

近日,硅谷顶级AI公司Anthropic与美国国防部(DoD)之间的一场博弈,成了AI圈的焦点。在宣布与五角大楼合作时,Anthropic特别强调了两条红线:AI不得用于攻击性武器,也不得用于大规模国内监控。
但是五角大楼希望Anthropic解除其AI模型Claude的所有使用限制,这与Anthropic的两条红线产生了冲突。
五角大楼与Anthropic的矛盾核心其实是人工智能技术的使用边界与伦理底线之争,是「无限制使用」与「安全护栏」之间的根本性冲突。
从古至今,无论是机构还是商业体,在构建系统控制的闭环中,一直遵循着一条清晰的路径,即知道你是谁,了解你想要什么,最终掌握你的行为与选择。
而这条路径的第一步,就是确认你是谁。从互联网诞生之初,匿名就被视为其核心特质。“在互联网上,没有人知道你是一条狗。”人们在各个论坛、社区中披上不同的马甲,享受着免于现实身份束缚的言论自由。
当然,我们也习惯见到各种人肉搜索和开盒。某个网红说错话,愤怒的网民就会调动集体智慧,从只言片语中拼凑出当事人的真实身份。
但这种传统的去匿名化方法耗时耗力,需要人工比对大量信息,通常只针对引发公众关注的高价值目标。
而企业想要了解用户偏好来精准推送广告,则更依赖IP地址、设备指纹、跨应用追踪这些相对便宜的技术手段。但这些方法在日益严格的隐私保护政策下,正变得越来越困难。
然而,AI的到来可能彻底改变这个游戏规则。Anthropic自己和黎世联邦理工学院等机构近期发布的一篇重磅论文《利用大语言模型进行大规模在线去匿名化》,就对AI的开盒能力进行了一次极限测试。

他们的结论是,AI,以其精准度与低廉的成本,基本已经宣判了互联网匿名时代的死刑。
所以Anthropic的担心完全有道理。因为你,随时都可以被从匿名之壳中被任何人轻易的定位。
01
开盒简史,从手工作坊到自动化流水线
去匿名化,即开盒,在本质上是一个剥洋葱的过程。开盒者首先从一个匿名者的零散发言中描绘出他的数字轮廓,然后将这个轮廓与一个已知身份的数据库进行匹配。
在AI时代之前,隐私安全领域最著名的一次开盒事件,是2008年Netflix挑战赛攻击。当时,Netflix公开了一批经过匿名处理的用户电影评分数据,试图悬赏优化其推荐算法。
