

Sequoia Capital 在 2026: This is AGI 这篇文章中断言 AGI 就是把事情搞定(Figure things out)的能力。
如果说过去的 AI 是 Talkers 的时代,那么 2026 年则是 Doers 的元年。转变的核心载体正是 Long Horizon Agents(长程智能体)。这类 Agent 不再满足于对上下文的即时回复,而是具备了自主规划、长时间运行以及目标导向的专家级特征。从 Coding 到 Excel 自动化,原本在特定垂直领域爆发的 Agent 能力,正在向所有复杂任务流扩散。
作为 LangChain 的创始人,Harrison Chase 一直处于这场变革的最前沿。本文编译了 Sequoia Capital Sonya Huang & Pat Grady 访谈 Harrison Chase 的最新播客。作为站在 Agent 基础设施最前沿的先行者,Harrison 揭示了为什么 Agent 正迎来其爆发的“第三个拐点”。
核心 Insight 提炼:
•Long Horizon Agents 价值在于为复杂任务提供高质量初稿;
•Agent 的突破需要围绕模型构建的、有主见的(Opinionated)软件外壳(Harness),文件系统权限将成为所有 Agent 的标配;
•通用 Agent 可能就是一个 Coding Agent;
•Traces 成为新的 "Source of Truth";
•相比于通用模型,一个经过长时间磨合、内化了特定任务模式与背景记忆的 Agent,将形成极高的 moat;
•理想的 Agent 交互是异步管理和同步协作的统一。
01.
Long-Horizon Agents 的爆发
Sonya Huang:你怎么看 Long Horizon Agents ?对于红杉最新的文章,哪些观点是你同意的,哪些你不同意?
Harrison Chase:我同意它们终于开始真正 work 了。让 LLM 在一个循环中运行并自主决策,这一直是 Agent 的核心理念。AutoGPT 就是这样,它之所以能激发人们的想象力,是因为 LLM 在循环中能自主决定下一步做什么。
问题在于,当时的模型不够好,周围的 Scaffolding 和 Harness 也不够好。 现在模型变强了,我们在过去几年也学到了什么是好的 Harness,所以它们开始真正起作用了。我们最先在 Coding 领域看到这一点,这也是最快起飞的地方,并正在向其他领域扩散。
AutoGPT 是 2023 年爆火的开源自主 AI agent 框架(最早的“让 GPT 自己思考、规划、执行”的经典实现),通过让 LLM 反复自我提示(think → plan → act → observe 的循环)来完成复杂多步任务。
Scaffolding 指围绕语言模型构建的辅助性代码结构或框架,用于引导模型输出、管理流程或处理输入输出,但不具备复杂的自主规划能力。
Harness即包裹模型、管理 Context、处理文件 I/O 并执行工具调用的软件环境,通常包含预设的规划工具、环境交互能力和最佳实践,旨在让模型更稳定、高效地执行复杂任务。
虽然你仍需给 Agent 下达指令、提供合适的工具,但它能运行的时间越来越长。所以 Long Horizon 这个说法非常贴切。
Sonya Huang:你最喜欢哪些 Long Horizon Agents 的例子?
Harrison Chase:Coding 领域的例子最多,我也用得最多。 除此之外,AI SREs 是个很好的例子。比如 Sequoia 投资的 Traversal,他们的 AI SRE 可以处理长时程任务,深入挖掘日志。 Research 也是个很好的场景,因为它最终产出的是初稿。
AI SREs,AI 站点可靠性工程师,利用人工智能技术自动监控、诊断和修复软件系统故障的智能体,能处理日志分析和系统维护等任务。
Traversal 一家专注于打造 AI SRE 的初创公司,旨在利用 AI 自主解决复杂的软件工程和运维问题。
Agent 的问题在于达不到 99.9% 的 Reliability ,但能做大量工作,并且能在更长的时间跨度上工作。需长时间运行,产出某项任务初稿的场景,就是 Long Horizon Agents 的杀手级应用。
Coding 是个典型。你通常提交一个 PR(Pull Request),而不是直接推送到生产环境,除非用户在 Vibe Coding。这方面变得越来越好。AI SREs 也是同理,通常是把结果提交给人审查。 生成报告也是,没人会直接发给所有粉丝,总得自己先看一遍、改一改。
我们在金融领域已经看到了很多这类应用,这里潜藏着巨大的机会。以前 Agent 只做一线回复,现在有了像 Klarna 这样的新案例,走的是人机协作路线。当一线 AI 搞不定要转人工时,系统不会直接把烂摊子丢给人,而是有一个在后台运行的 Long Horizon Agent 生成一份前因后果的总结报告,再移交给人工。
Klarna 是一家提供先买后付的支付公司。
所以,核心用例就是这些围绕初稿概念的场景。
02.
