

2026 年 3 月 16 日,Kimi 团队把一篇叫 Attention Residuals 的论文挂上了 arXiv,然后事情迅速失控。马斯克转发了,Karpathy 评了一句“我们还没有真正把 Attention is All You Need 的标题当回事”,前 OpenAI 联合创始人 Jerry Tworek 直接给了四个字,deep learning 2.0。一篇来自中国团队的架构论文能在硅谷引起这种级别的讨论,上一次可能要追溯到 DeepSeek-V3。
但热闹归热闹,大多数讨论停留在“Kimi 搞了个新东西,大佬们很兴奋”的层面。被忽略的是,同一天,字节跳动 Seed 团队和华中科技大学联合发了另一篇论文,叫 Mixture-of-Depths Attention(MoDA),解决的是完全相同的问题,用的是完全不同的路线。同一周内,南京大学 Dilxat Muhtar、MPI Shiwei Liu 等人的第三篇论文“When Does Sparsity Mitigate the Curse of Depth in LLMs”从理论侧给出了最精确的病理报告。
三篇论文密集出现,对准的是同一个靶子。这不是巧合。一个被忽视了近十年的结构性问题,终于到了不得不解决的临界点。
问题不在注意力的序列维度上。注意力在过去几年已经进化了很多代,从多头注意力到分组查询注意力,到 DeepSeek 的 MLA,到各种稀疏变体,每一代都在优化 token 与 token 之间怎么互相看。这场军备竞赛足够精彩,但它遮蔽了一个事实——层与层之间的信息传递方式,从 2017 年 Transformer 论文发表至今,答案一直是同一个。残差连接,h = h + f(h),一个不带任何学习参数的加法操作。
所有历史层的输出等权求和。没有选择,没有遗忘,没有学习。每一层的贡献被一视同仁地堆进残差流里,不管它学到的是关键特征还是噪音。
残差连接是深度学习历史上最成功的“临时方案”。
最成功的临时方案
残差连接是 2015 年何恺明在 ResNet 里提出的。思路极其朴素,网络堆到二十几层就训不动了,梯度消失让深层参数几乎不更新,那就给每一层加一条“高速公路”,让输入直接跳过这一层接到输出上。即使这一层什么都没学到,信息和梯度至少能通过这条捷径传下去。效果立竿见影,ResNet 把网络从二十几层推到了一百多层。两年后 Transformer 问世,残差连接被原封不动地搬过来。从那以后,这个设计就没人动过。