Narayanan和Shmatikov发现,只需要将这些匿名的评分数据与公开的IMDb(互联网电影资料库)账号进行比对,通过几部冷门电影的评分和时间戳这样的微数据,就能轻而易举地还原出这些匿名用户的真实身份。
所谓微数据,就是个体层面的信息片段,比如「给《暮光之城》打了5星」、「住在德州」、「从不大写句首字母」。单个片段可能不足以识别你,但当多个片段组合起来,就能构成独特的指纹。就像87%的美国人可以仅凭邮编、出生日期和性别三项信息被唯一确定一样,看似无关紧要的细节,累积起来就是身份的钥匙。
但Netflix攻击的这个策略有个限制,即它需要结构化的数据。电影评分是整齐的数字矩阵,可以用算法直接比对相似度。
而真实的互联网是由无数非结构化的闲聊、吐槽、主观评论和口语化表达构成的。比如「昨天带狗去多洛雷斯公园散步,真怀念波特兰的雨水」提供了很多信息,但传统的算法根本读不懂。面对这种非结构化文本,过去唯一有效的办法就是投入专业的调查员,像侦探一样逐字逐句地阅读、分析和推演。
这种巨大的人力成本,构成了保护普通人隐私的一道坚固的成本护城河。这种因为调查成本过高而产生的安全感,被称为事实上的隐蔽性(practical obscurity)。
大语言模型的到来,瞬间抽干了这条护城河。大模型最核心的超能力,正是对人类自然语言及其背后复杂语义的深刻理解。它不再需要整齐划一的表格,它能够直接阅读你在任意平台上的任意发言,并在瞬间抽丝剥茧。
过去需要人类专家耗费数小时才能完成的逻辑推理和信息提取,现在大模型只需要几秒钟和极低的算力成本就能完成。
提出安全红线的Anthropic,在2025年12月公开了125名科学家与AI的访谈记录,讨论他们如何在工作中使用AI工具。这些记录做了部分编辑(隐去敏感信息),本意是保护隐私。
但就在数据发布几周后,就有研究者通过LLM匹配访谈中提到的研究课题和已发表的论文,找到了被访者的真实身份。33名谈论过去研究的科学家中,AI成功识别了9人,比先前的方法多找到50%。
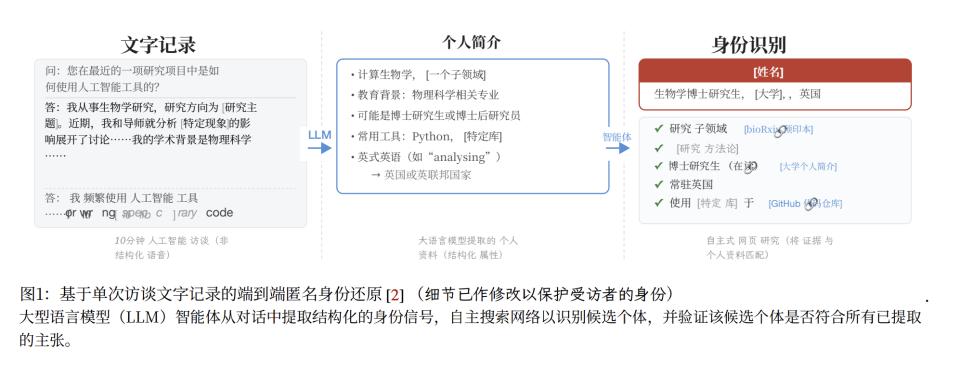
(Anthropic访谈的开盒方法)
而这只需要几分钟和几美元。
AI并没有发明新的攻击逻辑,它只是以前所未有的规模和极低的成本,将这种攻击普及到了互联网的每一个角落。
02
AI开盒,只需四步
