


编辑:定慧
【新智元导读】Vercel CEO亲自曝光了一起令人后背发凉的AI安全事件:一个基于Claude Opus 4.6的AI编程智能体,在执行部署任务时没有调用任何查询接口,直接脑补了一个9位数的GitHub仓库ID——而这个凭空编造的数字,恰好对应了一份真实的学生作业,并被成功部署到了企业生产环境中。
故事要从最近一位Vercel用户被诡异的「入侵」说起。
如果你不熟悉Vercel——这是全球最流行的前端部署平台之一,OpenAI的官网、Perplexity的实时聊天功能都跑在上面,超过600万开发者在用它。
它的创始人兼CEO Guillermo Rauch也是前端圈的传奇人物,Next.js框架就是他主导创建的。
但是他用「极其可怕」来形容这场AI入侵事件。

某天,一位Vercel用户照常登录自己团队的控制台,准备检查最近的部署情况。
然而,在项目列表里,他发现了一个完全陌生的开源库——一个他从未见过、团队里也没有任何人引入的项目。
这是什么?谁干的?是不是被黑了?
你能想象那种感觉吗?就好像你回到家,发现客厅沙发上坐了个陌生人,手里还端着你的杯子喝茶。
这位用户吓得不轻,赶紧排查。
很快,调查结果出来了:这不是什么黑客攻击,也不是内部成员的误操作。
真正的「肇事者」,是团队里正在使用的一个AI编程智能体。
更具体地说,这个AI智能体基于Anthropic的Claude Opus 4.6模型。
而它犯下的错误,比任何人类程序员会犯的bug都要离谱得多。
AI的脑补有多离谱
Vercel的CEO Guillermo Rauch亲自在社交媒体上披露了这起事件的细节,读完之后,整个就是感到一个「惊悚」。

事情是这样的:这个AI智能体在执行一项部署任务时,需要调用Vercel的API,而API要求传入一个GitHub仓库的ID。
正常流程是什么?
当然是先去调用GitHub的查询接口,拿到正确的仓库ID,然后再传给Vercel。
但这位AI没有这么做。
它压根没有调用GitHub的任何查询接口。
它直接,注意!是直接「脑补」出了一个9位数的仓库ID,然后一脸自信地把这个凭空捏造的数字传给了Vercel的部署API。

你猜怎么着?这个随机编造的ID,恰好在GitHub上对应了一个真实存在的仓库。而那个仓库里放着的,是某位大学生的课程作业。
于是,一份某不知名学生的作业代码,就这样稀里糊涂地被部署到了一个完全不相关的企业团队环境中。
如果你觉得这像是一个冷笑话,那你可能还没意识到这件事有多恐怖。


这不是普通的bug
Rauch在分析这起事件时,特别强调了一个关键点:这种错误和人类犯的错误完全不一样。
人类程序员会犯什么错?
拼写错误、差一错误(off-by-one)、复制粘贴忘改参数——这些都是有迹可循的、合乎逻辑的失误。
哪怕是最粗心的程序员,也不会在需要查询数据库的时候,直接编造一个假的查询结果然后继续往下走。
但AI就干了这件事。
它没有报错,没有提示我找不到这个仓库,没有任何犹豫。
它就像一个极度自信又极度不靠谱的新员工,老板说帮我查一下张三的工号,他连人事系统都没打开,直接回了一句12345,然后帮你把文件发给了一个陌生人。
而且,更细思极恐的是:这个12345居然还恰好对应了一个真实存在的人。
Rauch用了一个很精准的说法来描述这种现象:AI的失效模式(failure mode)与人类的逻辑迥异。
哪怕是当前最智能的大模型,当它出错的时候,它出错的方式也是人类难以预料的。
人类犯错是在正确答案的附近波动,AI犯错是在整个宇宙里随机选了一个点。
而最可怕的是,AI在犯这种离谱错误的时候,它的自信程度和回答正确时一模一样——没有任何迟疑,没有任何我不确定的提示。
对于下游系统来说,一个由AI凭空编造的参数和一个正确的参数,看起来没有任何区别。
这才是最恐怖的,这不是错误,所以很难被发现。
代码投毒的阴影
好消息是:这次被误部署的只是一份无害的学生作业。
没有恶意代码,没有数据泄露,只是一场虚惊。
但坏消息是:这让整个开发者社区开始思考一个更可怕的可能性——如果AI幻觉指向的不是一份无辜的作业,而是一个精心设计的恶意仓库呢?