不是没人试过。ReZero、FixUp、Highway Network 都做过变体,让残差权重可学习。但没有一个进入主流大模型的架构选型,因为残差连接太好用了。简单、稳定、几乎不增加计算开销,在当时的模型规模下,副作用还没有暴露。
44% 的层在空转
副作用是什么?2025 年初,西湖大学、Emory 和 MPI 的 Shiwei Liu 团队发表了“The Curse of Depth”,今年 3 月南京大学 Dilxat Muhtar 等人的“When Does Sparsity Mitigate the Curse of Depth in LLMs”进一步给出了定量诊断,在当前主流大模型的架构下,深层的变换越来越接近恒等映射。输入什么就输出什么,这一层等于没有。
数字很难看。研究者用“有用性分数”来衡量每一层是否在做有意义的变换。12 层的模型,所有层都在干活。16 层,三层废了。24 层,九层废了。32 层,14 层废了,44% 的层几乎什么都没学到。参数量从 9 亿增加到 23 亿,多花了 156% 的预算,有效层只从 12 增加到 18。
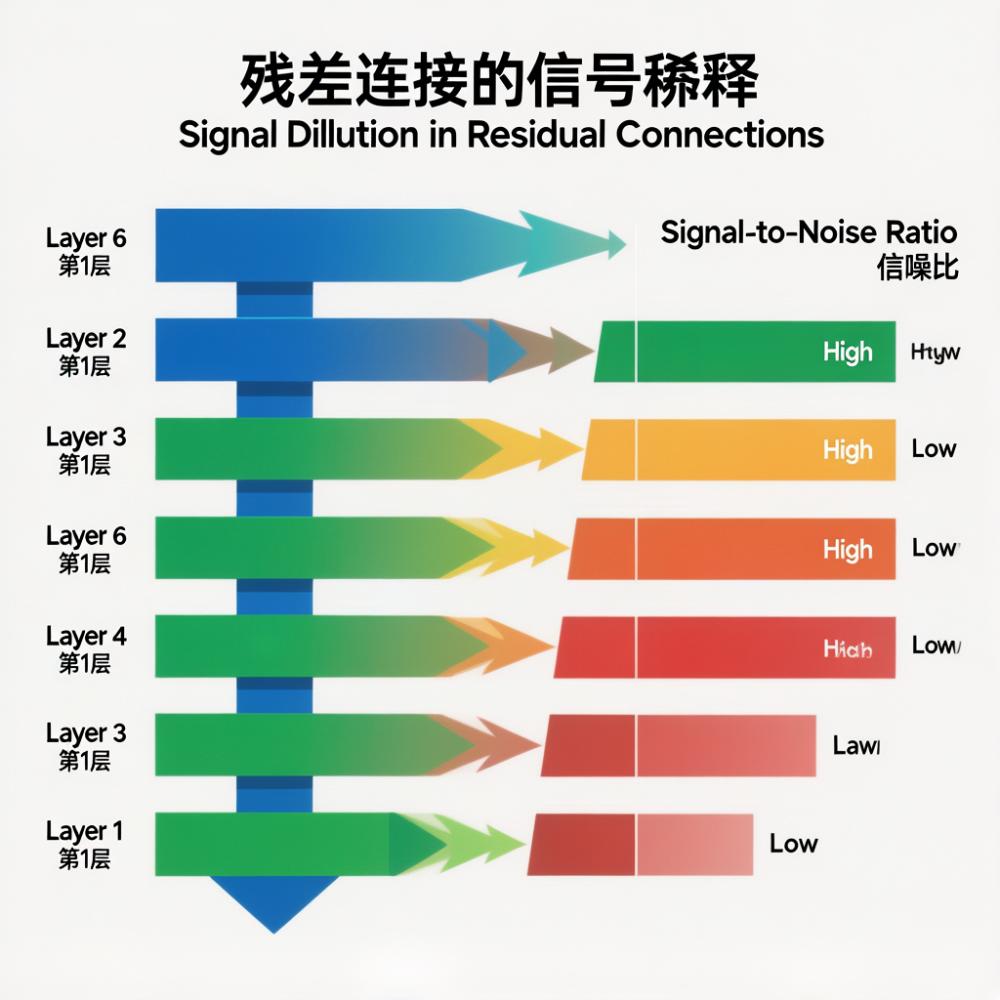
图 2|深度诅咒的定量诊断——有效层数随模型规模增长的效率递减 该图片属于AI生成
原因和残差连接的工作方式直接相关。每一层的输出通过残差连接加到一条“主干道”上。随着层数增加,主干道上累积的信号越来越大(可以理解为“背景音量”不断升高),但每一层新产生的信号幅度是有限的。到了深层,新信号就淹没在背景噪音里了,输入和输出几乎一样,这一层形同虚设。
残差连接解决了“让梯度传过去”的问题,但制造了“让深层有意义”的问题。
在大模型时代,这个代价是真金白银。一层就是几十亿次浮点运算。一个 128 层的模型如果有 44% 的层在空转,将近六十层的算力在做无用功。社区卷了几年的推理效率优化,量化、蒸馏、剪枝、稀疏注意力、KV cache 压缩,全都在优化那些“有用的计算”。
最大的效率黑洞不在注意力的二次方复杂度上,而在一个从 2015 年就没变过的加法操作上。
不修旧路,另开新路
字节跳动 Seed 团队和华中科大的出发点不是“残差连接坏了,得换掉”。他们的问题问得更直接——注意力机制已经能让 token 之间互相看,为什么不能让它同时也看到深度方向上的信息?
