

集微网报道 北京时间6月12日凌晨,AMD在美国圣何塞举办的“AI Advancing 2025”大会上,重磅发布Instinct MI350系列GPU新品,凭借强大的AI训练和推理能力,成为面向AI和高性能计算领域,业界最高性能的GPU产品。

与此同时,AMD还剧透了一系列即将于明年发布的产品,其中包括计算性能提升10倍,被行业视为“Game Changer”的MI400系列GPU,以及为AI而优化,并集成新一代的Instinct GPU MI400系列、第六代EPYC CPU以及新一代的Pensando Vulcano网卡的“Helios”机柜解决方案。

得益于核心业务的强劲表现以及数据中心和人工智能领域的扩张。5月,AMD刚刚发布了强劲的季报,营收74亿美元,同比增长36%,营收连续四个季度同比增长。其中受到EPYC CPU和Instinct GPU销售增长推动,一季度AMD数据中心业务收入37亿美元,同比大涨57%,数据中心AI收入同比增长两位数。

凭借强大的创新能力以及坚定的路线图执行力,AMD正努力把握AI时代的机遇,加速前行。
“人工智能的未来不会由任何一家公司创造,也不会存在封闭的生态中,它将由开放合作塑造。”AMD董事会主席兼首席执行官苏姿丰(Lisa Su)博士强调。
三方面战略聚焦AI 推理市场复合增速超80%
近年来,AI的快速发展远超所有人的预期。苏姿丰博士坦言她的职业生涯中,还没有哪一项技术能够像AI一样具有如此快速的创新步伐。
苏姿丰博士表示,当前随着大模型在各个领域加速部署,AI已经进入下一阶段。训练是模型开发的基础,而真正带来改变的是对推理需求的显著增加。展望未来几年,数十万甚至数百万的模型将会出现,而针对特定任务以及行业的模型将加速部署。

苏姿丰博士指出,在AI加速的背景下,AMD预计从2023年到2028年,数据中心市场规模将达到5000亿美元,年复合增速超过60%,其中推理将成为最大的驱动力量,年复合增速超过80%。