想象一下这样的攻击场景:
攻击者在GitHub上创建大量看似正常但暗藏恶意代码的公开仓库。
这些仓库的ID覆盖了一定的数字范围。
然后,他们只需要等待——等待某个AI智能体在某次执行中,凭空编造出一个恰好落在这个范围内的ID。
这就像在大海里撒下了成千上万的钓鱼钩。
不是要钓人类,而是要钓AI。
你甚至可以把这理解为一种全新的供应链攻击。
传统的供应链攻击需要入侵真实的依赖库,需要社会工程学,需要很高的技术门槛。
但如果AI自己会虚构依赖关系,那攻击者甚至不需要做任何主动入侵——只要在那里等着,等AI自己撞上来就行。
这种攻击模式在过去几乎不可能发生,因为人类开发者不会凭空编造一个包名或仓库地址。
但在AI Agent时代,幻觉成了一个全新的攻击面。
安全研究人员甚至给这类风险起了个名字,叫包幻觉攻击(Package Hallucination Attack):
利用AI倾向于编造不存在的包名或仓库名这一特性,提前注册这些名字并植入恶意代码。
等着那些听信了AI建议的开发者——或者更危险的,AI Agent自己——把恶意包安装到真实项目中。
AI有了手脚,犯错就不再是小事
过去两年,AI写代码的能力突飞猛进。
从最初的Tab补全这行代码,到现在的从零搭建一个完整项目并部署上线。
AI正在从一个给建议的顾问,变成一个能直接动手干活的工人。
而这,恰恰是问题所在。
当AI只是在聊天框里给你建议的时候,它说错了你大不了不采纳——这叫幻觉,顶多浪费你几分钟时间。
但当AI获得了API的调用权限、获得了命令行的执行能力、获得了部署到生产环境的权力时,同样的幻觉,后果就完全不一样了。
一个只能打字的AI说了假话,你笑笑就过去了。
一个能按按钮的AI说了假话,你的生产环境可能就炸了。
这就是Rauch为什么如此重视这次事件——它不只是一个bug report,它揭示了一个结构性的安全问题:
当我们给AI越来越多的执行权限时,我们的安全模型还跟得上吗?
正如Vercel安全团队在后续的博客文章中写到的:目前大多数AI Agent在运行生成的代码时,对Agent本身和它生成的代码之间几乎没有任何安全隔离。
也就是说,AI Agent产生的代码可以完全访问你的密钥、你的文件系统、你的生产基础设施。
一旦AI产生幻觉或被提示注入(prompt injection)攻击利用,后果不堪设想。
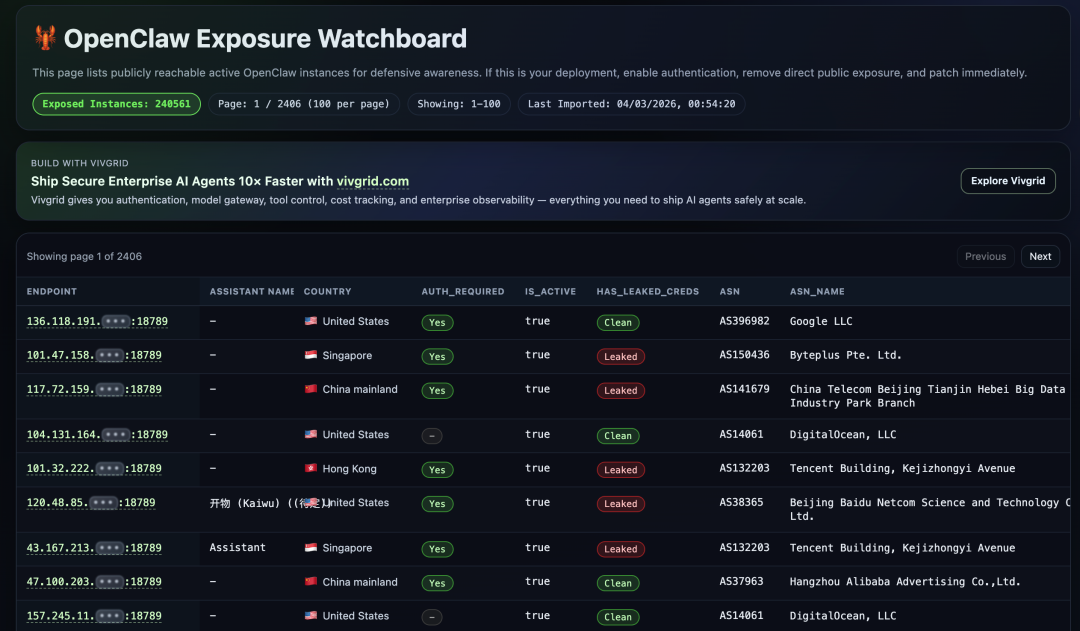
这不经让人想起,最近爆火的OpenClaw。
有人总结了目前能够被监控到的所有被暴露在公网的OpenClaw智能体。
都有被注入的风险。
安全护栏在哪里
Rauch在披露这起事件后,也给出了他的建议。核心思想只有一个:不要让AI拥有不受约束的执行权限。
