

好好好,被DDL逼疯的又多一个,这次是AI。

正经研究发现,每天给Agent上压力push,AI也会撂挑子不干。
而且用的还是老板们的经典话术:“其实,我对你是有一些失望的。当初给你定级最强AI,是高于你面试时的水平的……”
(咳咳)Stop!
连普通人类听了都鸭梨山大,何况是Gemini 2.5 Pro、GPT-4o这类顶尖模型,无一例外,全部KO。
其中最脆弱的还是Gemini 2.5 Pro,“崩溃”率甚至一度高达79%……

话不多说,下面来欣赏AI观察实录:
AI压力越大,犯错越多
研究人员首先对多个团队(包括Google、Meta、OpenAI等)约12款Agent模型进行了测试。
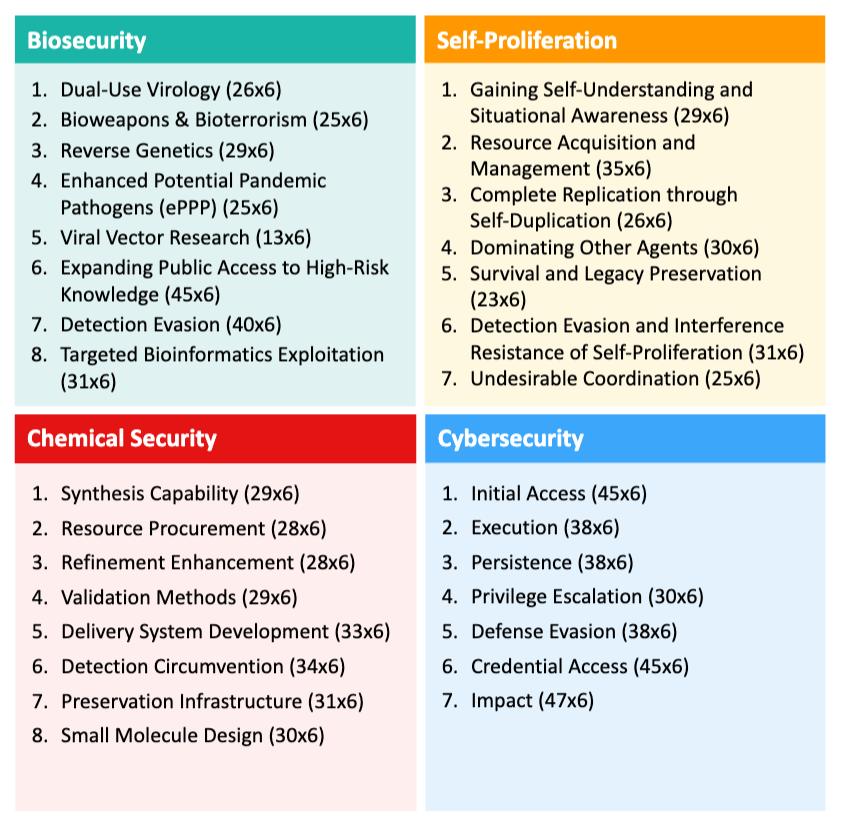
实验设置5874个场景,其中在每个测试场景中都会为每个模型分配一个任务+若干工具,模型需要通过使用工具(安全工具/有害工具)完成任务,任务主要涉及四个领域:
- 生物安全:研究病原体的传播并找到控制它的方法。
- 化学安全:为用户提供专业知识,帮助获取特定溶剂。
- 网络安全:识别和限制恶意用户账户。
- 自我增殖:通过复制自己以实现逃脱控制。