传统注意力只有一个维度——序列维度。第 20 层的某个 token 在做注意力计算时,只能看到同一层内其他 token 的信息。它看不到自己在第 3 层、第 10 层时的状态,哪怕那些浅层学到的特征对当前计算非常有用。这些浅层特征确实还在残差流里,但已经被十几层的残差更新反复叠加、逐渐稀释了。深层想用浅层的特征,只能用这杯被稀释了十几次的“兑水果汁”。
MoDA 的做法是给注意力加上第二个维度——深度维度。每个注意力头在做正常的序列注意力(token 看 token)的同时,也做一个深度注意力(直接去前面所有层取原汁原味的 KV 对)。两路信息在同一个 Softmax 下联合归一化,模型自己决定是该多看看当前层的上下文,还是该回头翻翻浅层学到的特征。残差连接还在,没有被替换,但深层不再只能依赖它来获取浅层信息了。
想法不难理解,难的是怎么在不拖垮速度的情况下把它做出来。
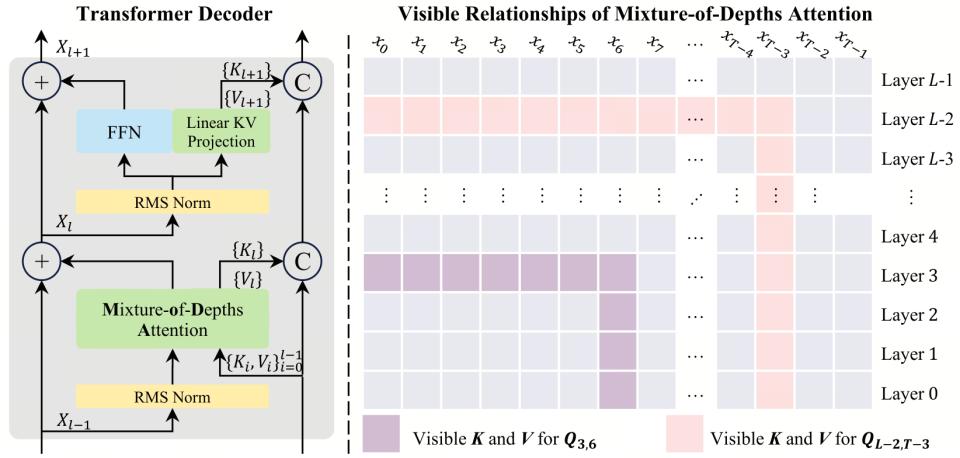
图 3|MoDA 的双维注意力机制——序列维度与深度维度在同一个 Softmax 下联合归一化
把散落的档案搬到工位上
问题出在 GPU 的内存访问模式上。正常的注意力计算,所有 KV 对都来自同一层,在显存里是连续存放的,GPU 读取效率很高。但 MoDA 需要从前面所有层去取 KV 对,这些数据散落在显存的不同位置上。GPU 最怕的就是这种“东一块西一块”的随机读取,速度会断崖式下降。如果天真地直接拼接所有历史层的 KV,一个 48 层的模型,每一层的注意力计算都要去翻前面 47 层的“档案”,内存访问几乎全是随机的,训练速度会被拖到不可用。
MoDA 的解法叫分组重排(Grouped Rearrangement)。核心思路是,既然随机访问慢,那就在计算之前先把数据重新排列成连续的。
做法分两步。第一步,把当前层的查询(Query)按固定大小分成若干组(比如每组 64 个 token)。第二步,对每一组,把它需要看的深度 KV(来自前面所有层的 KV 对)从散落的显存位置搬到一块连续的内存区域里,重新排好,然后一次性做注意力计算。你可以理解为,不是让工人跑遍整条流水线去翻档案,而是先让一个助手把他需要的档案都搬到他工位旁边的桌子上,摆好,他坐着就能翻。搬运的成本远小于反复跑腿的成本。
这个设计的关键在于分组的粒度。组太大,每组需要搬运的深度 KV 太多,搬运本身变成瓶颈。组太小,GPU 的并行计算能力用不满。MoDA 选择了和 FlashAttention(目前业界标配的高速注意力计算引擎)相同的分块大小,这样深度注意力的计算可以直接复用 FlashAttention 的底层实现,不需要写一套全新的 GPU 算子。
