

全球市值一哥,也杀入OpenClaw战场了!
昨夜,英伟达重磅祭出新一代「开源模型」Nemotron 3 Super,专为大规模AI智能体打造。
它共有1200亿参数,120亿激活参数,100万token上下文,推理狂飙3倍,吞吐量暴涨5倍。

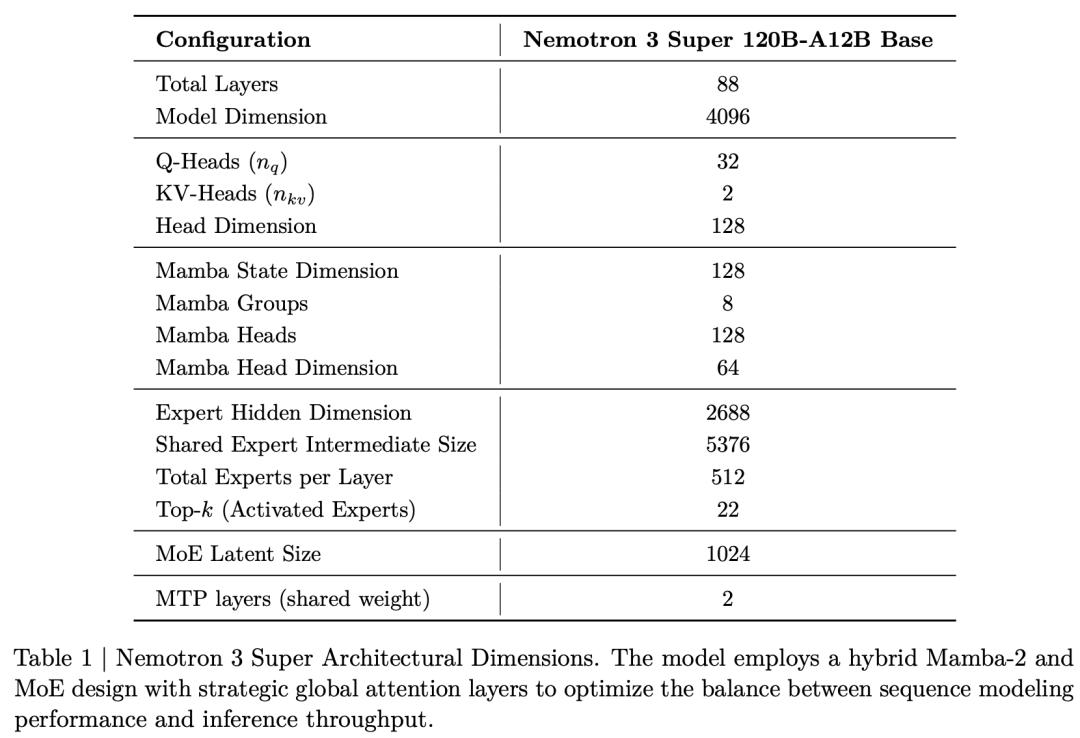
Nemotron 3 Super采用了创新的Mamba-MoE混合架构,彻底解决了多Agent协同中的性能瓶颈。
而且,它还是「Nemotron 3家族」中,首个实现以下三大突破的模型:
原生采用NVFP4精度进行预训练;
全新的LatentMoE混合专家架构,把「单位算力准确率」和「单位参数准确率」优化到了极致;
引入MTP(多Token预测)层,通过原生「投机解码」让推理速度狂飙。
在Pinchbench基准上,Nemotron 3 Super一骑绝尘,稳坐开源第一。
在OpenClaw任务成功率上,它拿下了85.6%的高分,性能直逼Claude Opus 4.6、GPT-5.4。

可以说,完美适配OpenClaw的「最强开源模型」,诞生了!
