


这两天,字节又出手了,一口气放出一堆大货。
豆包大模型1.6、豆包·视频生成模型 Seedance 1.0 pro、豆包·语音播客模型,豆包·实时语音模型...全家桶式上新,看着热闹。
如果你只是扫一眼上述产品,可能觉得就是大厂又来了一波例行升级,没什么特别的。现在AI圈更新节奏这么快,新模型、版本号、榜单名次一大堆,确实不太容易提起兴趣。
但稍微往下看一看,会发现这次字节的做法不太一样。它并没有靠一两个参数或者演示视频来抢风头,而是开始把模型能力做成一整套“能直接跑起来”的应用,从文字、图像、视频,到语音、操作系统,全都串在了一起,而且不少是直接挂进了豆包APP、火山方舟这些已经在用的产品里。
我们就从两个核心产品说起。
Seedance 1.0 Pro 实测表现:
稳定、成型,但仍有边界
如果只看热度,这几个产品中Seedance应该是被关注度最高的了。
它刚上线就登上了第三方榜单Artificial Analysis的文生视频和图生视频两项第一,超过了可灵2.0和谷歌的Veo 3。榜单怎么评的我们可以再讨论,但至少说明在业内标准下,Seedance的生成效果已经达到了主流模型中的较好水平。
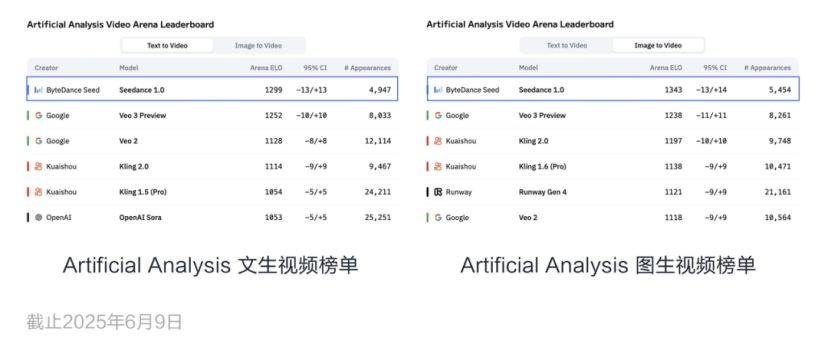
我们来看下这个模型的基本情况。
Seedance 1.0 Pro支持文字和图片输入,能生成10秒左右的1080p视频,支持2-3个镜头切换。它的主要特点,是强调镜头之间的连贯性和内容的稳定性。
这点在之前的视频生成模型里,确实是个短板。很多模型虽然能出图像,但内容连不起来,主角突然消失或者背景抖动都很常见。
Seedance解决这个问题的方式,是把每个镜头的内容用文字描述得更细,官方叫「精准描述模型」。它先生成一段描述,然后再根据这个描述训练视频。这种方式能让模型更好地知道该生成什么内容,也更容易控制住动作和细节。
Seedance能生成的视频风格也比较多样,可以支持航拍、第一人称、动画、水墨等多种风格。这点其实各家模型都有类似能力,只是Seedance在这方面的完成度和一致性更高一些。
生成速度方面,5秒的1080p视频只需大约40秒,这个速度属于目前行业中等偏上的水平。
来看一下我们实测的成果(每个维度我们都测试了多个case,篇幅限制只展示其中的一个):
镜头语言