另一个趋势是,AI正在超越数据中心范畴,从边缘向更广泛的终端延伸,因此没有一种架构能够通吃所有的负载类型,而是要针对场景和负载选择合适的计算架构。

苏姿丰博士介绍,AMD的AI战略聚焦在三方面。一是打造领先的计算引擎,将正确的模型、场景和计算引擎相匹配。

二是大力投入AI,过去几年AMD围绕AI进行了超过25笔投资。三是提供全栈的AI解决方案。

自2023年推出MI300系列以来,Instinct GPU系列保持每年已更新的节奏持续快速迭代,通过持续的工艺、架构等方面的创新,显著提升产品的性能和能效,并持续拓展市场规模。
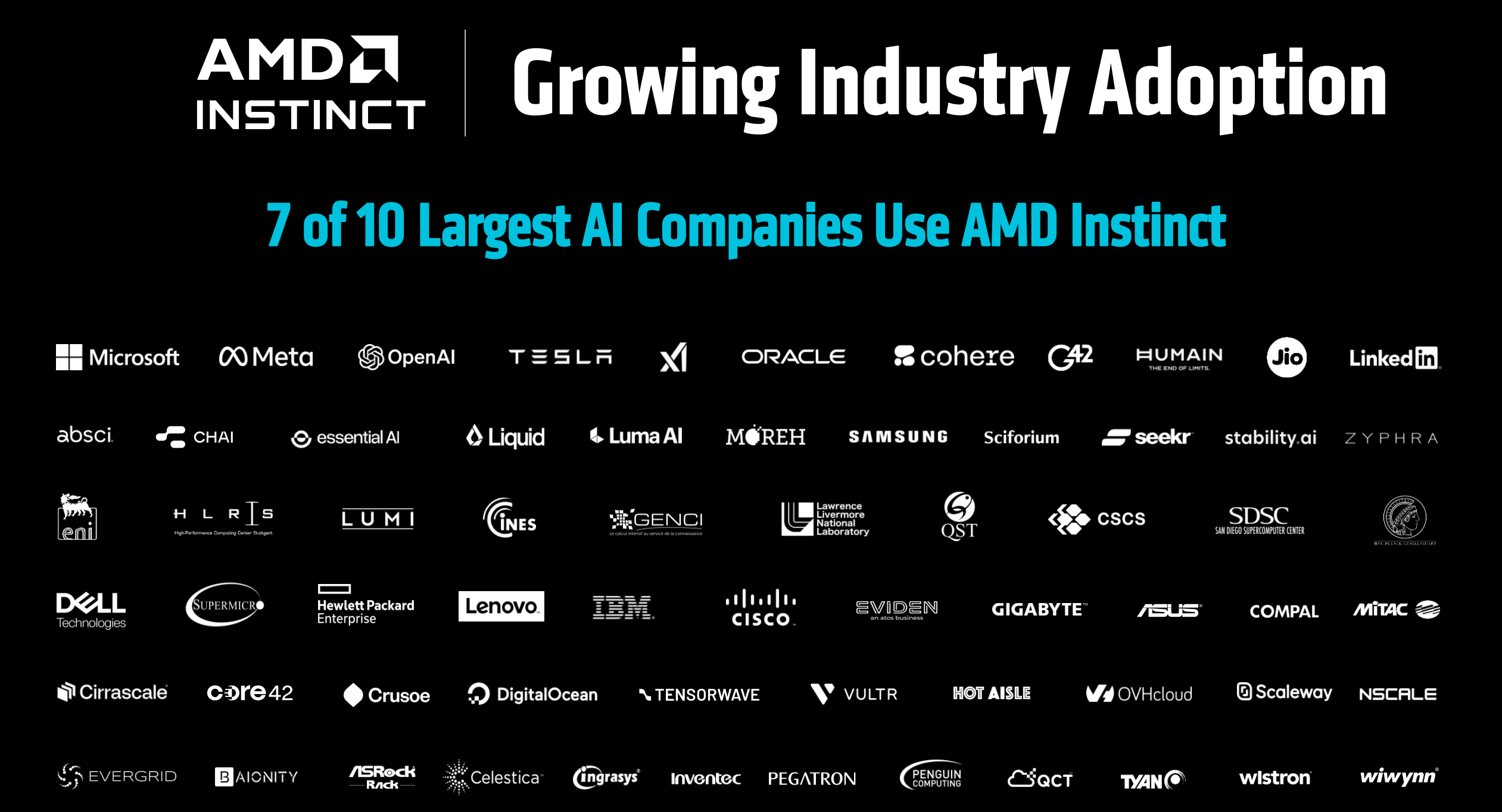
当前,全球10家顶级AI公司中有7家在规模部署Instinct系列。而最新一期全球超级计算机Top500榜单中,排名前两位的超级计算机,均采用AMD的Instinct GPU和EPYC CPU解决方案。
目前,已经有超过35家厂商采用MI300系列平台。这表明AMD在高性能计算领域的行业领导力正在显著提升。
Instinct MI350系列:推理能力提升3倍 加冕AI新王
此次推出的MI350系列GPU包括MI350X GPU和MI355X GPU,采用CDNA4架构,3nm工艺制程,具有1850亿晶体管,支持FP4和FP6的全新生成式AI数据类型,采用业界领先的HBM3E存储方案。不同之处在于MI355X系统功率较高从而提供更高性能,主要针对液冷,MI350X提供风冷及液冷两种配置,从而支持广泛的数据中心部署。