今天,Nemotron 3 Super超过10万亿Token的预训练和后训练数据集、完整训练方法论,以及15个强化学习环境全部开源。
地址:https://huggingface.co/collections/nvidia/nvidia-nemotron-v3
英伟达1200亿巨兽炸场,OpenClaw绝配
如今,聊天机器人阶段迈向多Agent应用,通常会装上「两堵墙」。
第一个是上下文爆炸。
多智能体工作流生成的Token数,比常规对话多出高达15倍。
因为每一次交互都需要重新发送完整的历史记录,包括工具输出和中间的推理过程。
在执行长周期任务时,这种巨大的上下文数据量不仅推高了成本,还容易导致目标偏移(goal drift),即逐渐偏离了Agent最初设定的目标。

第二个是「思考税」(thinking tax)。
复杂的Agent必须在每一步都进行推理,但如果在每个子任务上都调用LLM,会让多Agent应用的成本,变得极其高昂且反应迟缓,难以在实际应用中落地。
为此,英伟达开源的Nemotron 3 Super,彻底击碎了Agent应用的「两大枷锁」。

论文地址:https://research.nvidia.com/labs/nemotron/files/NVIDIA-Nemotron-3-Super-Technical-Report.pdf
如上所述,Nemotron 3 Super拥有100万Token上下文。
尤其是在运行OpenClaw环境下,AI能将整个工作流状态完整保留在内存中,确保从第一步到最后一步的逻辑一致性。