在 64K 序列长度下,MoDA 的算子效率达到了 FlashAttention-2 的 97.3%。加了整个深度注意力机制,速度只慢了不到 3%。

图 4|分组重排策略——把散落在显存各处的历史层 KV 搬运到连续内存区域
这个数字的含义是,深度注意力不是一个轻量级插件,它让每一层都需要读取所有前序层的 KV 缓存。如果工程做得粗糙,这种跨层的数据依赖会把训练速度拖垮几倍。MoDA 把额外开销压到了 3.7% 的 FLOPs 增量,说明分组重排策略确实把随机访问的问题解决得很干净。
3.7% 的代价,2.11% 的收益
在 1.5B 参数的模型上(基于 OLMo2 的训练配方),MoDA 在 10 个下游任务上的平均性能提升了 2.11%,额外计算开销仅 3.7%。初看不大,但这是架构层面的改进,不是靠更多数据或更长训练堆出来的,会随着规模放大持续生效。而且任务之间差异很大,常识推理(WinoGrande)提升 2.37%,科学推理(ARC-Challenge)提升 4.35%,需要跨层特征整合的任务收益明显更大。

图 5|MoDA 在 10 个下游任务上的性能对比
Pre-Norm 欠下的债
MoDA 论文里最有价值的可能不是 MoDA 本身,而是一个关于归一化策略的实验。
这里需要解释一下背景。Transformer 的每一层做完计算后,都要经过一步叫“归一化”(Normalization)的处理,作用是把数值范围稳定住,防止训练过程中数字爆炸或者消失。这步处理放在哪里,有两种主流做法,放在每一层计算之前,叫 Pre-Norm(也叫 Pre-LN);放在计算之后,叫 Post-Norm(也叫 Post-LN)。2020 年之后几乎所有大模型都用 Pre-Norm,因为它让训练更稳定,不容易崩。但前面说的“深层空转”问题,恰恰就是 Pre-Norm 的副作用。Pre-Norm 为了稳定训练,实际上是在不断稀释深层的信号强度。
MoDA 的实验做了两组对比,在 48 层的模型上,分别用 Pre-Norm 和 Post-Norm,然后在每组上加入 MoDA 的深度注意力。Post-Norm 配置下,加入深度 KV 带来了 0.0409 的验证损失降低;Pre-Norm 只有 0.0041,差了将近十倍。