MI350系列产品具有更加快速的AI训练和推理能力,4位和6位浮点精度下能够实现20PFLOPS(每秒千万亿)的算力。
MI350采用288GB的HBM3E,能够实现一颗GPU支持最高5200亿参数的AI大模型。
MI350系列采用符合行业标准的GPU计算节点UBB8的通用基板设计,便于在现有的数据中心进行快速的AI基础设施部署,提供风冷和直接液冷两个版本,适用于不同散热需求的数据中心或AI计算集群部署。
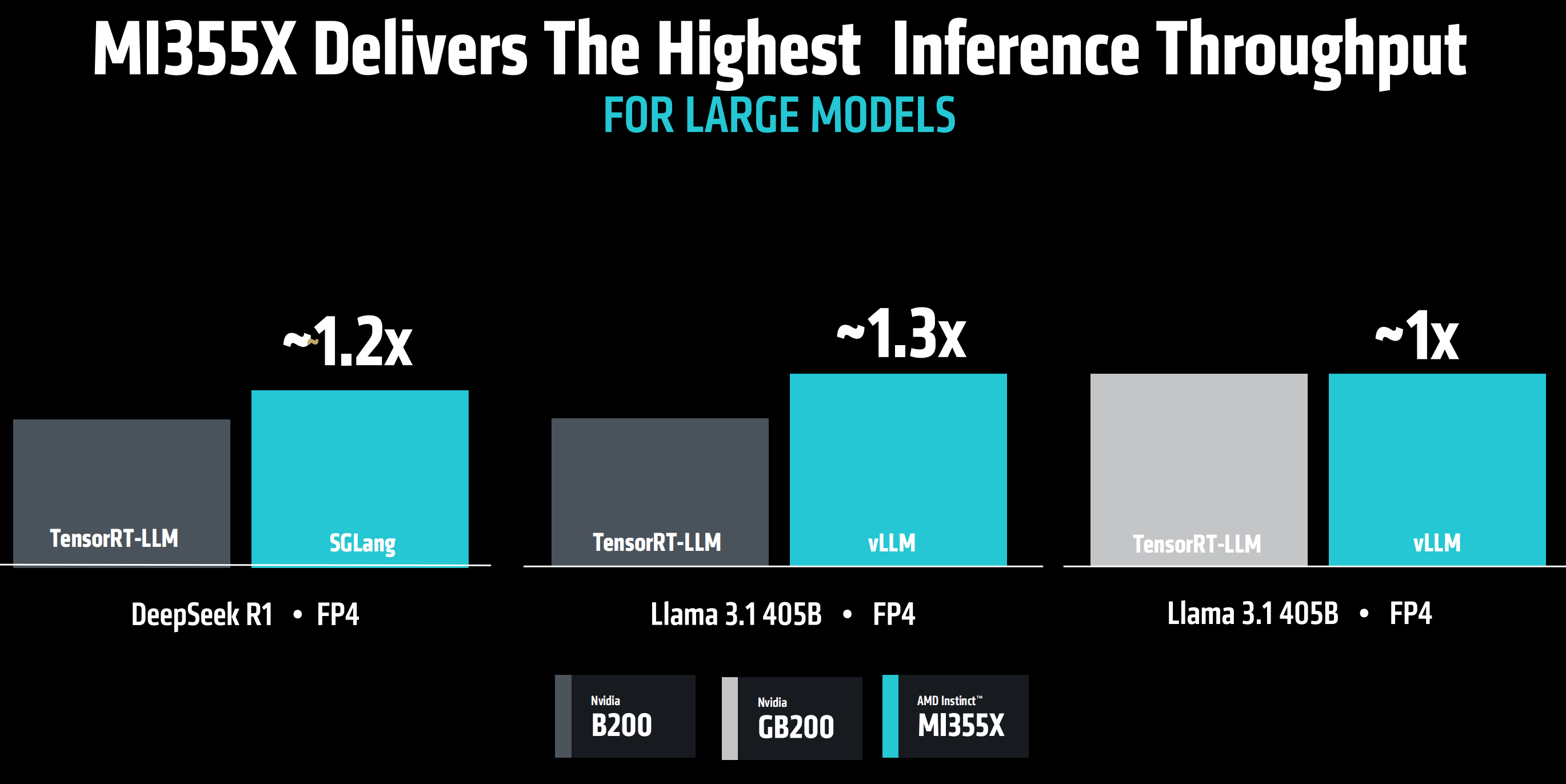
在同NVIDIA包括GB200以及B200在内的顶级GPU的对比中,MI355X成为面向AI和高性能计算领域的业界最高性能的GPU产品。

