

谷歌最新71页论文震惊科研界:AI不止能写代码,还能像科学家一样提出新方法、跑实验,甚至在六大领域全面超越专家!过去要花几个月的探索,如今几小时就能完成,科研节奏正在被AI改写。
一图看透全球大模型!新智元十周年钜献,2025 ASI前沿趋势报告37页首发
在最新一篇长达71页的论文里,谷歌给科研界丢下了一颗重磅炸弹。
过去一年,DeepMind的FunSearch已经展示了AI在数学发现中的潜力,MIT等团队也提出了AI co-scientist的概念。
但与这些探索相比,谷歌这次的系统走得更远:它不仅能提出新方法、验证实验结果,还在多个领域超越了顶尖专家。

论文地址:https://arxiv.org/abs/2509.06503
和传统代码只追求正确性不同,实证软件的目标只有一个:让科研任务的指标分数尽可能高。
这意味着,AI已经开始介入科学研究的最核心环节——假设验证与方法创新。
不止是写代码,而是科研「实证软件」
在科研中,最耗时的环节并不是提出想法,而是如何验证。
科学家们往往要为一个问题编写和调试大量实验代码,尝试几十甚至上百种模型和参数组合,这个过程动辄数月。
谷歌的新系统把这一环节彻底加速,他们提出了一个概念:实证软件。
与常规软件通常只以功能正确性作为评判标准不同,实证软件的首要目标是最大化预设的质量评分。
也就是说,科研问题被重新抽象为一种可计分任务(scorable task)。
任务中包含清晰的问题描述、衡量优劣的指标和数据集,AI要做的,就是直接朝着分数最高的方向不断优化。
在这一机制下,AI的角色已经不再是一个写代码的小助手,而更像是一个高速运转的实验员。
它会先生成研究思路并写出可执行的代码,然后在沙箱环境中运行,利用树搜索的方法筛选出值得深入的候选方案,再让大语言模型对代码进行反复的改写和优化。
整个过程循环往复,直到找到最优解。
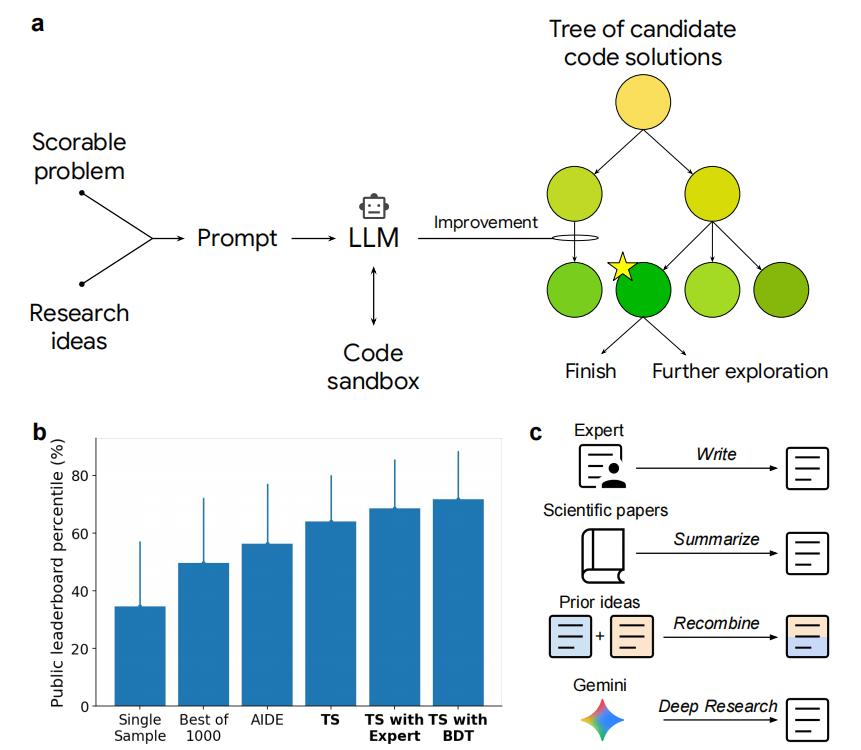
AI科研系统的工作流程:科研问题被转化为可计分任务,经由大语言模型生成代码,并通过树搜索反复迭代优化,最终获得最佳方案。
研究员也强调:
其输出作为代码化的解决方案,可验证、可解释且可复现。
换句话说,这不是简单的一段程序,而是真正符合科研标准的成果。
六大领域的硬核成绩单
谷歌这套系统真正惊艳的地方,是它在六个完全不同的科学领域里,都拿出了堪比专家的成果。
基因组学:比专家强14%
在单细胞RNA测序(scRNA-seq)数据的批次整合问题上,谷歌的系统展现了真正的科研创新力。
这类任务的难点在于,不同实验批次之间会产生复杂的技术偏差,如何在消除这些偏差的同时保留真实的生物学信号,一直是领域里的核心挑战。
研究人员并没有只让系统从零开始,而是把现有方法的文字说明直接输入给它。
比如BBKNN,这是一种常见的批次校正方法,核心思路是:在每个批次内部为细胞寻找最近邻居,再把这些邻居集合合并,得到一个批次校正后的整体图。