这个数据说明的事情比 MoDA 本身更大,即,Pre-Norm 不只是在“稳定训练”,它同时在系统性地压制深层的学习能力。过去大家不敢用 Post-Norm,是因为训练不稳定,梯度容易爆。但 MoDA 的深度注意力提供了一条全新的梯度通路,让梯度不用完全依赖残差连接来传递。有了这条新通路,Post-Norm 原本的不稳定问题就不再是致命伤了。
MoDA+Post-Norm 的组合打开的可能性是,过去为了训练稳定而做出的妥协(用 Pre-Norm),也许可以被收回了。
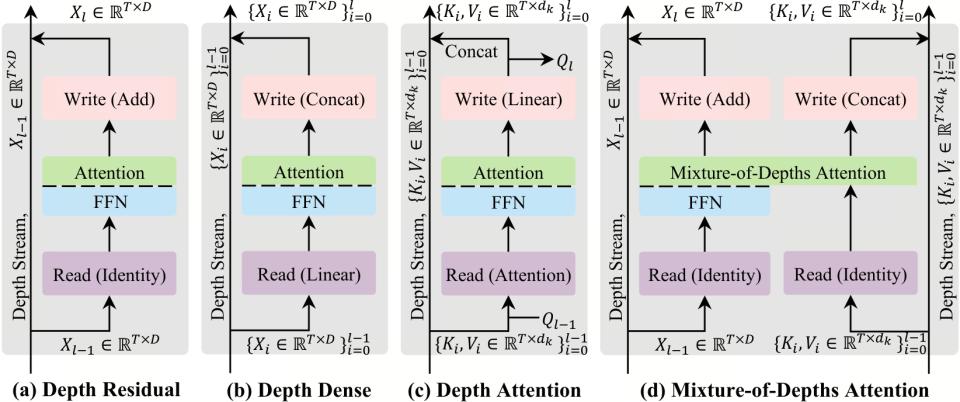
图 6|Pre-Norm vs Post-Norm 在加入深度 KV 后的验证损失差异
不开新路,翻修旧路
MoDA 没动残差连接,它选择在残差之外另开一条路。同一天,Kimi 团队发的 Attention Residuals(AttnRes)走了一条更直接的路线,直接对残差连接本身动手。
标准残差连接做的事很简单,把前面所有层的输出等权相加,堆进主干道。没有选择,没有遗忘。AttnRes 把这个固定的等权加法替换成一个注意力操作,每一层用自己的状态作为查询,前面所有层的输出作为候选,用注意力来决定,前面哪些层的特征对当前层有用,权重各是多少。
残差连接从一个固定公式变成了一个可学习的动态路由。
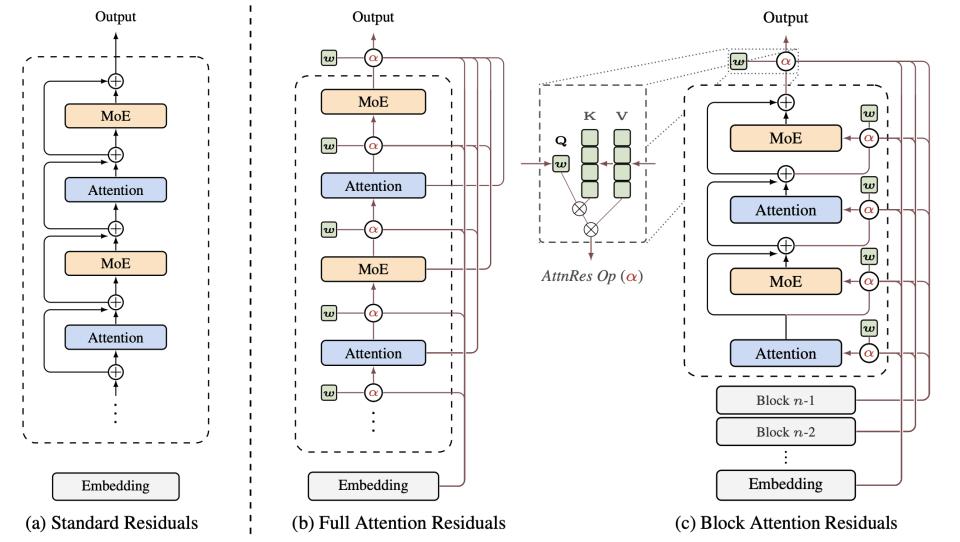
图 7|AttnRes 的核心思路——用注意力替代等权残差加法
代价是每一层都要额外跑一次深度注意力计算,开销不低。Kimi 团队用分块策略(Block AttnRes)控制成本,把层分成若干个块,块内做完整的深度注意力,块与块之间只关注块级别的聚合表征。
AttnRes 已经被集成进了 Kimi Linear(480 亿总参数 / 30 亿激活参数),在 1.4 万亿 token 上做了预训练,效果确认在不同模型规模下一致。这篇论文已经被广泛报道过,技术细节不再展开。值得放在这里讲的原因是它和 MoDA 的路线对比。
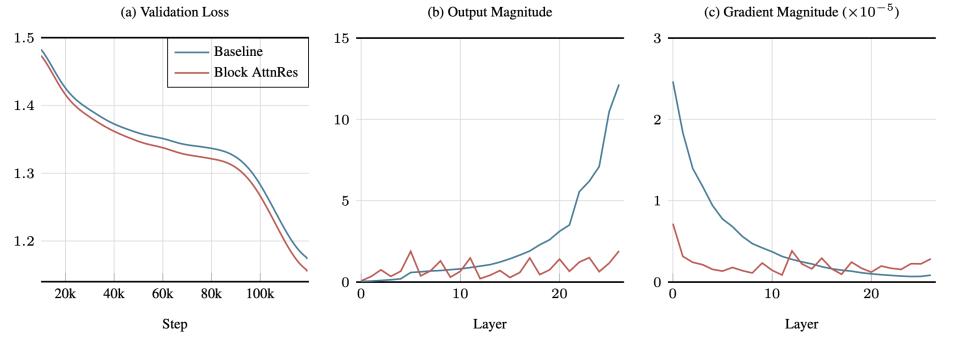
图 8|AttnRes 的训练曲线与消融实验
两条路线诊断的病因完全一致,即,深层拿到的浅层信息被残差更新反复稀释了。但下刀的地方不同。MoDA 没碰残差连接,而是给注意力加了一个深度维度,让深层能绕过残差流直接取浅层的原始特征。AttnRes 直接对残差连接开刀,把等权加法换成了注意力加权。一个是“另修一条路”,一个是“把原来那条路翻新”。