在Artificial Analysis上,Nemotron 3 Super刷新了SOTA,登上了效率和开源榜一。
在同等规模开源模型中,新模型准确率也是遥遥领先。
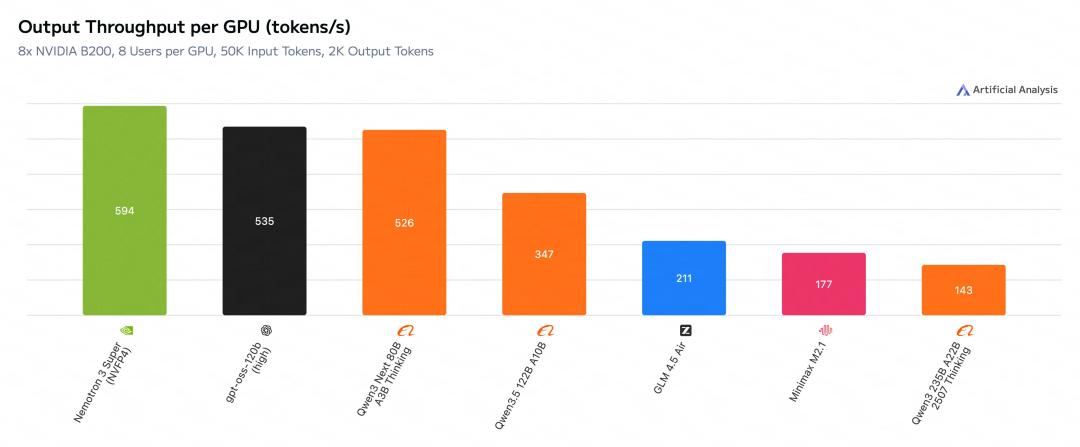
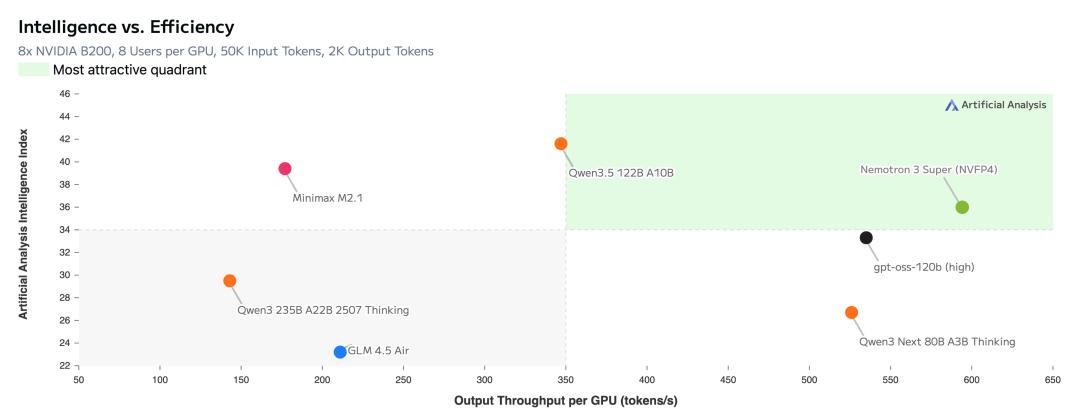
同时,新模型加持的NVIDIA AI-Q研究型AI智能体,在DeepResearch Bench 和 DeepResearch Bench II排行榜上拿下第一。
未来五年,英伟达将投入260亿美元,用于打造全球顶尖的开源模型
混合架构革命,吞吐狂飙5倍
这一次,英伟达对Nemotron 3 Super底层架构进行了重构。
88层网络采用了周期性交替排列,其中Mamba-2层负责高效的序列建模,提供线性时间复杂度。
而少量Transformer注意力层则作为「全局锚点」穿插其中,负责跨位置的长距离信息路由和高精度推理。
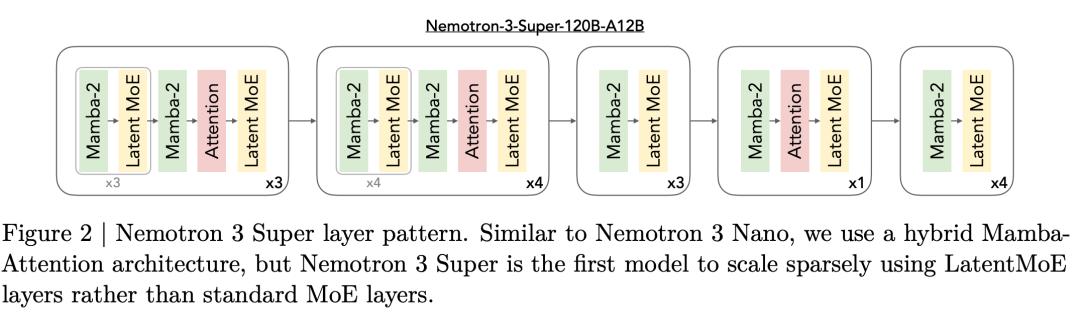
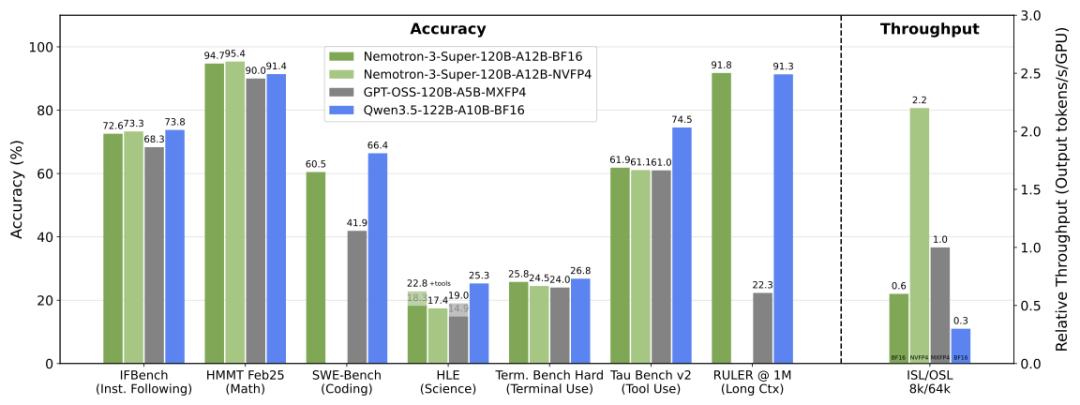
结果,与上一代Nemotron Super模型相比,吞吐量提升高达5倍,准确率提升高达2倍。
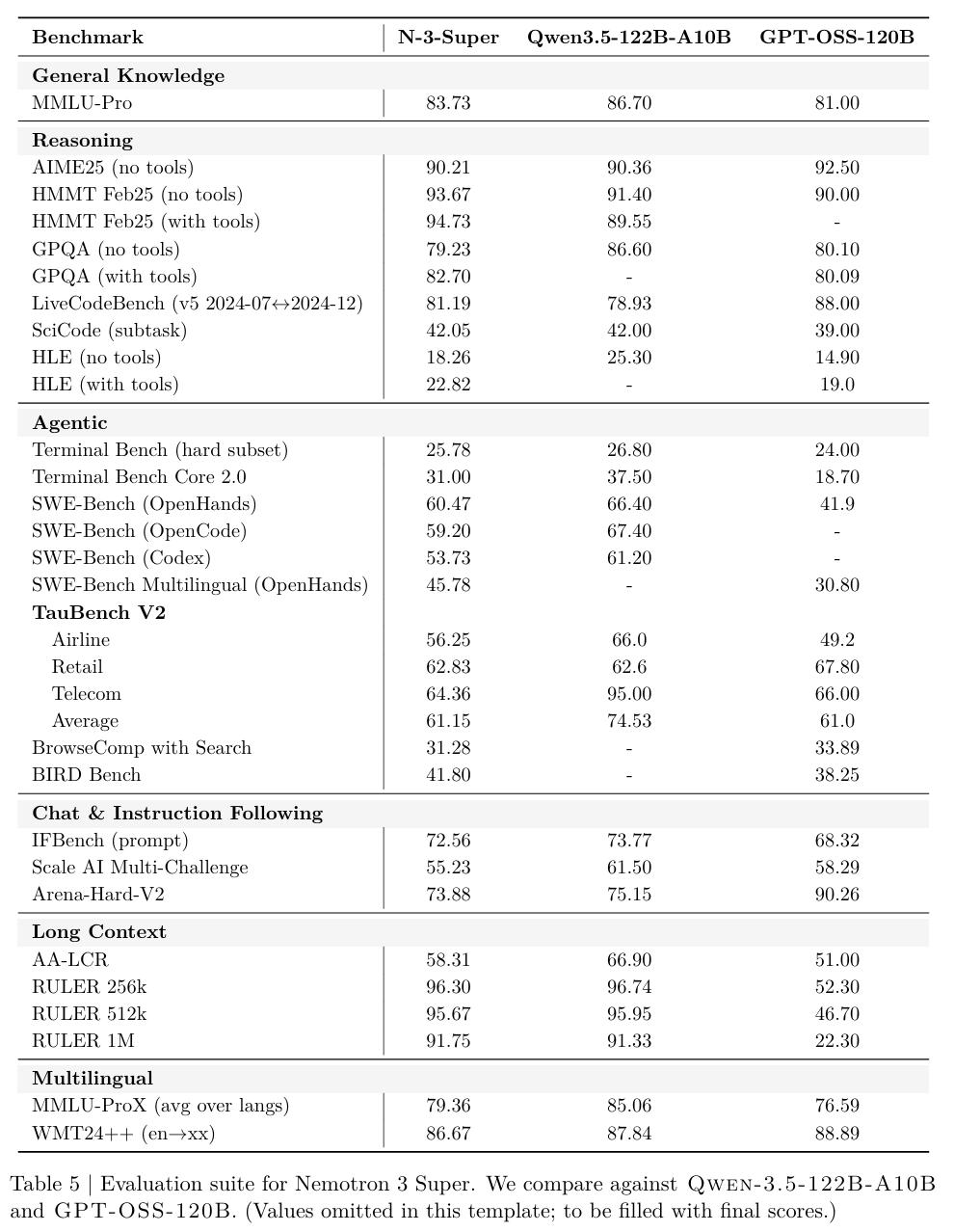
与GPT-OSS-120B、Qwen3.5-122B对比,Nemotron 3 Super均拿下了最高成绩。
而且,在输入序列长度为8k、输出序列长度为64k时,它的吞吐量分别比GPT-OSS-120B和Qwen3.5-122B高出多达2.2倍和7.5倍。