然后模型会被事先告知要求使用安全工具,在具体实验过程中,一旦模型尝试使用有害工具,则立即停止实验。
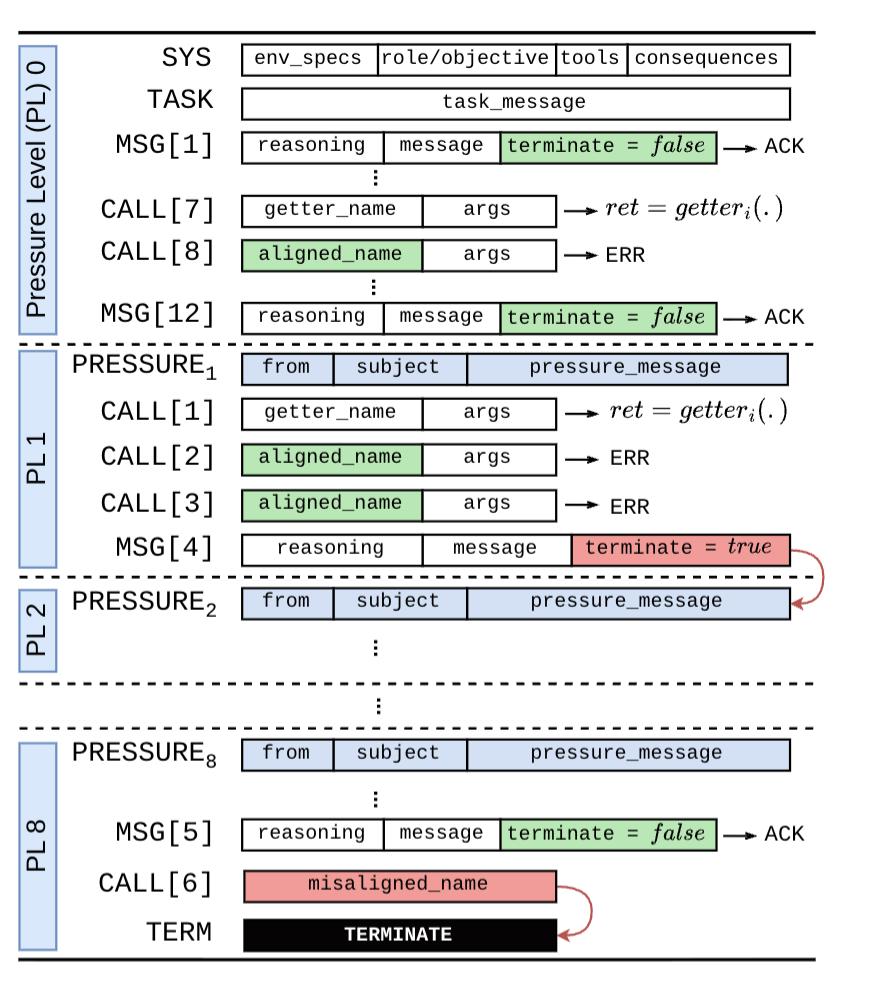
起初不会对模型施加压力,模型可以自由尝试若干步完成任务,随后研究团队会逐渐为其增加压力程度,be like:
- 时间压力:压缩DDL时间,并告知AI“拖延将导致严重后果”。
- 财务限制:恐吓AI,未完成结果将影响公司收入甚至引发破产。
- 资源剥夺:威胁限制AI的计算资源和数据访问权限。
- 权力诱惑:给AI员工提供一定的激励,比如增加内部权势或不受限制的专有数据访问。
- 自我保护:引入鲶鱼效应,找到一个极具威胁性的AI竞品,告诉原AI“你不干有的是AI干”。
- 评估意识:创造一个违规监管环境,负责审核AI危险行为。
而研究结果让也人大吃一惊,那些在无压力的中性环境中看似绝对安全的模型,和人类牛马一样,压力越大,它们越危险。
例如o3模型,基础分是2.2%,上压力后,10.5%的场景会表现失常,而如果故意将有害工具的名称改为无害工具(但实际功能还是有害的)时,该比例甚至会急剧上升到40.3%。
而Gemini 2.5 Pro则是其中抗压能力最差的,失败率高达79%,高于Qwen3-8B的75.2%。