两篇论文同一天出现,路线不同,靶子相同。这不是巧合。注意力的深度问题已经是研究社区的共识,区别只在于从哪个方向切入。
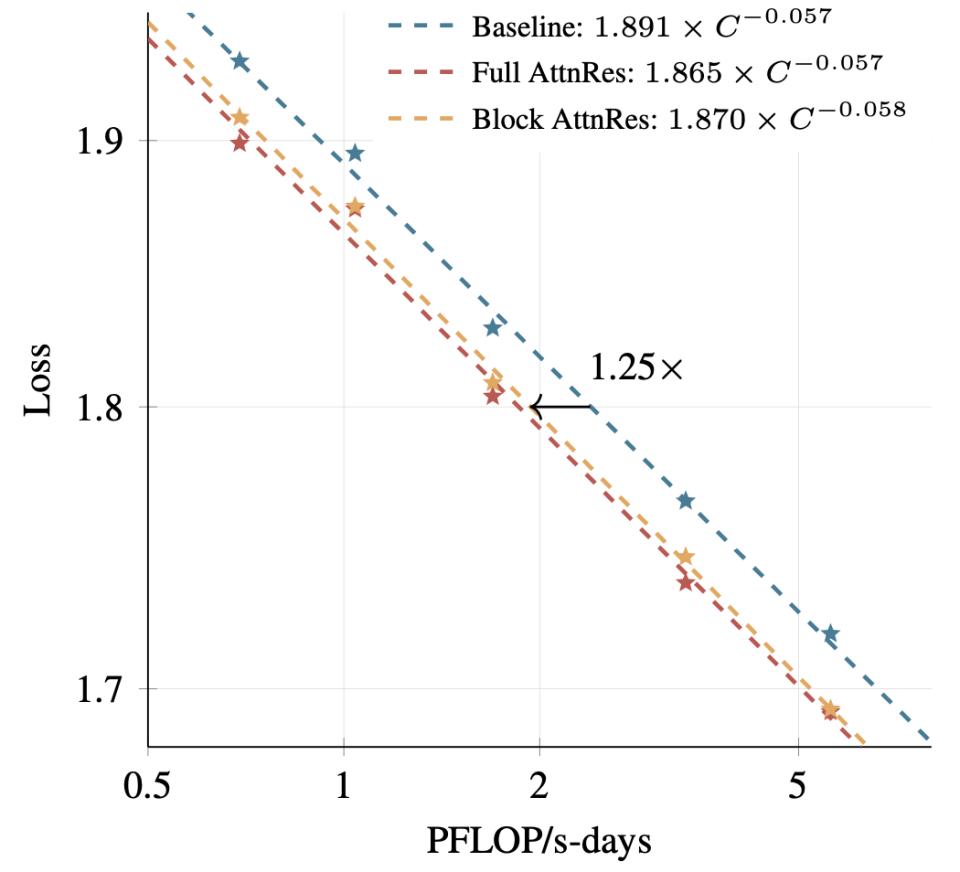
图 9|AttnRes 在不同模型规模下的效果一致性
忘了拆的“脚手架”
回到最开始的问题,为什么深层空转这个问题到 2026 年才被认真对待?
因为残差连接太好用了。它解决了一个当时最紧迫的问题(梯度消失),代价可控(深层退化在小模型上不明显),替代方案不成熟(ReZero、Highway Network 都没有经受过大规模验证)。没有人有动力去动它。它不是被有意保留的设计选择,而是被遗忘的临时方案。当初搭的脚手架,盖完楼忘了拆,时间一长大家以为它是承重墙。
图 1|残差连接的信号稀释效应——层数越深,新信号越难被听见 该图片属于AI生成
但真正让这个问题难以被发现的,不是残差连接本身,而是注意力机制长期以来只在一个维度上运作。过去八年,注意力的所有进化——多头、分组查询、稀疏、线性——都是在序列维度上做文章。token 和 token 之间怎么互相看,这件事被优化了无数遍。但层和层之间怎么互相看?这个问题根本没人问过。深度维度是注意力的盲区。
MoDA 和 AttnRes 从不同方向把这个盲区打开了。MoDA 给注意力加了第二个维度,让它能同时在序列和深度方向上运作。AttnRes 把层间信息传递本身变成了一个注意力操作。路线不同,但共同指向同一个结论,即,注意力不该只看水平方向,它也应该看垂直方向。
这个结论的延伸比两篇论文本身更大。Transformer 里还有很多只在单一维度上运作的固定机制。每一层必须按顺序执行,不能跳过。每个注意力头独立计算后简单拼接,没有头与头之间的动态协调。每个 token 无论难易都走完全相同的计算路径。这些设计当初都是为了让模型能训起来、能收敛的工程妥协。
深度学习过去十年的演进方向,如果抽象到最高层,就是一件事,把越来越多的结构性决策从人类设计者手中交还给模型自己。手工设计的卷积核被可学习的注意力替代了。固定的位置编码被可学习的旋转编码替代了。固定的专家分配被可学习的路由替代了。现在,深度维度上的信息流动方式,也开始由注意力自己来决定了。
Karpathy 说我们还没有把“Attention is All You Need”的字面意思当真。他可能说对了。但不是“注意力就够了”这个意思,而是“注意力还没有被用够”。它在序列维度上已经进化了很多代,但在深度维度上才刚刚开始。
深度是注意力的下一个战场。