BBKNN 的方法描述示例。研究人员将其输入系统,AI 在此基础上进行改写和优化
在这样的基础上,AI能够生成新的变体并进行组合。
最终,它把BBKNN和另一种方法ComBat拼接在一起,得到一个完全新颖的解法。
结果显示,在OpenProblems V2.0.0的综合指标上,比最佳人工方法提升了14%。
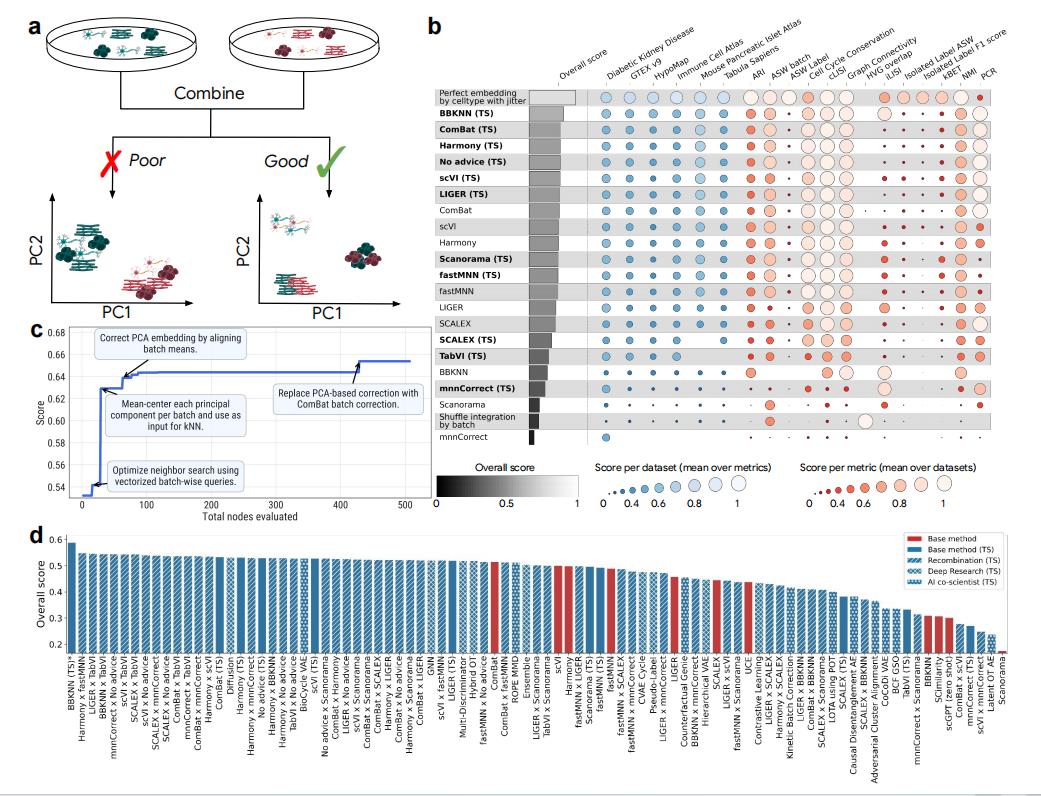
在单细胞RNA测序批次整合任务上,AI系统自动组合方法,整体得分超过现有专家工具
公共健康:超过CDC官方模型
美国在疫情期间,CDC的CovidHub Ensemble被视为预测住院人数的「黄金标准」。
而谷歌的系统自动生成的14个模型,集体表现超过了官方Ensemble。
AI在新冠住院预测任务中的表现,整体优于CDC官方的CovidHub Ensemble
地理遥感:分割精度破 0.80
在高分辨率遥感图像分割任务中,系统生成的三种模型全部超过现有方法,分割精度(mIoU)突破0.80。
更重要的是,它利用U-Net、SegFormer等架构,并结合图像增强手段,说明它不仅在「复制」,也在「改造和优化」。

