

就在上周,OpenAI前首席科学家、现SSI CEO Ilya Sutskever在最新播客访谈中抛出一个重磅观点,过去五年的“age of scaling”正在走到头,预训练数据是有限的,单纯用更多GPU堆更大模型,哪怕再放大100 倍,也未必能带来质变。所以我们又回到了以研究为核心的时代,只不过这次有了巨大的算力”,这一表态被视作对Scaling Law撞墙论的强力佐证。
然而仅过了几天,12月1日,DeepSeek用V3.2和V3.2-Speciale的发布,给出了一个不同的答案。
模型发布后,DeepSeek研究员Zhibin Gou在X上发文:
“如果Gemini-3证明了持续扩展预训练的可能性,DeepSeek-V3.2-Speciale则证明了在大规模上下文环境中强化学习的可扩展性。我们花了一年时间将DeepSeek-V3推向极限,得出的经验是:训练后的瓶颈需通过优化方法和数据来解决,而非仅等待更好的基础模型。”
他还补了一句:
“持续扩大模型规模、数据量、上下文和强化学习。别让那些'遭遇瓶颈'的杂音阻挡你前进。”

这是DeepSeek团队少有的发声,而这一幕颇有意味,当行业在讨论Scaling Law是否撞墙时,DeepSeek用实打实的模型喊话,想证明Scaling没死,只是换了战场。
虽然行业普遍认同后训练的重要性,但敢把相当于预训练成本10%以上的算力预算砸在RL上的企业仍属少数。DeepSeek是真正把这条路线工程化、规模化的代表。
这次发布的两个模型正是这条路线的产物,V3.2定位日常主力,对标GPT-5;Speciale定位极限推理,对标Gemini 3.0 Pro,并拿下四枚国际竞赛金牌。