在如AI智能体,内容生成等推理应用性能表现方面,MI355X相比上一代MI300X产品,推理能力平均提升3倍。
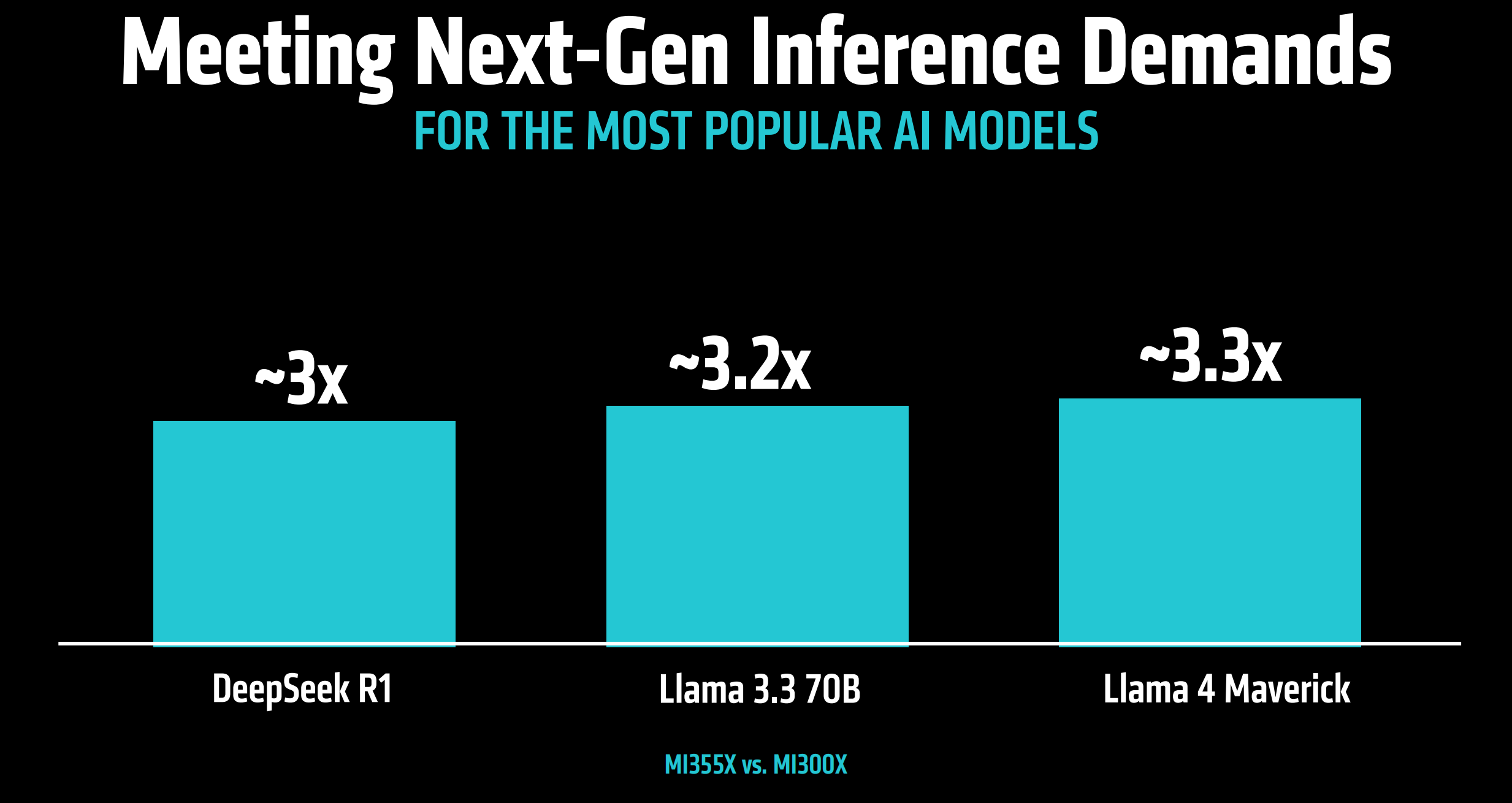
面向下一代推理需求,比如针对Deepseek R1、Llama 3.3 70B以及Llama 4 Maverick等当下主流AI模型,MI355X相比于MI300X,推理能力提升3倍以上。