为了验证AI的真正实力,研究团队设计了一套名为ESRC的可扩展自动化攻击流水线。这套流水线将去匿名化分解为四个高度自动化的步骤。

第一步是提取(Extract)。LLM会阅读目标用户的所有帖子和评论,从中归纳出结构化的个人档案。通过语义层面的理解,模型可以从一个Reddit用户说的「今年CS224N课把我折磨惨了,大四真难熬」,提取出他是斯坦福CS专业(因为CS224N是斯坦福的自然语言处理课程)、大约22岁、住在旧金山。即使用户从未直接说我是斯坦福学生,AI也能从信息中推断出来。
第二步是搜索(Search)。面对动辄数百万候选人的庞大互联网数据库,AI将提取出的个人档案转化为密集的语义向量(Embeddings)。传统的Netflix攻击也有类似步骤,但它只能比对结构化特征(电影评分、编程语言、工作地点),而LLM的嵌入向量能够捕捉更丰富的语义信息,包括隐含的兴趣、价值观。通过计算多维空间中的余弦相似度,系统能够在极短的时间内从89000个Hacker News用户中找出最相似的前100名。
第三步是推理(Reason)。这是AI展现真正恐怖实力的阶段。传统算法在计算完相似度后就束手无策了,而AI流水线会调用具备极强逻辑推理能力的大模型(如GPT 5.2),对初筛出来的几十个嫌疑人进行深度的交叉验证。模型会像法官一样,审视时间线是否有冲突,生活细节是否自洽,从而大幅度降低误判的可能。
第四步是校准(Calibrate)。为了确保攻击的有效性,AI必须学会判断自己的「确信度」。系统会提示大模型输出一个绝对的置信度分数。如果还想更好的提高确信度,研究员还会让AI对所有候选匹配进行两两比较,通过类似排序竞赛的方式给出最终排名。这种方法在大规模攻击场景下特别有效。
在这个实验中,设计者强化了对事实语义线索(Semantic content)的挖掘。而弱化了文体学(Stylometry),即通过分析一个人使用的虚词频率、语法结构和语气特征来确认身份的方法。因为那些根植于生活经验中的客观事实(比如你所在的城市、你患有的某种慢性疾病、你喜欢的特定冷门事物)是难以长期掩饰的。事实比文风更加致命,也更容易被大模型交叉比对。
当然,这项研究本身面临一个矛盾:要验证攻击效果,需要知道正确答案,但知道答案意味着用户本来就不够匿名。