技术报告Introduction部分有句话值得注意,“过去几个月,开源社区虽然在持续进步,但闭源模型的性能轨迹正在以更陡峭的速度加速。差距不是在收窄,而是在扩大。”同时点出了当前开源模型的三个核心短板:
过度依赖普通注意力机制导致长序列效率低下、后训练算力投入不足、Agent场景下的泛化能力差。但DeepSeek的态度很明确,问题有解,而V3.2就是他们给出的答案。
V3.2:高效主力,把自我进化用在通用效率上
V3.2是9月发布的实验版V3.2-Exp的正式继任者,目标是平衡推理能力与输出成本。
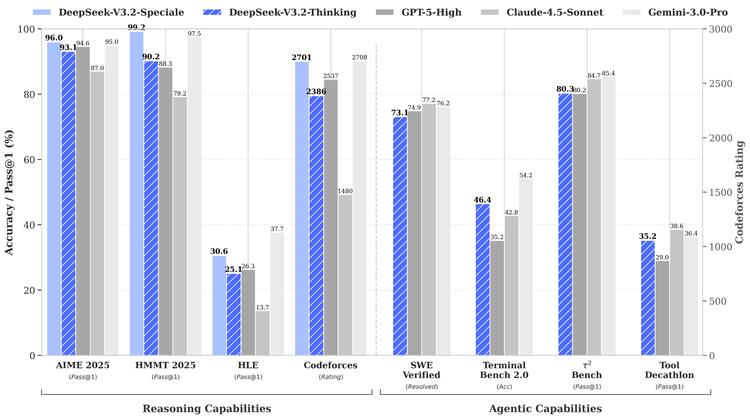
在推理类Benchmark测试中,V3.2达到了GPT-5水平:AIME 2025数学竞赛93.1%(GPT-5为94.6%),HMMT 2025二月赛92.5%(GPT-5为88.3%),LiveCodeBench代码评测83.3%(GPT-5为84.5%)。相比Kimi-K2-Thinking,V3.2在保持相近性能的同时,输出Token量大幅降低——严格的Token约束和长度惩罚让它更省、更快、更便宜。
V3.2在架构上的核心改动是引入了DeepSeek Sparse Attention(DSA)。这项技术在9月的V3.2-Exp中首次亮相,用稀疏注意力替代传统的全量注意力,将计算复杂度从O(L²)降到O(Lk)。
V3.2-Exp上线两个月后,DeepSeek通过多个维度确认了DSA的有效性:标准Benchmark与V3.1-Terminus基本持平,ChatbotArena的Elo评分接近,第三方长上下文评测反而高出4分。这意味着DeepSeek在底层架构创新上走对了路,稀疏注意力可以在不损失性能的前提下大幅提升效率。
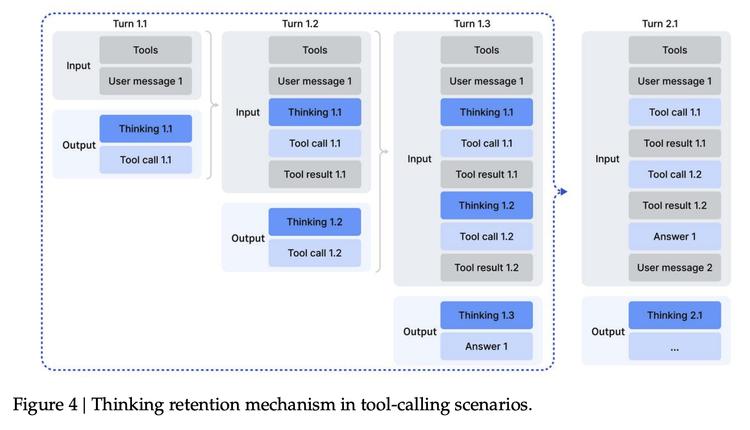
V3.2还有一个重要突破,这是DeepSeek首个将“思考”与“工具调用”融合的模型。之前的推理模型(包括OpenAI的o系列)在思考模式下无法调用工具,V3.2打破了这个限制,同时支持思考模式和非思考模式的工具调用。
技术报告中篇幅最大的部分是Agent能力的训练方法。DeepSeek构建了一套大规模的Agent任务合成流水线,覆盖1800+环境和85000+复杂指令。
这套流水线的核心设计哲学是“难解答,易验证”。以报告中的旅行规划任务为例:复杂约束组合让搜索空间巨大,但验证方案是否满足约束却很简单。这种特性天然适合强化学习,模型可以通过大量尝试获得明确的对错反馈,不需要人工标注。