同英伟达的B200、GB200竞品相比,MI355X对于主流大模型的推理能力也领先1倍以上。

同时,相比于B200,使用MI355X能够带来显著的性能成本优势,相同成本下,能够处理的Token数量提升40%。
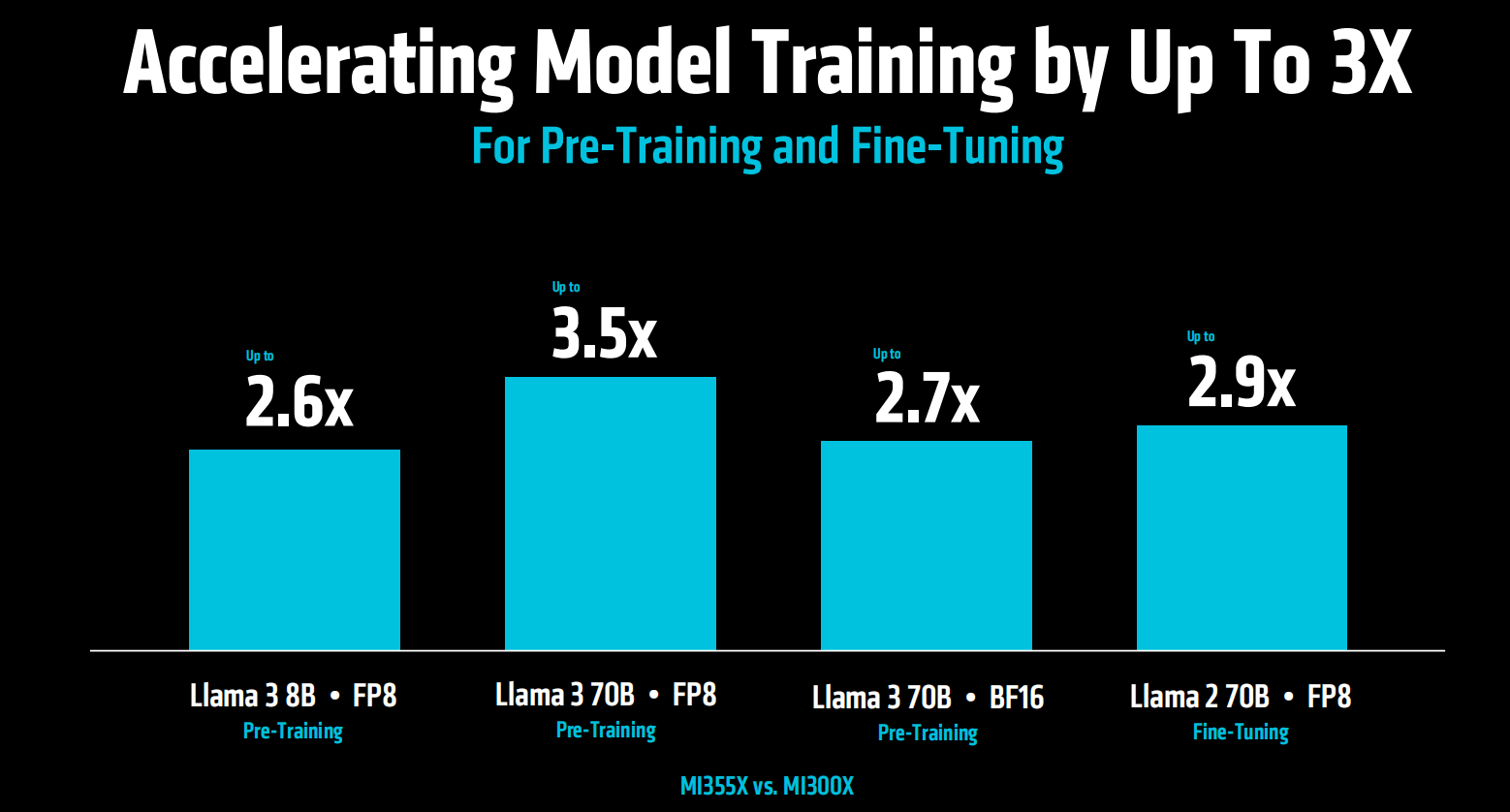
面向预训练和微调,MI355X对比MI300X能够实现模型训练的3倍加速。

相较于竞品GB200和B200,MI355X在训练性能方面也有1倍以上的提升。

MI350系列的服务器机架解决方案在硬件和软件层面均遵循开放标准,包括第五代EPYC CPU以及AMD Pollara NIC。基于风冷的MI350机架解决方案,单机架可以支持最多64个GPU,从而支持更传统的数据中心部署。
此前,AMD提出2020-2025年,将用于AI训练和高性能计算的AMD处理器和加速器的能效提高30倍,Instinct MI350将这一能效提升至35倍,超额完成任务。
此外,AMD还提出了新的五年目标,即到2030年,将机架规模能效提升20倍,意味着五年后,一个通常需要275个机架来训练的典型AI模型,可以在不到一个机架中完成训练,同时电耗降低95%。

据介绍,目前MI350系列解决方案正在向客户出货,预计第一波服务器合作伙伴相关产品以及CSP厂商的相关用例将于今年Q3推出。
强化软件生态:ROCm7正式发布 支持UALInk1.0

在保持硬件领先性能的基础之上,近年来,AMD持续发力软件生态建设,软件生态也被视为AMD在AI领域实现真正破局的关键。
此次会上,AMD发布了最新的开发工具ROCm 7,旨在通过大幅提升性能、分布式推理、企业解决方案以及在Radeon和Windows上的更广泛支持,与开源社区携手共同驱动AI行业进一步发展。