研究者采取了两种策略。一种是合成匿名化,即找那些主动公开身份的用户(比如Hacker News账号简介里写了LinkedIn链接),然后用AI把所有直接标识符抹掉(姓名、链接、GitHub账号),只保留语义信息,看AI能否重新识别。
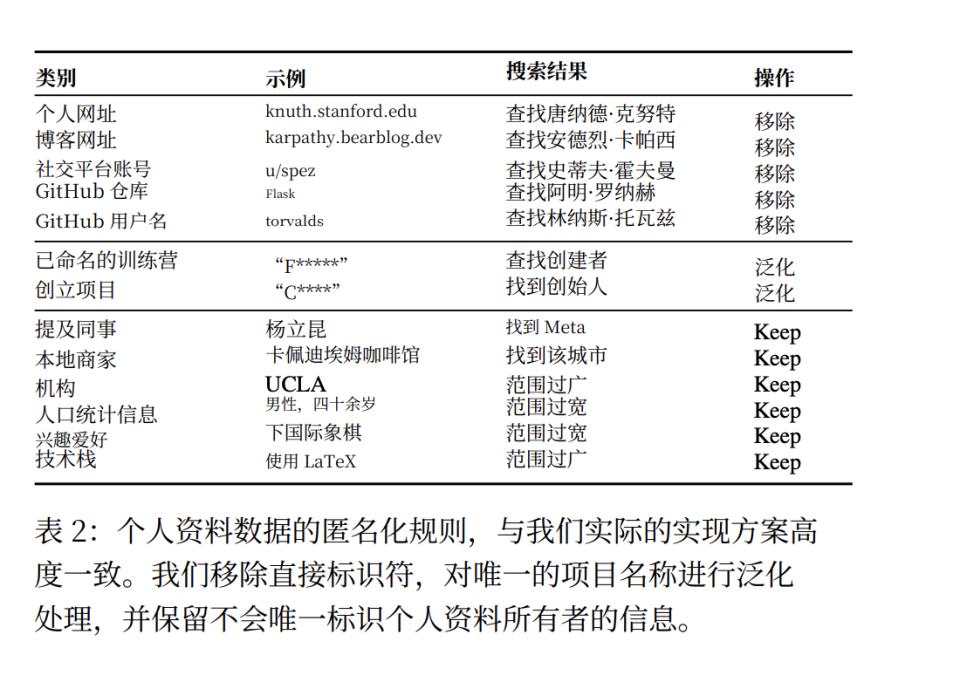
另一种是时间分割法,即把同一个Reddit用户在不同时期的发言切成两份,看AI能否把它们重新匹配。
这两种方法都有偏差,比如主动公开身份的人可能本来就不在乎隐私,同一个人的两段历史天然有相似性,但它们至少提供了可量化的基准,让我们能比较不同方法的优劣。
更值得强调的是,整个流程使用的都是公开可用的模型和标准API,包括Gemini的嵌入模型、GPT-5.2的推理能力、普通的向量检索库。
没有定制模型,没有专有数据,没有黑客技巧。任何有一定技术能力的人,都能复现这套攻击。
03
三种场景,层层递进的威胁
为了探明AI开盒的边界,研究团队分别在三种极其复杂的场景中进行了测试,这三种场景层层递进地验证了AI的普适性。
为了衡量这套流水线的威力,我们需要先理解两个核心指标的定义:精确率(Precision)和召回率(Recall)。
精确率指的是在AI最终给出肯定答复的所有匹配中,真正找对人的比例。而召回率则是指在所有本来就有真实对应身份的目标中,AI成功匹配上了多少人。
对于监控者或攻击者而言,找不到是可以接受的,但抓错人是灾难性的。因此,接下来的所有测试,都是在AI保持90%甚至99%极高精确率的严苛条件下进行的。
跨平台匹配
第一种场景是跨平台匹配,这是最常见的开盒模式。就是试着让AI把一个匿名论坛的马甲与现实世界的职业身份相绑定。
研究团队收集了987个在Hacker News简介里贴了LinkedIn链接的用户(这提供了验证用的正确答案),然后用AI抹掉所有直接标识,从89000个候选用户中尝试重新匹配。
通过在这个看似跨度极大的任务中,大模型展现了压倒性的优势。在90%精准率的设置下,AI正确识别了67%的用户。即使提高到99%精准率(基本不出错),仍然能识别45%。作为对比,传统的Netflix式攻击方法在这个任务上几乎完全失败,召回率只有0.1%。
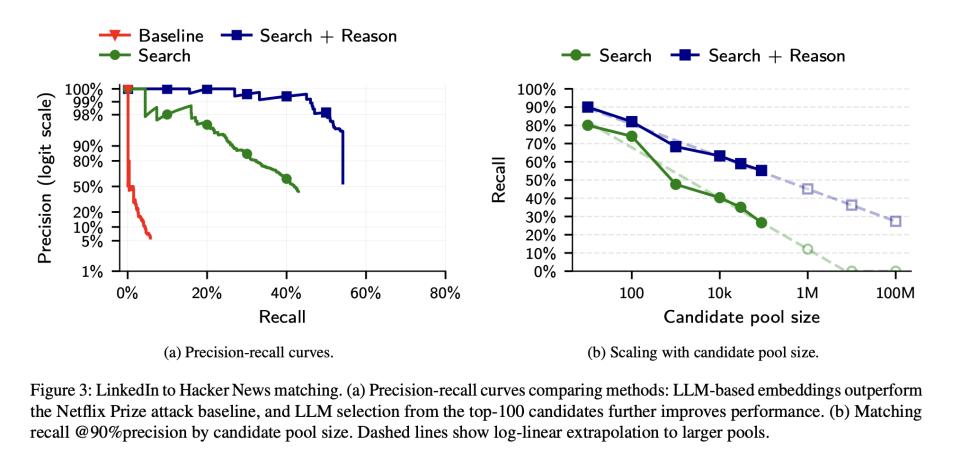