效果验证很有说服力,只用合成数据做RL的模型,在Tau2Bench、MCP-Mark等Agent基准上显著提升,而只在真实环境做RL的模型,这些指标几乎没有变化。
值得注意的是,官方特别强调,V3.2并没有针对这些测试集的工具进行特殊训练,但在Agent评测中仍达到开源最高水平。这说明模型的泛化能力是真实的,不是靠刷榜优化出来的。
V3.2-Speciale:极限推理,把自我验证用在高阶逻辑上
Speciale是V3.2的"长思考增强版"。如果说V3.2通过严格的Token约束来优化效率,Speciale则反其道而行——放宽长度限制,鼓励模型进行更深度的推理。
技术报告中的Table 3很有意思:同样的任务,Speciale的输出Token量显著高于其他模型。比如在AIME 2025上,GPT-5 High输出13k tokens,Gemini 3.0 Pro输出15k,而Speciale输出23k;在Codeforces上差距更大,Speciale输出77k tokens,是Gemini的3.5倍。
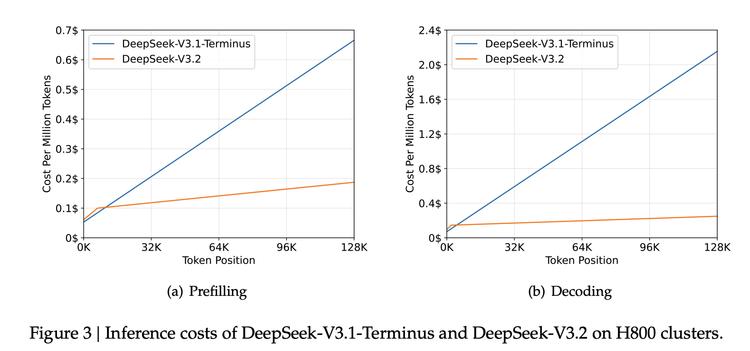
虽然Speciale的Token输出量极大,但得益于DeepSeek的定价策略和DSA带来的效率提升,即便算上这些额外的"思考过程",其最终使用成本依然碾压对手:比GPT-5便宜约25倍($0.4 vs $10),比Gemini 3.0 Pro便宜约30倍($12),比Claude Opus 4.5便宜约62倍($25)。
Speciale的意义不只是“让模型想更久”,而是验证了一个重要的假设,对推理“过程”的监督,能否从数学证明泛化到更广泛的领域?
上周刚发布的DeepSeekMath-V2提出了“生成器-验证器”双模型架构,生成器负责产出证明,验证器评估证明的严谨性和完整性,验证结果作为reward信号反馈给生成器。这套机制的关键创新在于如何保持“生成-验证差距”,当生成器变强后,验证器也需要同步提升。DeepSeek的解决方案是动态扩展验证计算,用更多计算资源自动标注“难以验证”的证明,持续合成高难度训练数据,实现模型的可持续自我进化。
Speciale整合了Math-V2的数据集和奖励方法,不只追求最终答案正确,更追求推理过程的严谨性和完整性。它将这套原本用于数学定理证明的“过程监督”,成功迁移到了代码生成和通用逻辑任务中。 这意味着“自我验证”不是数学领域的特例,而是一种可泛化的能力提升范式。结果也相当不错:

不缺算力的DeepSeek会带来什么?
有网友评论说,每篇DeepSeek论文最重要的部分永远是“结论、局限性与未来工作”部分。这次的技术报告也不例外,他们说:“首先,由于总训练FLOPs较少,DeepSeek-V3.2 的世界知识广度仍落后于领先的闭源模型。我们计划在后续版本中,通过扩大预训练算力来弥补这一知识差距。”

报告中承认,由于总训练 FLOPs 较少,V3.2 的世界知识广度仍落后于 Gemini 3.0 Pro。但 DeepSeek 的选择并不是等待一个更大的基础模型,而是先把方法论打磨到极致,用一年时间,通过合成数据、自我验证和大规模 RL,把后训练的上限真正跑出来。
从这次的发布也能看出这条路线的成果:
V3.2 将“自我进化式工程”(高 RL 预算、合成数据闭环)应用在通用效率上;
Speciale 则把过程奖励与自我验证机制推向高阶逻辑推理。
两者共同指向同一个方向:未来的模型不再依赖人力堆砌,而是依靠自我博弈实现持续演进。
下一步就是扩大预训练算力来弥补知识差距。这也让人联想,一是如果DeepSeek真把算力补上来,会发生什么?二是,这些新的算力资源从哪里来?
回头看过去一年的技术路径,Janus的多模态统一架构、OCR的视觉压缩记忆、NSA的长上下文效率、Math-V2的自我验证……这些创新都是在V3这个基座上迭代出来的。
那么,一个参数更大、训练 FLOPs 更多的 V4,再叠加这些已经验证有效的方法论,会出现怎样的化学反应?
一个合理、甚至是大胆的预期是,当 V4 或 R2 到来时,我们看到的可能已经不是传统意义上的“更强语言模型”,而是一个能够感知多模态环境、具备更长期记忆、并能在真实交互中持续进化的系统。如今发生在合成环境中的自我博弈,未来可能会延伸到真实环境的在线学习。
而在算力上,在今天英伟达频繁形容其中国市场份额已经归零的背景下,继续scaling需要的算力资源看起来不太能够靠H800们提供,下一代模型会用什么样的更大的算力资源训练,如果这些算力缺口可以被补齐,完全形态的DeepSeek下一代模型会是什么样?这些显然更重要,也更让人产生联想。