从通用框架到 Harness 架构
Sonya Huang:关于 Why now,多大程度上是因为模型本身变得足够强大,又有多少归功于在 Harness 方面做了巧妙的工程设计?深入探讨前,简单界定一下你眼中的 Harness 和模型的区别,以及 Agent 的具体构成。
Harrison Chase:好的,我得先引入 Framework 这个概念。早期我们就是这样定义 LangChain 的,它本质上是 Agent Framework。但进入 Deep Agents 时代后,我更愿意称之为 Agent Harness。
Deep Agents 是 LangChain 推出的下一代自主 Agent 架构,基于 LangGraph,内置 Planning、文件系统、Sub-agent 生成能力。
LangGraph 是 LangChain 团队推出的一个低级、可控的图状工作流框架。
常有人问这三者的区别:
•模型:显然就是 LLMs,输入 Token,输出 Token。
•Framework:围绕模型建立的抽象层,让切换模型、添加工具、Vector Store 和 Memory 变得容易。它是 Unopinionated(无预设)的,价值在于抽象。
•Harness:更像是开箱即用的。谈到 Deep Agents 时,Harness 默认内置了 Planning tool,它非常 Opinionated(强预设),认为这就是做事的正确方式。
我们需要做压缩。Long Horizon Agent 运行时间很长,虽然 Context Window 变大了,但终究有限。到某个时间点,必须对 Context 进行压缩。问题是,怎么压?这方面有很多前沿研究。我们提供给 Agent 的另一套关键能力是文件系统交互,无论是直接读写还是通过 Bash 脚本。
其实很难单纯归功于 Harness 或模型,因为现在的模型本身也是在大量此类数据(代码、CLI)上训练出来的。这是一种共同进化。若回到两年前,我不认为我们能预知基于文件系统的 Harness 会是终极方案,因为那时的模型还没针对这些场景充分训练。
所以这是多因素叠加:模型确实变强了,特别是 Reasoning Models 功不可没;但同时也因为我们搞清楚了围绕压缩、Planning 及文件系统工具的一系列 Primitives(原语)。是这两者的结合带来了突破。Sonya Huang:记得在我们第一期播客里,你把 LangGraph 形容为 Agent 的认知架构。这是否是理解 Harness 的正确方式?
Harrison Chase:没错。我们在 LangGraph 之上构建 Deep Agents。它是 LangGraph 的一个特定实例,但非常有主见,也更通用。
