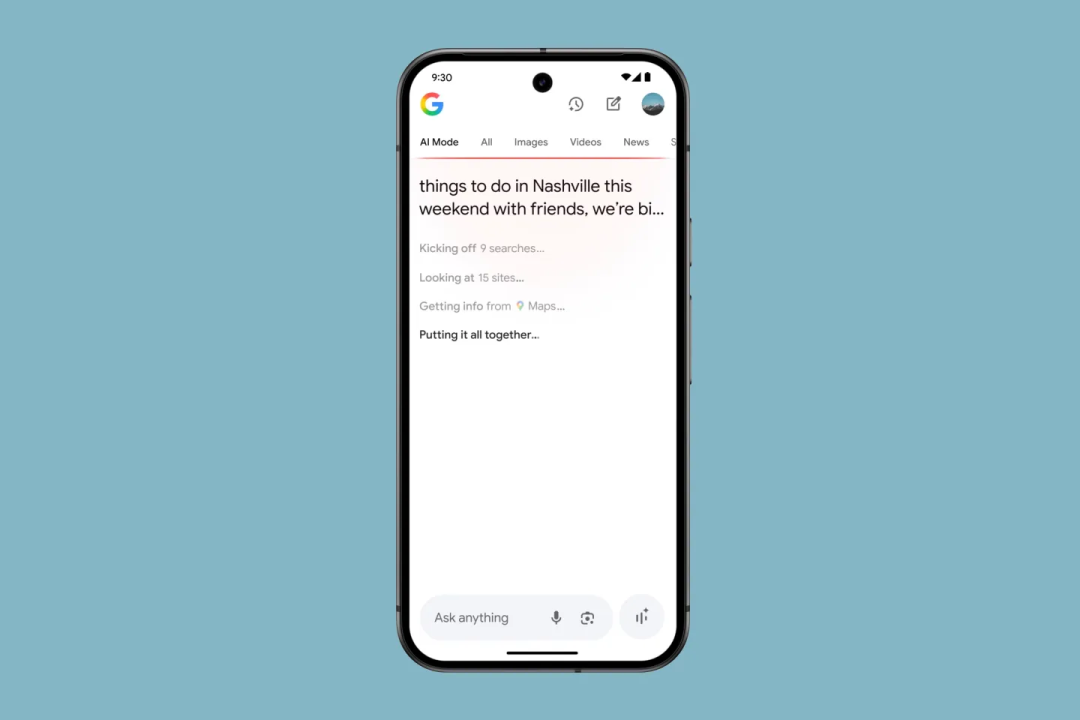
如今,对于想要体验端到端 AI 搜索的用户,谷歌推出了全新的 AI 模式。它彻底重塑了搜索体验。凭借更先进的推理能力,用户可以在 AI 模式下提出更长、更复杂的查询。
事实上,早期测试人员提出的查询长度是传统搜索长度的两到三倍,并且用户还可以通过后续问题进行更深入的探索。所有这些功能都可以在搜索的新标签页中直接使用。
皮查伊称:“我一直在频繁使用 Google 搜索,它彻底改变了我使用 Google 搜索的方式。我很高兴地告诉大家,AI 模式将于今天在美国面向所有用户推出。借助我们最新的 Gemini 模型,我们的 AI 响应不仅达到了您对 Google 搜索所期望的质量和准确性,而且是业内最快的。从本周开始,Gemini 2.5 也将在美国 Google 搜索中推出。”

亮相视频模型 Veo 3
在多模态方面,谷歌表示即将推出最新的先进视频模型 Veo 3,它现已具备原生音频生成功能。谷歌还将推出 Imagen 4,这是谷歌最新、功能最强大的图像生成模型。这两款模型均可在 Gemini 应用程序中使用,开启一个全新的创意世界。
谷歌通过一款名为 Flow 的新工具将这些可能性带给了电影制作人。用户可以创建电影剪辑,并将短片扩展为更长的场景。
提示词:一只睿智的老猫头鹰在高空翱翔,透过森林上方月光下的云层窥视。这只睿智的老猫头鹰小心翼翼地绕着空地盘旋,环顾着森林的地面。片刻之后,它俯冲到月光下的小路上,停在一只獾旁边。音频: 翅膀拍打声、鸟鸣声、响亮而悦耳的风沙声,以及断断续续的嗡嗡声、树枝在脚下折断的声音和呱呱的叫声。这是一段轻快的管弦乐,木管乐器贯穿始终,节奏欢快乐观,充满天真无邪的好奇心。
一只睿智的老猫头鹰和一只紧张的獾坐在月光下的林间小路上。“它们今天留下了一个一个'球’。它弹得比我跳得还高。”獾结结巴巴地说道,努力想理解这句话的意思“这是什么魔法?"猫头鹰若有所思地鸣叫着。音频: 猫头鹰的鸣叫声,獾紧张的鸣叫声,树叶的沙沙声,蟋蟀的鸣叫声。
一只睿智的老猫头鹰飞出了画框,一只紧张的小獾朝另一个方向跑了出去。背景中,一只松鼠匆匆而过,发出刮擦干枯秋叶的沙沙声。音频: 鸟鸣声、响亮的落沙沙声,以及断断续续的嗡嗡声、树枝在脚下折断的声音,还有松鼠在干枯的落叶间穿梭的声音。远处传来猫头鹰的鸣叫声、獾紧张的鸣叫声、树叶的沙沙声、蟋蟀的鸣叫声,这些声音充满了天真好奇的气息。
编码助手 Jules 开始公测
在发布会上,谷歌宣布 Jules 正式进入公测阶段,全球开发者可直接进行体验。
Jules 是一款异步代理式编码助手,可直接与开发者现有的代码库集成。它会将开发者的代码库克隆到安全的 Google Cloud 虚拟机 (VM) 中,了解项目的完整上下文,并执行以下任务:编写测试、构建新功能、提供音频更新日志、bug 修复、改变依赖版本。
Jules 异步运行,让开发者在它在后台运行时能专注于其他任务。完成后,它会展示其计划、推理过程以及所做更改的差异。Jules 默认为私有,它不会使用用户的私有代码进行训练,并且用户的数据在执行环境中保持隔离。
Jules 使用 Gemini 2.5 Pro,使其能够使用当今最先进的一些编码推理技术。结合其云虚拟机系统,它可以快速、精确地处理复杂的多文件更改和并发任务。
具体而言,Jules 能干什么?