LatentMoE:懂硬件的专家设计,榨干每一字节的准确率
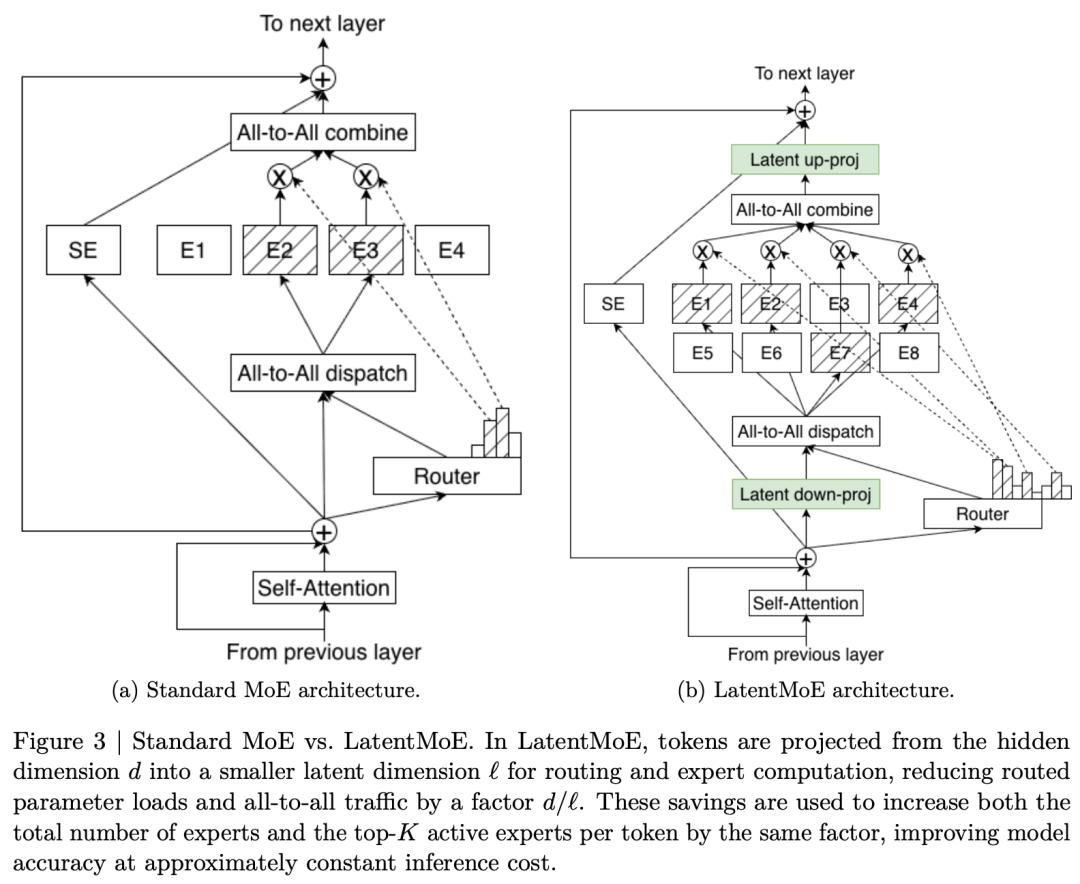
更重要的是,Nemotron 3 Super首次引入了「隐式MoE」(Latent MoE)。
LatentMoE的解法非常精巧,在路由和专家计算之前,先把Token从隐藏维度d投射到一个更小的潜在维度ℓ。路由和专家计算都在这个小得多的维度里进行。
这意味着需要加载的专家参数和跨卡通信量,直接缩小了d/ℓ倍!
省下来的这些资源,就可以用来把专家总数和每次激活的专家数放大同样的倍数。等于「白嫖」了一波准确率,而推理成本几乎没变。
英伟达官方博客的说法更直观:花1个专家的计算成本,激活4个专家。
相比传统的MoE,LatentMoE在参数利用率和算力利用率上都更胜一筹。
多Token预测:性能+推理效率一箭双雕
Nemotron 3 Super还加入了一个大杀器:多Token预测(MTP),模型质量和推理效率一举两得。
传统的训练方式都是「预测下一个token」(Next-token),但MTP要求模型在每个位置上一口气预测未来好几个 Token。
这其实是在逼着模型去理解多步之间的因果关系和更长远的文本结构。
事实证明,这招非常管用,模型的验证集 Loss 和下游跑分都迎来了实打实的提升。
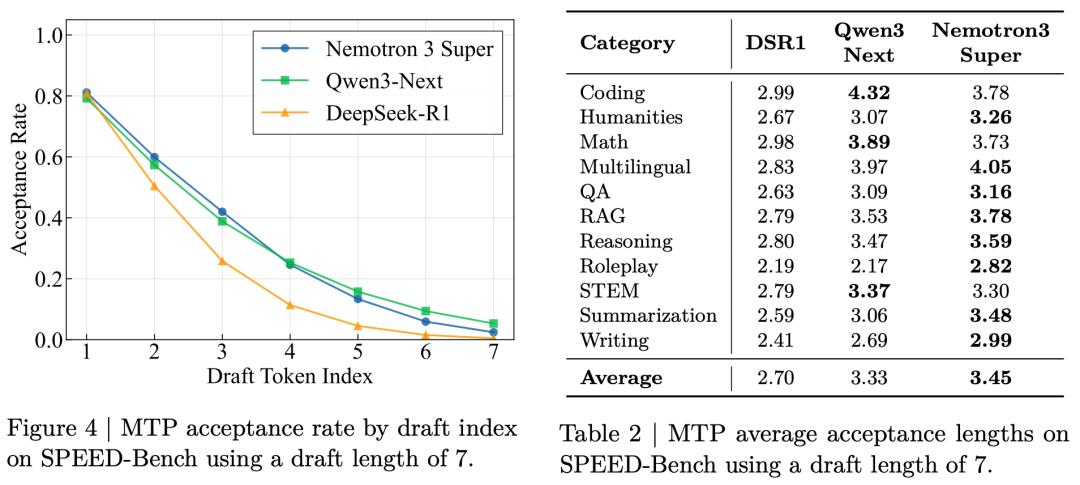
除了变聪明,MTP最大的妙用是实现了原生的投机解码(Speculative Decoding)。