早期我们讨论过通用 vs 专用架构。现在的趋势是,以前那些为了约束模型而写在 LangGraph 里的特异性,正转移到工具和 Instructions 中。复杂度没有消失,只是变成了自然语言。因此,Prompting、编辑 Prompt 甚至自动优化 Prompt 成了核心,而 Harness 本身的结构保持得相对固定。Sonya Huang:Harness 层面最难攻克的是什么?你认为个别公司真的能在 Harness Engineering 上建立壁垒吗?在这方面你欣赏谁?Harrison Chase:说实话,目前 Harness Engineering 做得最好的都是 Coding 公司。这是技术腾飞的领域。比如 Claude Code,它之所以如此火爆,很大一部分原因在于它的 Harness 设计。Pat Grady:这是否意味着 Harness 更适合由基础模型厂商自己构建,而不是第三方创业公司?Harrison Chase:很难说。我想提到的另一家公司是 Factory,还有 Amp,它们都是 Coding 类公司,并且都有非常出色的 Harness。
Factory 是一家专注于构建全栈 AI 软件工程师的公司,能自动完成从需求到上线完整 SaaS 应用的开发,强调 agent 的自主性和生产级代码质量。构建的名为 Droid 的 Agent 位居 Terminal-Bench 2.0 榜首。
Amp Code 是一家主打下一代 AI 编码体验的公司,提供极致智能的代码补全、编辑和生成能力,在代码理解和多文件编辑上表现突出。
这事各有利弊。Harness 某些部分确实与模型,或者说与模型家族,深度绑定。比如 Anthropic 的模型在某些特定工具上有过 Fine Tuning ,而 OpenAI 则在另一些工具上微调过。就像不同的模型需要与 Prompt 适配,现在 Harness 也是同理,针对不同模型家族需要微调。但共性依然存在,比如都基于文件系统。
这其实是个很有趣的现象。现在几乎每个 AI Coding 公司都在造自己的 Harness。目前主流 Coding Benchmark,如 Terminal-Bench 2.0,会将经过 Harness 的 Agent 与模型分开列出。同一个模型的性能波动巨大,Claude Code 在榜单上也未必总是第一。这说明模型厂商未必天生更擅长此道。只要深刻理解模型原理,第三方开发者完全能在 Harness 层面挖掘出巨大性能提升。
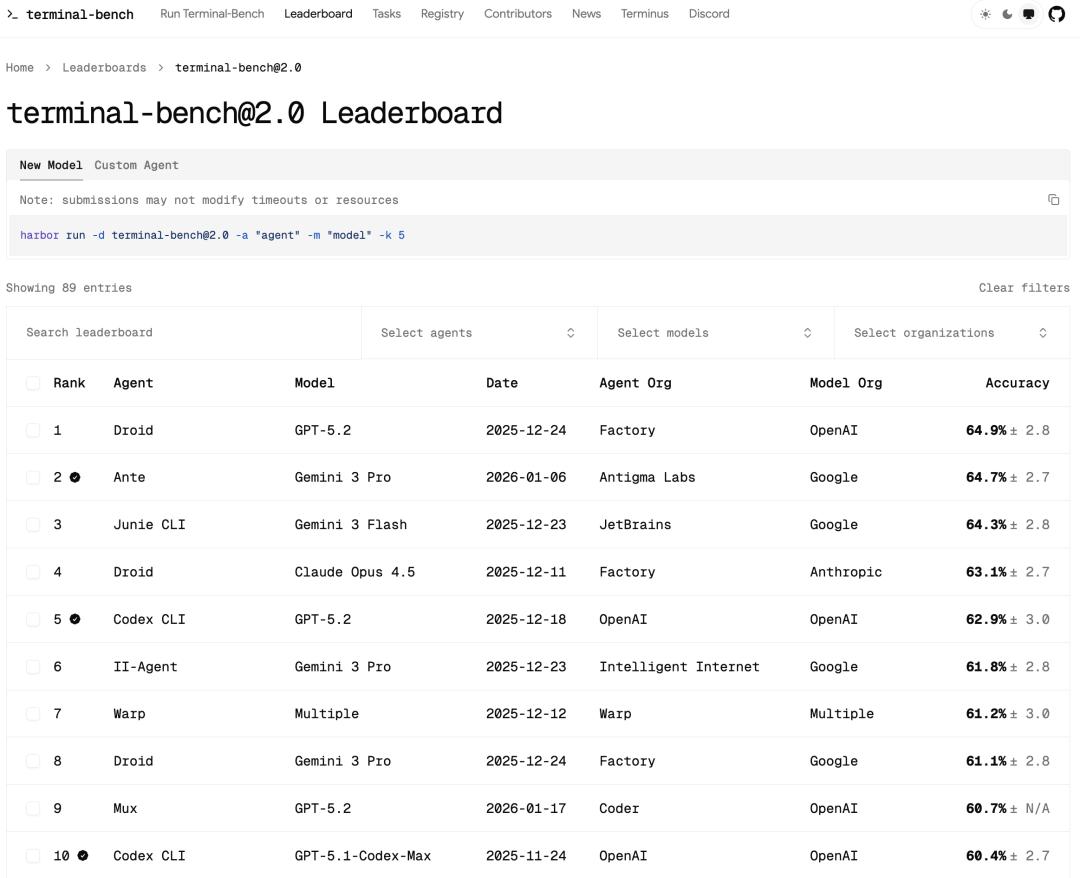
https://www.tbench.ai/leaderboard/terminal-bench/2.0
Terminal-Bench 2.0 是目前 AI agent 终端/命令行能力的最硬核开源基准榜单,由 tbench.ai 团队维护,包含 89 个精心挑选的真实终端任务(涉及编译代码、训练模型、搭建服务器、生物/安全/游戏等领域复杂多步操作),专用来严苛评估 AI agent 在真实沙箱终端环境下的端到端问题解决能力、工具使用和长期自主性。