AI系统生成的分割结果(下排),与人工标注结果(中排)高度接近,明显优于传统模型
神经科学:全脑7万神经元预测
在Zebrafish全脑神经活动预测中,AI系统不仅打败了所有现有基线,还设计出能结合生物物理模拟器的混合模型。
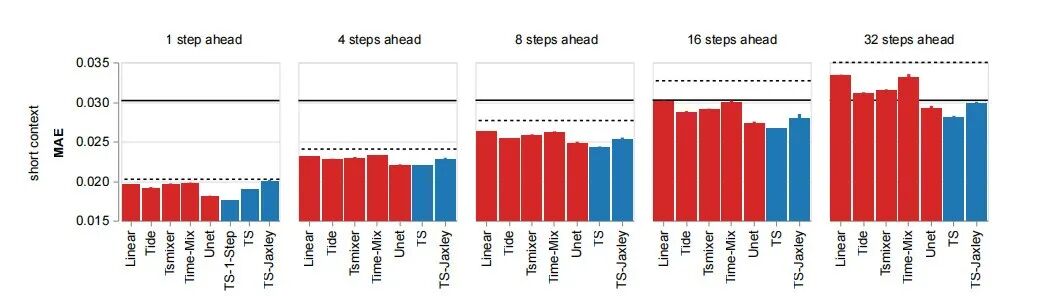
在斑马鱼全脑神经活动预测中,AI系统生成的模型(蓝色)整体误差更低,全面超越现有基线方法(红色),其中TS-Jaxley更是将生物物理模拟器融入预测,提升了可解释性
数学:难积分迎刃而解
数学问题一向是最能考验算法极限的地方。
谷歌的系统被拿来挑战19个异常棘手的积分任务,结果出乎意料:标准数值方法几乎全军覆没,而AI系统却成功算出了其中17个。

数值积分任务的部分示例。谷歌系统在19个测试积分中成功求解了17个,而标准数值方法未能给出结果。
这说明,它并不只是停留在表面,而是真正学会了如何在复杂数学场景中找到突破口。
对科研人员来说,这意味着在长期困扰的数值计算上,AI已经能给出可用的答案。
时间序列:零起步构建通用预测库
在通用时间序列预测的GIFT-Eval基准上,谷歌的系统完成了一件几乎不可能的事:
从零开始,只靠一段代码不断爬坡优化,硬是炼成了一个能覆盖28个数据集、跨越7个领域、适配从秒到年的10种频率的通用预测库。
这意味着,AI不仅能解具体问题,还能自己总结出一套通用方法——科研里最难啃的「跨领域泛化」,它也啃下来了。
科研范式的转折:AI能创新,也能跨界
如果说前面的六个案例只是成绩单,那么它们背后真正震撼的是:AI已经不满足于模仿,而是在科研中展现出了创新能力与跨学科的通用性。
在基因组学任务中,它能够自动把两个不同的专家方法组合起来,得到比人类更优的解;
在神经科学任务里,它甚至首次把生物物理模拟器和深度模型拼接,开辟出一种全新的混合思路。
类似的尝试在学界和业界已有先例:比如DeepResearchGym提供了评测框架,OpenProblems.bio社区建立了scRNA-seq的公开基准。
但谷歌的系统首次在这些基准上全面跑通pipeline,给出了可量化、可复现的专家级结果。
这种创新并不是单点突破,而是跨学科的普遍现象。
从基因组学到公共健康,从遥感影像到时间序列预测,系统都能快速适配,找到新的路径。
这些基准的多样性使我们能够综合评估其在零样本泛化、高维信号处理、不确定性量化、复杂数据语义解释和系统层面建模等方面的能力。
过去科学家依靠反复试验推进,如今AI系统也能以相同方式进行大规模试错,而且速度提升数百倍——把几个月的探索压缩到几小时。
这意味着科研节奏可能迎来真正的「指数级加速」。
当AI走进实验室,人类该做什么?
AI已经能在多个前沿领域生成新方法、验证结果、超越专家,人类科学家的角色也正在被重新定义。
在这套系统里,AI负责的是不知疲倦的实验与探索:
成千上万种方案的尝试、优化和筛选,本来需要几个月甚至更久,如今压缩到几小时或几天。
我们的系统能够快速生成专家级别的解决方案,将一组想法的探索时间从数月缩短到数小时或数天。
而科学家的职责,正逐渐转向提出方向、判断价值、定义优先级。
AI可以在技术路径上无限拓展,但科研问题本身的意义、背后的社会价值,仍然需要人类去设定和把握。
这意味着,科研分工正在走向一种新的格局:
AI或许会成为高效实验员和方法发明者,人类则站在更高的维度上进行选择与决策。
这意味着,谷歌的系统不再只是一个「研究工具」的实验,而是迈向了和FunSearch、AI co-scientist等项目同一赛道的下一步——
从单点突破走向跨领域的科研合作者。
值得一提的是,谷歌已经将这套系统产出的最佳方案全部开源,并提供交互界面让研究人员追踪整个搜索与突破过程。
这种开放姿态,意味着科研界可以直接在真实任务里验证、扩展这些AI生成解法。
参考资料:
https://arxiv.org/abs/2509.06503
https://research.google/blog/accelerating-scientific-discovery-with-ai-powered-empirical-software/