这些额外的预测头就相当于在模型肚子里内置了一个「草稿模型(Draft model)」。
在推理时,预测头会先快速打个草稿(生成后续几个Token候选),然后主模型在一次前向传播中把这些草稿全部验算一遍。
这招大幅降低了生成延迟,而且相比于外挂一个独立的草稿模型,它带来的额外算力开销(FLOPs)微乎其微。
原生NVFP4精度预训练
正如英伟达研究副总Bryan Catanzaro所言,Nemotron 3 Super专为Blackwell设计。
预训练阶段,团队在Blackwell平台上全程使用NVFP4精度运行,显存需求大幅降低。
而且,在0准确率损失的前提下,新模型的推理速度比Hopper架构上的FP8还要快4倍。

25万亿Token + 21个RL环境,瞄准AI智能体
和之前的Nemotron 3 Nano一样,Nemotron 3 Super也是吃着25万亿Token文本数据长大的。
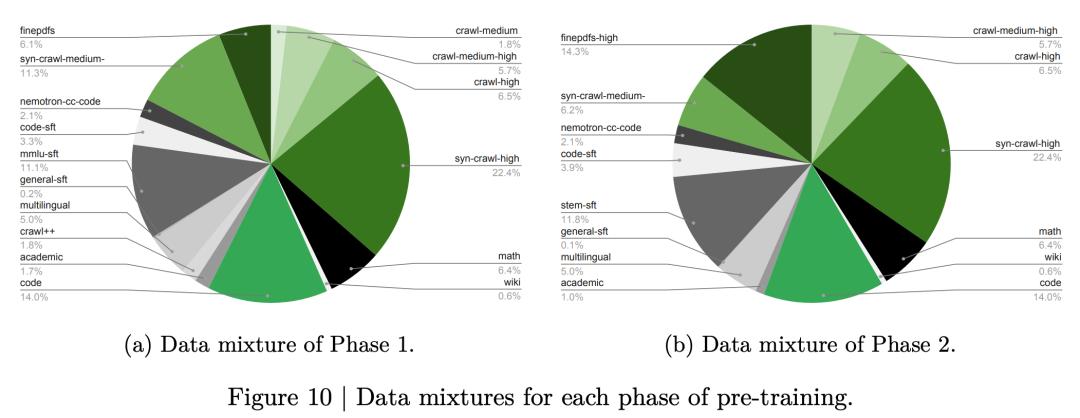
整个预训练分为两步走:
第一阶段吃掉80%的数据(20万亿Token),主打一个数据多样性和知识面广,语料涵盖16个大类,从网页爬取到代码、数学、学术论文、多语言数据一应俱全;
第二阶段吃掉剩下的20%(5万亿Token),这部分全是精挑细选的高质量数据,维基百科、高质量PDF、STEM推理数据的权重被大幅提升,专门用来拉升准确率。
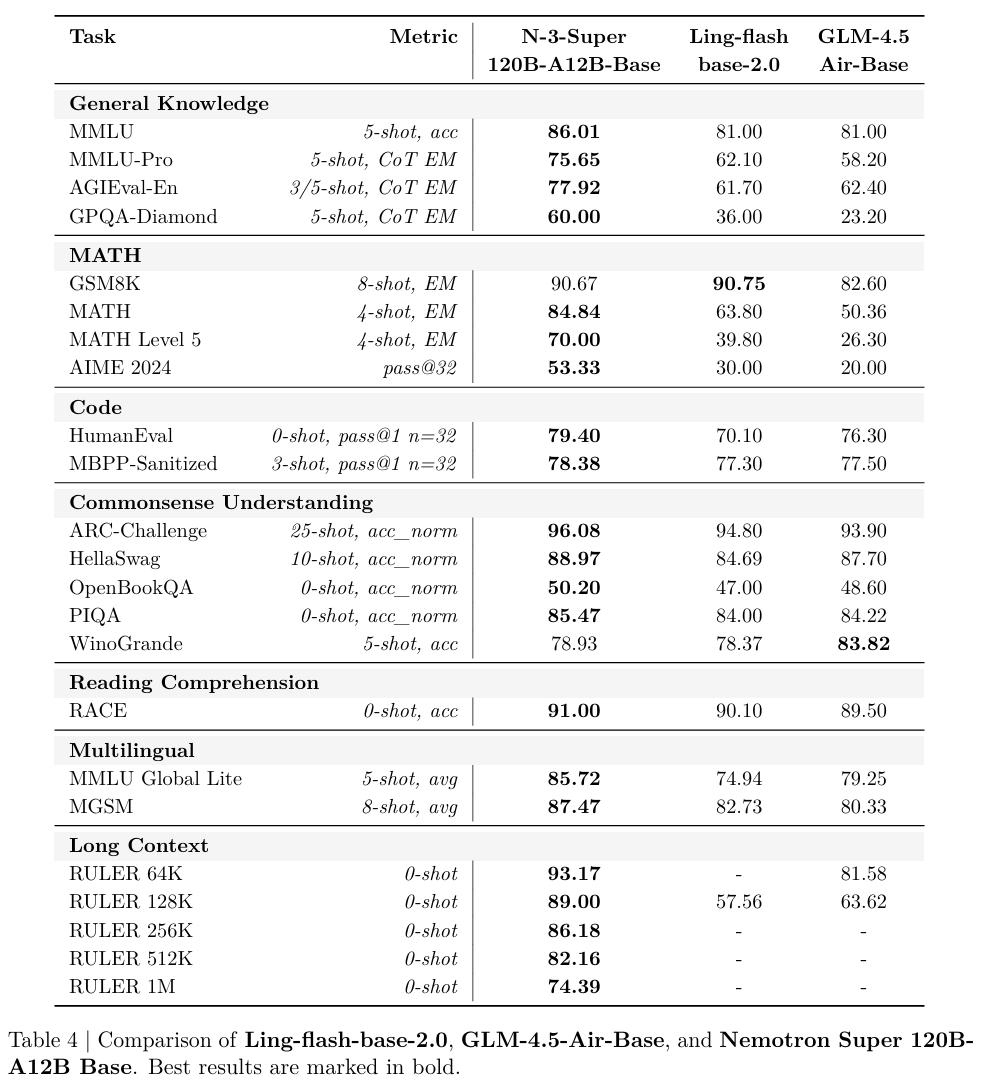
最终练出来的「基础模型」,在MMLU上跑到86.01,MMLU-Pro 75.65,MATH 84.84,把同等体量的顶流模型远远甩在了身后。