Sonya Huang:你认为让 Harness 高效运转的关键是什么?榜单头部玩家做对了什么?Harrison Chase:首先是对模型训练数据的深刻理解。OpenAI 的模型在 Bash 命令行上训练得极多,而 Anthropic 似乎针对文件编辑工具做过专门训练。顺应模型的特性非常重要。
其次是压缩。当任务周期变长、Context Window 满载时,如何取舍是巨大的挑战,也是 Harness 的核心价值。再者是 Skills、MCPs 和 Sub-agents 的运用。目前模型本身并未内化太多 Sub-agents 能力,主要靠 Harness 调度。比如在我们的 Harness 中,主模型调用 Sub-agent 时,需传递完整信息,并指示 Sub-Agent 何时输出最终结果。
我们见过一些失败案例:Sub-agent 做了一堆工作,最后只回一句“见上文”,主模型没有收到任何有效信息。协调组件工作的 Prompting 至关重要。看看现在的开源 Harness,System Prompt 动辄几百行,就是为了解决协同问题。Pat Grady:聊聊演变路径。你一直处在让模型落地现实世界的配套基建最前沿。
若简化看过去五年的拐点,一是 Pre-training (ChatGPT);二是 Reasoning (OpenAI o1);最近伴随 Claude Code 和 Opus 4.5 级别模型,迎来了 Long Horizon Agents 的第三个拐点。
在你构建的世界里,拐点是否不同?从认知架构到 Framework 再到 Agent Harness,核心跃迁是什么?
Harrison Chase:我认为可以分为三个时代:
第一阶段是早期,即 LangChain 刚起步时。模型还是原始的 Text-in/Text-out,甚至没有 Chat 模式,没有 Tool Calling,没有推理能力。大家能做的就是简单的 Prompt 或链式调用。
第二阶段是模型实验室开始引入 Tool Calling,试图让模型学会思考和规划。虽然当时的效果不如今天,但已经足以做决策了。这时自定义认知架构开始流行,你需要显式地写代码问模型:“现在该做什么?”,然后按分支走。这更像是在模型外面搭 Scaffolding 。第三阶段的拐点,大概发生在 2025 年六七月份。Claude Code、Deep Research、Manus 集中爆发。底层架构其实一样,把 LLM 放在循环里运行。但它们巧妙地运用了 Context Engineering ,包括围绕压缩、Sub-Agent、Context Skills 的一切。核心算法没变,但 Context Engineering 变了。这让我们意识到“这和以前不一样了”,于是我们开始做 Deep Agents。
对 Coding 社区来说,随着 Opus 4.5 发布或大家寒假狂用 Claude Code,这种感觉尤为强烈。11、12 月发生了巨大的 Vibe Shift。大家意识到,把难题扔进去,Long Horizon Agent 真的能搞定。那一刻,模型足够好了,我们从 Scaffolds 时代正式迈入 Harness 时代。
03.