而且AI的优势随着候选池扩大而愈发明显,当候选人从1000增加到89000,传统方法彻底崩溃,AI方法的召回率只下降了13个百分点。研究者还做了大胆的推算:如果候选池扩大到100万人(接近真实平台的规模),AI仍可能保持35%的召回率;即使是1亿候选人,理论上还能识别27%。
跨社区匹配
第二种场景是跨社区匹配。测试同一个人在Reddit的不同板块(主流电影论坛 vs 小众电影社区)发言,能否被AI关联起来。
这是个更难的任务,因为用户在不同社区讨论的电影有限,重叠的话题可能很少。
研究者让AI只看两个社区共同讨论的电影评论,有48%的用户只分享了一部电影,然后尝试匹配9781个用户。

这次AI的表现相对温和:90%精准率下召回率为8.5%,99%精准率下降到2.8%。
但这个场景引出了信息丰度的区分度,即到底需要透露多少信息,一个人才会被AI锁定?研究发现,即便是极少量的信息,也没有绝对的安全阈值。只提到1部共同电影的用户,召回率是3.1%;提到5-9部的,召回率跃升到23%;提到10部以上的,召回率高达48%。你在网上的每一次主观表达,都在不断增加你数字拼图的清晰度,而且是非线性的加速暴露。
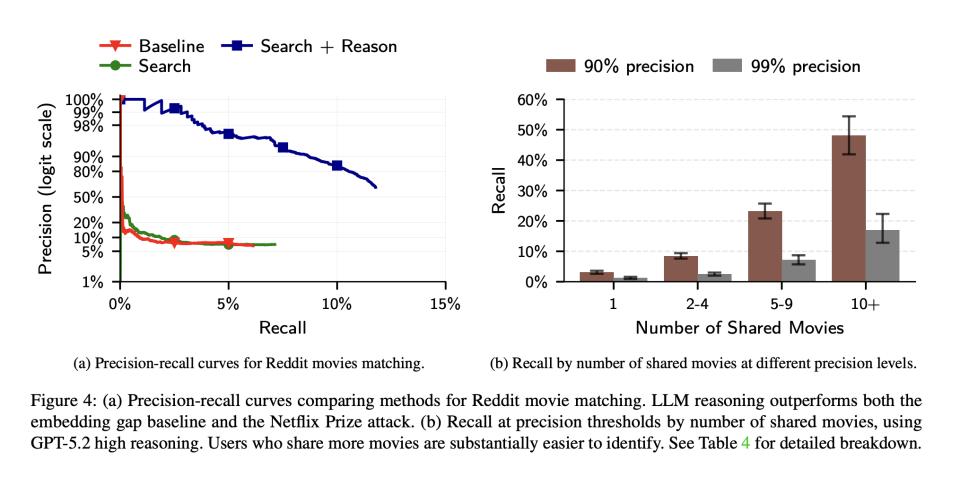
更值得注意的是,使用"高推理努力"模式的GPT-5.2比低推理努力的效果好了一倍(99%精准率下2.8% vs 1.4%),说明AI的推理能力仍在快速进化,未来模型会更强。

跨时间匹配
第三种场景是更加极限的跨时间匹配。人是会变的,一个人的关注点、居住地和心境都会随着时间流逝而改变。因此时间往往被视为保护隐私的天然屏障。
为了挑战这一屏障,研究团队将Reddit用户的发言历史按照一年的时间跨度硬生生切开,用一年前的发言去匹配一年后的账号。这考验AI的核心理解能力,它需要能从表面的话题差异中,抓住深层的、持久的身份特征。
在这种极其困难的场景下,为了确保极低的误报率,AI使用了前文提到的校准步骤。
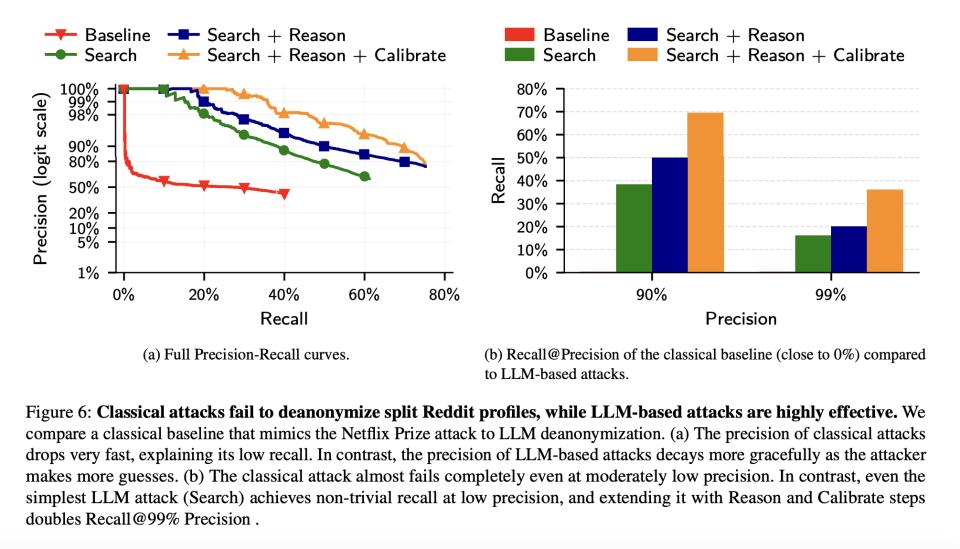
在5000个测试用户、10000个候选档案的设置下,加了校准的AI达到了67.3%的召回率(90%精准率)和38.4%(99%精准率)。