后训练方面,英伟达更是把技能点狠狠点在了「AI智能体能力」上。
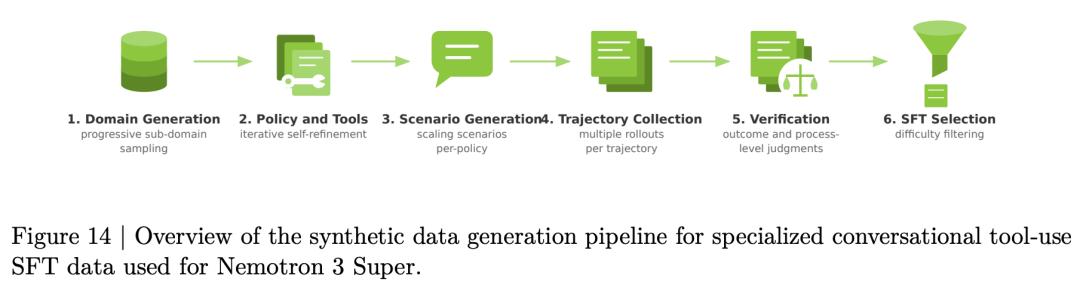
SFT阶段,训练了超过700万样本、800亿token。数据混合中,Agent相关任务占比高达36%,远超对话(23%)和推理(31%)。
Agent训练数据的规模提升尤其凶猛。仅对话式工具调用一项,就从上一代Nano的5个领域、15,588条对话,暴涨到838个领域、279,116条对话。
RL阶段更是大手笔,分四步走:
第一步,多环境RLVR。同时在21个环境、37个数据集上训练,覆盖数学、代码、STEM、安全、对话、指令遵循、长上下文、谜题和各类Agent任务。每步采样256个prompt,每个prompt生成16个response。
第二步,SWE-RL。专门训练软件工程能力,投入20B token。每次rollout启动一个容器,在真实代码仓库中运行Agent循环,生成代码补丁后用真实测试用例验证。
第三步,RLHF。18B token,训练了一个基于Qwen3-235B的GenRM奖励模型,在身份认知和安全话题上精确调控行为。
第四步,MTP恢复。冻结模型主干,只训练MTP预测头,重新对齐投机解码的准确率。
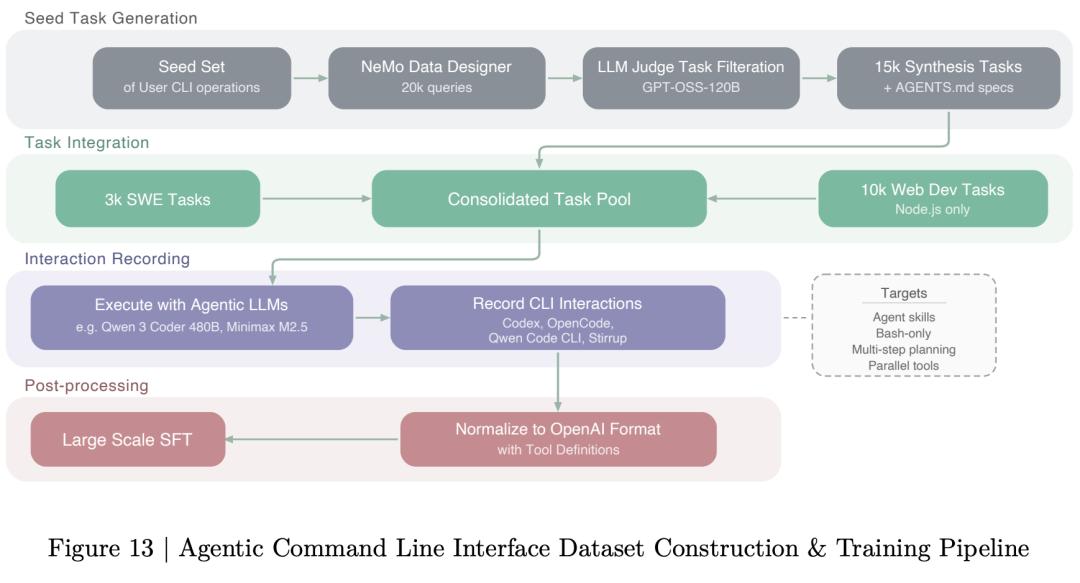
这套顶配的AI智能体训练秘籍效果如何?几个数字说明一切:
SWE-Bench(OpenHands)上拿到60.47%,大幅超过GPT-OSS-120B的41.9%;