适用于真实代码库:Jules 无需沙盒。它能够利用现有项目的完整上下文,智能地推断变更。
并行执行:任务在云虚拟机内部运行,实现并发执行。它可以同时处理多个请求。
可见的工作流程: Jules 在进行更改之前向您展示其计划和理由。
GitHub 集成:Jules 可直接在用户的 GitHub 工作流程中工作。无需上下文切换,也无需额外设置。
用户可控性:在执行之前、执行期间和执行之后修改所呈现的计划,以保持对代码的控制。
音频摘要: Jules 提供最近提交的音频变更日志,将您的项目历史记录转变为您可以收听的上下文变更日志。
Astra 项目,谷歌通用 AI 助手的雏形
去年的谷歌 I/O 开发者大会上,最有趣的演示之一是 Project Astra,它是多模态人工智能的早期版本,可以实时识别周围环境并以对话方式回答相关问题。虽然该演示让我们得以一窥谷歌打造更强大人工智能助手的计划,但该公司谨慎地指出,我们看到的只是“研究预览”。
然而,一年后,谷歌却规划了 Astra 项目的愿景,希望未来能为 Gemini 的某个版本提供动力,使其成为一个“通用 AI 助手”。为了实现这一目标,Astra 项目进行了一些重要的升级。谷歌一直在升级 Astra 的内存——我们去年看到的版本每次只能“记忆” 30 秒——并增加了计算机控制功能,使 Astra 现在可以执行更复杂的任务。
这款多模态、全视角的机器人并非真正的消费级产品,除了一小部分测试人员之外,短期内不会向任何人开放。Astra 代表着 Google 对未来人工智能如何为人类服务的最宏大、最狂野、最雄心勃勃的梦想。Google DeepMind 研究总监 Greg Wayne 表示,他认为 Astra 是“通用人工智能助手的概念车”。
最终,Astra 中可用的功能会移植到 Gemini 和其他应用中。这其中已经包含了团队在语音输出、内存以及一些基本的计算机使用功能方面的工作。随着这些功能逐渐成为主流,Astra 团队找到了新的工作方向。
Project Aura 智能眼镜又回来了
再来看看硬件方面。谷歌智能眼镜时代似乎又回来了。今天,谷歌和 Xreal 在大会上宣布建立战略合作伙伴关系,共同开发一款名为 Project Aura 的全新 Android XR 设备。
这是自去年 12 月 Android XR 平台发布以来,官方正式推出的第二款设备。第一款是 三星的 Project Moohan,但这是一款更类似于 Apple Vision Pro 的 XR 头显。而 Project Aura 则与 Xreal 的其他产品保持着密切联系。技术上准确的术语应该是“光学透视 XR”设备。更通俗地说,它是一副沉浸式智能眼镜。

Xreal 的眼镜,比如 Xreal One,就像在一副普通的太阳镜里嵌入了两台迷你电视,看起来略显笨重。Xreal 之前的眼镜可以连接手机或笔记本电脑,查看屏幕上的内容,无论是正在播放的节目,还是想在飞机上编辑的机密文件。它的优点在于,用户可以调整不透明度来查看(或遮挡)周围的世界。Project Aura 也秉持着同样的理念。
但谷歌并没有在发布会上透露出更多关于这款硬件的信息。Xreal 发言人 Ralph Jodice 表示,将在下个月的增强现实世界博览会上放出更多信息。一些已知的信息显示,它将内置 Gemini,并拥有更大的视野。在产品渲染图中,我们可以看到铰链和鼻梁架上的摄像头,以及镜腿上的麦克风和按钮。
这暗示着与 Xreal 现有设备相比,硬件将迎来升级。Project Aura 将搭载针对 XR 优化的高通芯片组。与 Project Moohan 一样,Project Aura 也希望开发者现在就开始构建应用程序和用例,以便在实际消费产品发布之前完成。说到这一点,谷歌和 Xreal 在一份新闻稿中表示,为头显开发的 Android XR 应用程序可以轻松移植到像 Project Aura 这样的其他设备。
有趣的是,谷歌对下一个智能眼镜时代的策略与其最初推出 Wear OS 时类似——谷歌提供平台,第三方负责硬件。虽然细节很少,但这将是在 Android XR 平台上推出的第二款官方设备。