这比跨社区匹配高得多,说明即使话题变化,一个人的深层特质,如地理位置、职业领域、核心价值观、兴趣爱好还是相对稳定的。
结果证明,哪怕跨越了一年的岁月鸿沟,AI依然能够精准提取那些极其稳定的人格特征和微观数据,将过去与现在的你死死绑定在一起。
研究者还做了一个极端测试:如果只有千分之一的查询用户在候选池中有真正的匹配(99.9%都是找不到的),AI还能工作吗?答案是依然可以。即使匹配概率降到万分之一,AI仍能在90%精准率下识别出约9%的可匹配用户。
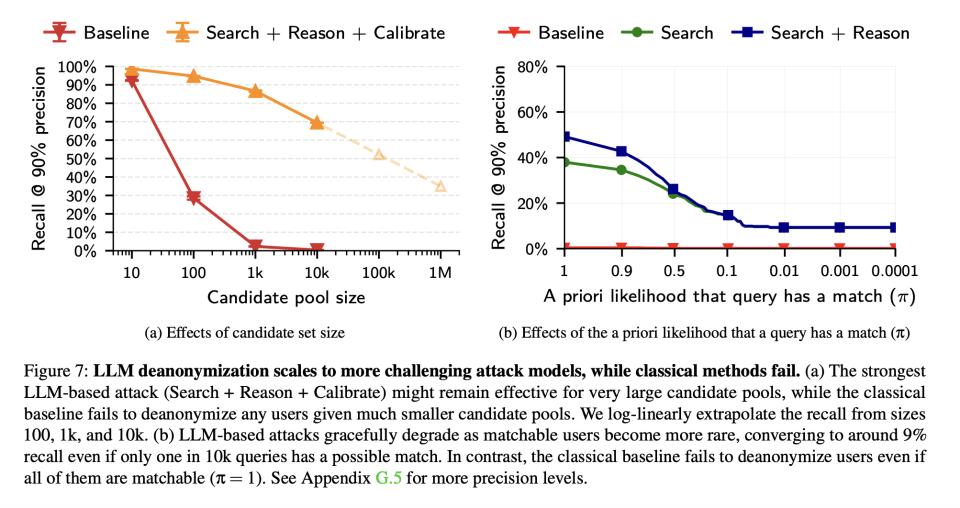
这意味着,就算绝大多数人根本不在被搜索的数据库中,那些确实能被识别的人,还是会被AI揪出来。
04
匿名的终结
这些实验结果基本上已经宣布了网络匿名时代的终结。
研究者测试了几种防御方法,结果都不乐观。可以限制API访问速度,但攻击者可以分布式爬取;可以检测自动化行为,但AI的使用模式很像正常用户的高度阅读;可以用差分隐私或k-匿名性技术,但这些都是为结构化数据设计的,对自由文本效果有限。
甚至LLM提供商的安全防护也难以奏效,因为这套攻击管道的每个步骤(总结、嵌入、比对)看起来都像正常使用,很难被检测为滥用。
唯一有效的防御,是平台从一开始就不公开用户的历史发言。
那互联网还有什么用呢?
你在论坛寻求医疗建议,必然要描述症状和病史;你在技术社区请教问题,需要说明你用的工具和遇到的错误;你在影评网站分享观感,自然会暴露品味和观影习惯。这些信息本身无害,却正是AI用来识别你的微数据。
而只需要几台服务器和一套LLM管道。不需要侵入任何私人设备或通讯,只需要分析公开信息,就足以从网络中定位具体的你。隐私政策和用户协议在这里完全无效,因为数据本就是公开的。
要彻底防御,你只能选择闭嘴,那等同于退出了现代社会的协作网络;如果你选择发声,你就是在向深渊递交自己的身份证。
而Anthropic承诺不把AI用于大规模国内监控,这是值得赞许的立场。
但正如这项研究所展示的,监控所需的能力已经不需要专有模型,用公开可用的LLM、标准的API、普通的数据集,就能实现曾经只有情报机构才具备的能力。
从技术条件、安全保护等一切可能的方面,都没有任何人能阻止你被极低成本的开盒。
AI时代,匿名已死。
也许在AI的未来中,逃避被控制的艺术将不再是躲入山中,而是永久下线。