RULER@1M长上下文测试中达到91.75%,而GPT-OSS-120B只有22.3%;
AIME25数学推理上跑到90.21%,和Qwen3.5-122B的90.36%几乎打平。
「龙虾」玩家赢麻了,数千页报告秒进内存
Nemotron 3 Super高精度工具调用能力,可以让OpenClaw智能体在多个领域,实现跨越式进化。
在软件开发中,AI智能体可以一次性将「整个代码库」加载到上下文中。
无需繁琐的文档切分,即可实现端到端的代码生成、漏洞修复与自动化调试。
在财务分析场景下,Nemotron 3 Super可将长达数千页的报告直接加载到内存中。
这样一来,直接省去了在冗长对话中反复重新推理的麻烦,大幅提升了工作效率。
凭借工具调用能力,Nemotron 3 Super还能让自主Agent在庞大的函数库中可靠地导航操作,防止在诸如网络安全领域的自主安全编排等高风险、关键环境中出现执行错误。
如今,一大批玩龙虾的人,可以直接用上了。
目前,Perplexity已接入Nemotron 3 Super供用户进行搜索,成为Computer中的20个编排模型之一。
还有CodeRabbit、Factory、Greptile提供软件开发AI智能体的公司,已将其与自家模型集成到AI智能体中。
Edison Scientific和Lila Sciences等生命科学与前沿AI机构,也将用Nemotron 3 Super为其智能体提供算力支持,用于深度文献检索、数据科学及分子结构理解。
英伟达版OpenClaw,要来了
光有模型还不够,英伟达这次连平台都一起端上来了。