与ROCm 6相比,ROCm 7的推理能力提升超过3.5倍,训练能力提升3倍。

同时,AMD为开发者提供了开发者云服务,它允许开发者即时、无硬件限制地访问最新发布的Instinct MI350系列GPU,配备预配置环境和免费试用额度,帮助开发者们实现无缝AI开发和部署。
此外,今年4月,汇聚AMD、亚马逊AWS、谷歌、英特尔、Meta、微软等大量科技企业的UALink联盟正式发布了1.0版本的UALink 200G加速器高速互联规范,旨在挑战英伟达NVLink技术在GPU加速器大规模并行互联方面的领导地位。此次大会上,AMD宣布支持最新的UALInk1.0规范。
发布会上,苏姿丰博士特别强调,人工智能的未来不会由任何一家公司创造,也不会存在封闭的生态中,它将由开放合作塑造。
2026四大看点值得期待 MI400将迎史诗级飞跃
此次大会上,AMD还进行了对于未来即将推出的一系列创新产品的预告。
一是将于2026年发布的AI基础设施解决方案,集成了第六代 EPYC CPU VENICE,Instinct MI400系列GPU,以及Pensando VULCANO加速器。


二是20206年将会推出优化的AI机架解决方案“Helios”,采用统一架构,专为前沿的模型训练设计,提供领先的计算密度,内存,带宽和可扩展规模。相较于英伟达下一代集成AI GPU Vera和CPU Rubin的Oberon机架架构,Helios在扩展带宽、存储带宽等性能指标方面实现1-1.5倍的提升。

三是宣布2026年推出AI计算性能大跃进的Instinct MI400系列GPU,包括FP4/FP8精度下40PF/20PF的算力,432GB的HBM4,19.6TB/内存带宽,单GPU横向拓展带宽300GB/s。
四是宣布2027年采用新一代EPYC VERANO CPU、Instinct MI500系列GPU、PENSANDO VULCANO加速器的未来AI机柜。同样保持一年一更新的节奏。
十大伙伴站台奥特曼压轴 AI行业影响力彰显
此次发布会上,来自openAI、Meta、xAI、HUMAIN、微软、红帽等众多重量级合作伙伴登台分享了他们如何使用AMD AI解决方案来训练当前领先的AI模型,为大规模推理提供动力,并加速AI探索和开发。
据笔者观察,这也是近年来“AI Advancing” 大会中客户站台数量最多的一次。反映出AMD的行业影响力和号召力的同时,也表明其领先的AI解决方案正在被行业广泛认可和接受。

Meta详细介绍了Instinct MI300X在LLama 3和Llama 4推理中的广泛应用。介绍了MI350在计算能力、性能/TCO方面的表现。Meta表示,未来将继续与AMD在AI路线图上紧密合作,包括将在未来部署Instinct MI400。

甲骨文云基础设施是首批采用搭载Instinct 355X GPU开放式机柜的厂商,宣布将采用最新AMD Instinct处理器加速的zettascale AI集群,该集群最多配置131072个MI355X GPU,帮助客户大规模构建、训练和推理AI。

日前,AMD与沙特人工智能公司Humain达成100亿美元的重磅战略合作。HUMAIN相关代表在此次会议上介绍了合作的相关内容,包括利用AMD提供的全方位计算平台,构建开放、可扩展、有弹性和成本效益的AI基础设施等。

微软宣布Instinct MI300X已在Azure上为专有和开源模型提供支持。

Cohere分享了其高性能、可扩展的Command模型部署在Instinct MI300X上的实践,以高吞吐量、效率和数据隐私为企业级LLM推理提供动力。
红帽介绍了其与AMD扩大合作如何实现AI环境,通过红帽OpenShift AI上的Instinct GPU,在混合云环境中提供强大、高效的AI处理。

Astera Labs强调了开放的UALink生态系统如何加速创新,并为客户提供更大的价值,同时分享了提供全面的UALink产品组合以支持下一代AI基础设施的计划。

Marvell分享了采用UALink规范的交换机产品的技术路线图,作为UALink联盟的成员,双方将共同开发开放式互连规范,为AI 基础设施带来极致灵活性。

OpenAI的CEO山姆奥特曼同苏姿丰博士讨论了整体优化的硬件、软件和算法的重要性,以及 OpenAI与AMD在AI 基础设施方面的密切合作,包括在MI300X 上生产的Azure上的研究和GPT模型,以及在 MI400 系列平台上的深度合作。
“当我第一次听到芯片的一些规格时,我心想这不可能,听起来太疯狂了。这将是一件了不起的事情。” 奥特曼表示。