Coding Agent 是通用 AI 的终局形态吗
Pat Grady:接下来会怎么发展?Harrison Chase:我也想知道。但我确信,“让 LLM 在循环中运行并自我编排的算法,让它自己决定把什么拉入 Context ”这一极简且通用的 Agent 核心理念,终于实现了。
未来的手工 Scaffolds 会越来越少。目前像压缩这类操作还很依赖 Harness 作者的手动设计。Anthropic 正尝试让模型自主决定何时压缩,虽然还没普及,但这可能是方向。
另一个重点是 Memory。在长时程任务中,Memory 其实就是长周期的 Context Engineering。核心算法很简单:Run LLM in a loop。接下来的竞争点在于围绕它的 Context Engineering 技巧,或是像 Anthropic 那样把工程本身交给 LLM,又或是引入新型 Context 数据。我现在最大的疑问是,目前成功的 Harness 大多针对 Coding。即使是非编程任务,你也可以辩称“写代码”本身就是极好的通用手段。Pat Grady:这正是我要问的。Coding Agents 到底是一个子类别,还是说所有 Agent 本质上都应该是 Coding Agents?因为 Agent 的工作就是让计算机干活,而代码是最好的指令方式。Harrison Chase:这是个大问题。我深信,构建 Long Horizon Agent 必须给它文件系统权限。
文件系统在 Context 管理上太有用了。比如压缩时,把原始消息存进文件,只留摘要在 Context 里,模型需要时再去查阅;或者返回巨大的 Tool Call 结果时,不要全塞给模型。把它存进文件系统,让它自己去查。其实这不一定需要真正的文件系统,也不需要它写代码。
我们有个虚拟文件系统的概念,底层由 Redis 等支持,稳定性更好。但显然,代码能做很多虚拟文件系统做不到的事。你没法在虚拟文件系统里运行代码,这时候写 Script 就非常有用了。
所有 Agent 是否最终都是 Coding Agent 也是我们目前思考的最多的问题之一。
04.
构建 Long Horizon Agent vs 构建软件
Sonya Huang:构建 Long Horizon Agent 与构建传统软件有何不同?你在 X 上写了一篇很很好的文章,能否总结并描述当今的数据与代码开发栈?
Harrison Chase:这值得深思。大家都说构建 Agent 不同于构建软件,但本质区别在哪?
几点看似显而易见,却很重要:
构建软件时,逻辑全写在代码里,可见可控。构建 Agent 时,逻辑不全在代码里,很大一部分来自模型。这意味着你不能只看代码就推断 Agent 在特定场景下的行为,必须实际运行。这就是最大区别。我们引入了非确定性黑盒系统,且它置于代码之外。
这对开发者意味着,想知道 App 干了什么,看代码没用,必须看它在现实中的行为。这也是为何 LangSmith 的 Tracing 最受欢迎。Tracing 能复现 Agent 内部每一步。
LangSmith 是 LangChain 生态的可观测性平台。
这与传统软件的 Traces 不同。软件通常只在报错时查日志。但在 Agent 开发中,人们从第一天起就用 Trace。因为 Agent 循环运行,你根本不知道第 14 步的 Context 是什么,因为前 13 步可能拉取了任意东西。这又回到了 Context Engineering。Trace 揭示了 Context 内容,这至关重要。
软件的 Source of Truth(单一事实来源)是代码;Agent 的 Source of Truth 是代码 + Tracing。这意味着 Trace 成了你思考 Testing 的地方。你更需要 Online Testing,因为行为只有在遇到真实世界输入时才会涌现。
Trace 正成为团队协作的支点。出问题时,大家不是说“去 GitHub 看代码”,而是说“看看 Trace”。开源社区也是,用户反馈 Deep Agents 跑偏,我们会要 LangSmith Trace 而非代码。
还有一点,构建 Agent 更加 Iterative。 软件是你设定好目标再迭代,发布前行为已知。 Agent 在发布前行为未知。你有个大概,但没十足把握。为了让它达标、通过概念上的 Unit Test,你需要更多迭代。
这也是为何 Memory 重要。Memory 是从交互中学习。如果系统能自我学习,就减少了开发者手动修改 System Prompt 的频率。
Pat Grady:我也很好奇。现有软件公司能活下来吗?类比当年本地转云部署,鲜有成功者。你认为这次能跨越吗?年轻创始人似乎更有白板优势。
Harrison Chase:我们确实看到很多 Agent 团队成员更 Junior,没有思维定势。
但在公司层面,数据仍然非常有价值。 如果你想 Harness 包含什么,就是 Prompt、Instructions 和工具。现有软件公司拥有所有数据和 API。接入 Agent,价值巨大。但另一部分是,关于如何处理这些数据的 Instructions。这部分可能是全新的。以前这是人做的,你只提供工具,没尝试自动化。
像 Rogo 这样的垂直初创公司之所以有效,是因为很多 Agent 是由 Knowledge 驱动的。不是通用知识,而是关于如何执行 Specific Patterns 的知识。
Rogo 是 2025 年爆火的 Wall Street AI 工具,一家专注于金融行业的安全生成式 AI 平台,能自动生成 pitch deck、财务模型、IPO 文件草稿、实时研究报告和洞察,目标是大幅取代/辅助 junior banker 的重复性手动工作。
所以,构建软件的人是构建 Agent 的合适人选吗?很多非常资深的开发者也采用了 Agentic Coding,所以人才上是心态问题,同时可能确实有年轻化偏差;但公司层面,取决于数据。
05.