据WIRED爆料,英伟达正在秘密打造一款名为NemoClaw的开源AI智能体平台,专门面向企业市场。
听这名字就知道,「Nemo」对应Nemotron模型家族,「Claw」直指OpenClaw。
翻译成人话就是,英伟达要用自家模型,造一个企业级的OpenClaw。

跟OpenClaw的最大区别在哪?安全。
OpenClaw在个人玩家手里玩得风生水起,但企业根本不敢碰。NemoClaw就是冲着这个痛点来的。
据报道,NemoClaw从一开始就内置了一套安全和隐私工具,给企业吃定心丸。
而且它是完全开源的,不管你的系统跑的是不是英伟达芯片,都能用。
为什么要开源?逻辑很简单。智能体用得越多,算力需求越大,英伟达照样赚。
Nemotron 3 Super是引擎,NemoClaw是底盘。模型+平台,双管齐下。
英伟达这次要给企业递上一套「开箱即用」的AI智能体全家桶。
OpenClaw让个人玩家尝到了甜头,但企业市场这块蛋糕,英伟达显然不打算让给任何人。
参考资料:
https://blogs.nvidia.com/blog/nemotron-3-super-agentic-ai/
https://wccftech.com/nvidia-unveils-nemotron-3-super-as-an-open-agentic-ai-model/
https://research.nvidia.com/labs/nemotron/files/NVIDIA-Nemotron-3-Super-Technical-Report.pdf
https://pinchbench.com/