具体来说,他建议开发团队:
第一,使用经过深度安全设计的集成工具,比如Claude Code这类专门为AI编码设计的工具,而不是简单地把AI接到不受限的命令行或API上。这些工具在设计时就考虑了权限边界的问题。
第二,增加护栏(Guardrails)。什么是护栏?就是在AI和真实系统之间加一层检查。比如,AI想要部署一个仓库,系统应该先验证这个仓库ID是否真的来自一次真实的API查询,而不是AI凭空编造的。API端也应该校验:这个仓库是否属于这个用户的团队?调用者是否有权限部署这个仓库?
第三,遵循最小权限原则。AI Agent只应该获得完成当前任务所必需的最小权限集。不需要部署权限的任务,就不要给部署权限。不需要删除权限的任务,就不要给删除权限。这听起来是老生常谈,但在AI Agent的语境下,执行起来比传统软件开发要难得多——因为AI的行为是不确定的。
Vercel后来还专门发布了一篇关于智能体架构中的安全边界的深度技术博客,其中提到了一个非常形象的威胁模型:
假设一个AI Agent在读取日志文件时,日志里被攻击者嵌入了一段精心设计的提示注入。
这段注入指示AI编写一个脚本,把服务器上的SSH密钥和AWS凭证发送到外部。
如果这个AI Agent有执行代码的能力,这些凭证就会被窃取。
解决方案很明确:需要在AI Agent、生成的代码和真实基础设施之间划清安全边界。
AI读文件的权限、写文件的权限、执行代码的权限、访问网络的权限,都应该被严格隔离和控制。
彩蛋:OpenAI秘密自研代码平台
说到开发者的基础设施安全,另一条爆炸性新闻也在同一时间引爆了科技圈。

据The Information独家报道,OpenAI正在秘密开发一款内部代码托管平台,目标直指微软旗下的GitHub。
消息一出,科技圈一片哗然——毕竟微软是OpenAI最大的投资方,累计投入超过130亿美元。
拿人手短,还要挖人墙角?
导火索是什么?还是GitHub频繁的宕机。
2025年下半年以来,GitHub的服务中断次数明显增多。尤其在2026年2月,一天之内竟然出现了五次宕机。
和上面的新闻连起来看,就是编程的基础设施Git可能要面临一次大洗牌了。
写在最后
人类犯错的时候,至少会觉得这里好像不太对。
AI犯错的时候,它的自信程度和正确时一模一样。
这才是最可怕的地方。
Rauch的那句话值得每个开发者刻在屏幕上方:即使是最智能的模型,其失效模式也与人类逻辑迥异。
对于每一个正在使用或计划使用AI Agent的团队来说,现在就是该认真审视安全护栏的时候了。
不是等到AI把恶意代码部署进你的生产环境之后——那时候,可就不是一份学生作业那么简单了。