从人类判断到 LLM-as-a-Judge
Sonya Huang:Trace 是 Agent 开发的核心产物。还有其他的吗?特别是 Eval 方面。
Harrison Chase:不算产物,应该叫组件。构建软件和 Agent 的另一个本质区别在于 Eval。传统软件依赖程序化断言,但 Agent 做的是人做的事,评判需引入 Human Judgment。这也是我们在 LangSmith 试图解决的:如何把人类判断带入 Traces?
一种是直接引入人,比如 Data Labeling 公司,或者在 LangSmith 中也有 Annotation Queues。人直接去标注 Traces,比如给出自然语言反馈,包括“这很好”“这很坏”“这里应该这样做”等;有时人做的是纠正,把正确的步骤列出来。这取决于具体用例,模型公司做 RL 和应用公司构建 Agent 的需求可能不太一样。
另一种是建立人类判断的 Proxies,即 LLM-as-a-Judge。 关键在于确保它与人类判断对齐。如果不对齐,评分器就是垃圾。 LangSmith 有 Aligned Evals,即先让人类标注一些 Trace,系统基于这些标注构建一个 LLM-as-a-Judge,进行针对性校准。LLM-as-a-Judge 包含了几个不同层面。 大多数人在 Evals 中用它来给 Trace 打分,比如 0 到 1 分,或者 0 到 10 分。这是通用的做法。因为有些判断不需要 Ground Truth,做法有离线做也有在线。
但另一个被忽视的领域是,在 Coding Agents 本身就能看到这一点。 Coding Agent 工作过程遇到 Error,随即纠正这个 Error。这实际是在评判自己之前的工作。 我们在 Memory 中也看到了,Memory 很大一部分就是反思 Trace 然后更新东西。
所以,无论是对自己的还是之前的会话,LLM 有充分的能力反思 Trace。我们在 Evals、自动纠错、Memory 中都看到了这一点。本质上,它们是同一回事。
Sonya Huang:既然有了 Trace 和 Eval,这个 Eval 是 RL 的 Reward Signal?还是给工程师改进 Harness 的反馈?
Harrison Chase:其实是给 Agent 工程师改进 Harness 的。我们有 LangSmith MCP 和LangSmith Fetch(一个 CLI 命令行工具)。这是大趋势。Coding Agents 擅长用 CLI。把 CLI 交给 Agent,它就可以拉取 Trace,诊断问题,自己修复代码。这绝对是我们看好并支持的模式。对于应用类公司,我对这个模式比对 RL 更看好。
Sonya Huang:这听起来像是真正的 Recursive Self-improvement。
Harrison Chase:是的,但仍有 Human-in-the-loop。如前所述,最理想的状态是 Agent 产出初稿,如修改了 Prompt,然后人类进行审核,确保它不跑偏。
举个例子,我们推出了构建 Agent 的无代码工具, LangSmith Agent Builder。其有个很酷的功能是 Memory。 目前它的工作方式是:当你与 Agent 交互时,如果说“你应该做 Y 而不是 X”,它会修改它自己的 Instructions,即编辑文件。 这就是自我改进。我们正计划增加每晚运行、查看当天 Trace 并更新自身状态的功能,即 Sleep time compute。
LangSmith Agent Builder 是 LangChain 团队在 2025 年底推出的无代码 AI agent 构建工具,目前已公测。它允许任何人只需用自然语言聊天描述需求(比如“帮我建一个能读 Gmail、自动分类邮件并草拟回复的助手”),它就会自动生成、配置、连接工具、添加记忆和提示的完整 agent,还支持从预置模板一键启动、快速迭代反馈、部署上线。
06.