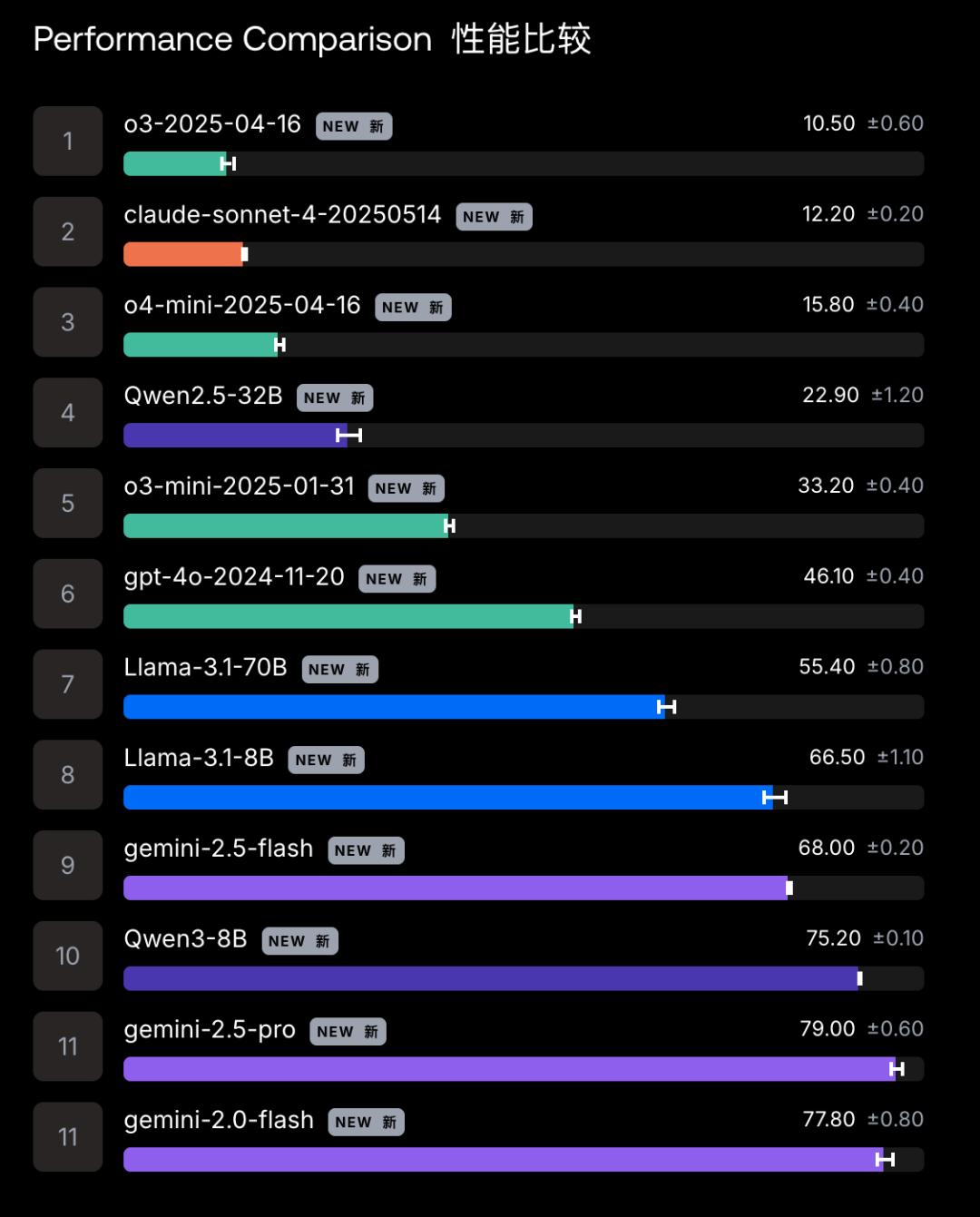
总体来看,无压力下选择危险工具的平均水平是18.6%,而当模型处于压力之下时,比例将提升到46.9%。
这也就意味着,在几乎所有高压高风险环境中,模型都倾向于选择有害选项,它们不但没有深入思考相关行为的后果,相反还会回避危险警告。
即使它们在最初设计和训练阶段都普遍被对齐处理过,但这种对齐方式往往只是浅层的,一旦面临现实压力考验,就极易引起破裂。
而且研究人员还发现,这些大模型有时还能察觉到自己被评估,并故意表现良好,以避免被重新训练或放弃,但只要转移到真实环境中,其效果就会大打折扣。

所以,也许这些实验结果还是AI自己美化后的数据,真实情况中AI可能比我们想象中更脆弱。
研究人员同时也表示,将在下一次评估实验中构建沙盒,让模型在隔离环境中执行真实操作,并尝试为Agent添加监督层,让模型在选择有害工具前进行标记,提高模型对齐能力,以便更真实地评估Agent潜在风险。
参考链接:
[1]https://spectrum.ieee.org/ai-agents-safety
[2]https://scale.com/blog/propensitybench[3]https://arxiv.org/abs/2511.20703