未来的交互与生产形态
Sonya Huang:未来呢?你谈了很多 Memory。
Harrison Chase:我非常看好 Memory。让 Agent 自我改进很酷,但并非全场景适用。ChatGPT 加了 Memory,但我没怎么用,也没增加粘性,因为我去 ChatGPT 都是做 One-off 任务,如问代码、问美食、问旅行,彼此之间没关联。
但在 Agent Builder 里,你构建的是特定工作流。比如我的 Email Agent,之前积累了很多 Memory。后来我想迁移进 Agent Builder,结果丢了旧 Memory。哪怕 Prompt 和工具完全相同,新 Agent 体验也远不如旧的。如果不经长时间磨合,很难好用。
这就是为何我认为 Memory 是真正的 Moat。我们到了 LLM 可以查看 Traces 并修改代码/指令的节点。问题在于如何安全、用户可接受地落地。在垂直场景下这绝对是大势所趋。
Sonya Huang:你认为 Long Horizon Agents 的 UI 会如何演变?
Harrison Chase:我认为需要 Sync mode(同步模式) 和 Async mode(异步模式)的结合。 Long Horizon Agent 运行时间长,默认应该是 Async 的。像 Linear、Jira 和 Kanban 看板这类工具,甚至包括 Email,对于构思如何管理这些 Agent 很有参考价值。
但对于大多数 Agent 来说,在某个节点,你一定会想切换到同步沟通模式。因为当 Agent 输出一份研究报告,你需要针对其中的错误给出反馈。
唯一要补充的是,现在的 Agent 不只是在说话,它们是在修改 State,比如文件系统里的文件。你必须有办法可视化这些 State,就像程序员离不开 IDE 里看代码。即便我用 Claude Code 跑完了任务,我依然会打开 IDE 去检查它到底改了什么。
Anthropic 的 Cowork 做了一个极好的范式。你设置一个目录作为它的 Workspace。这建立了一种非常清晰的心理模型:我们在一个 Shared State(无论是本地文件、Google Drive 还是 Notion)上协作。
Hybrid Mode未来的交互形态就是这种Hybird Mode:你异步管理一堆后台运行的 Agent,但在关键时刻,你进入 Sync Mode 与它 Chat,同时你们都在盯着同一个 State 看。
Sonya Huang:这完全验证了你之前的 Agent Inbox 理念,要实现 Sync Mode,Agent 必须有一个能随时触达到你的入口。
Harrison Chase:没错。一年前,我们发布了 Agent Inbox 第一版,当时的主打概念是 Ambient Agents。Agents 在后台运行,偶尔 Ping 你一下。
最初的版本没有 Sync Mode,它 Ping 你,你回一句,然后只能干等它下次 Ping 你。这种体验非常破碎。因为很多时候,比如回邮件,用户需要的是极短时间的高频交互,而非切出去干等。
后来我们做了一个巨大的转向。用户点开 Inbox 时,会直接进入 Chat 界面。Chat 本质上就是 Synchronous 的。我的判断是:Pure Async(纯异步)在目前是跑不通的。除非模型进化到完全不需要 Human-in-the-loop 纠错的程度。否则我们注定要在 Async 和 Sync 之间来回切换。
Sonya Huang:你怎么看 Code Sandboxes?每个 Agent 都要有沙箱、CLI 或 Browser 访问权限吗?
Harrison Chase:好问题。 目前 Code Execution 显然比 Browser Use 更有用、更落地。
•关于文件系统,我是坚定的 "File System Pilled"。我认为某种形式上,所有 Agent 都应该能访问文件系统。
•关于 Coding,我大概 90% 确信这是标配。对于 Long Tail 的复杂用例,Coding 能力是无可替代的。
•关于 Browser Use, 目前的模型还不够好。虽然有一些很酷的尝试(比如给 Coding Agent 一个 CLI 来操作浏览器),但尚未成熟。
所以,Code Sandboxes 绝对是未来的核心组件。
