

上周,DeepSeek V4发布,朋友圈立刻刷屏。
这次DeepSeek,依旧奔着把国产AI水平推一大截来的。据报道,它的推理性能,比肩Chatgpt和Gemini。编程任务,表现接近Opus 4.6。虽然有1.6万亿参数,但只动用了同行1/4GPU。
厉害。但我觉得,这次DeepSeek发布,最值得注意的,或许不是上边这些让人眼花缭乱的模型能力,而是官宣文章配图下的,一行小字:
受限于高端算力,目前Pro的服务吞吐十分有限,预计下半年昇腾950超节点批量上市后,Pro的价格会大幅下调。
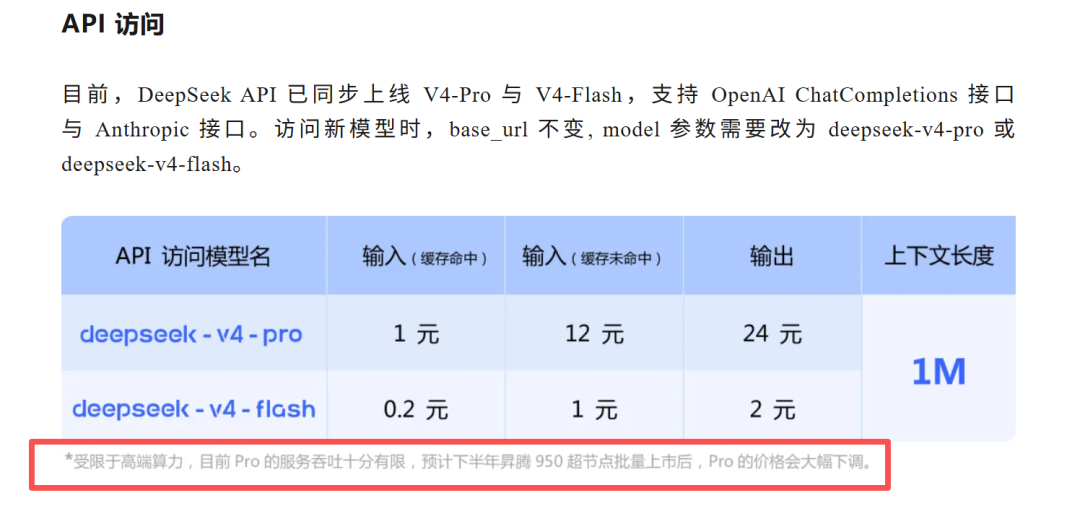
(位置大概在这里)
意思就是:API贵,是因为芯片不够。等下半年华为的芯片出货,价格就能降下去了。
这有什么?不就是没办法了吗?拿不到高端芯片,只能等国产顶上呗。
其实,不是的。早在两个月前,路透社就有报道:
DeepSeek,未向美国芯片厂商提供模型用于性能优化,而是优先向华为等本土厂商开放早期访问权限。
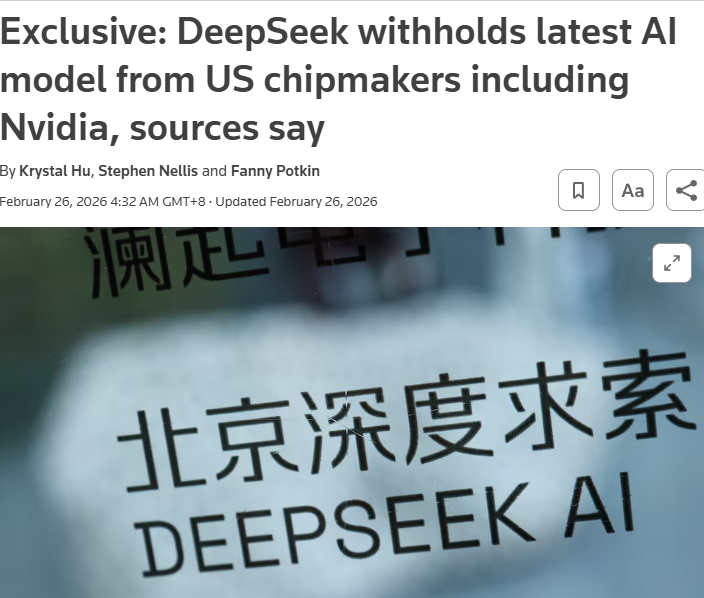
明明可以选择现成的方案,但DeepSeek没有。
所以,这不是很多人以为的“不得不”,这更像是一次“主动押注”。
这中间,发生了什么?

01
DeepSeek,是一个倒逼芯片互联的模型
这要从DeepSeek的技术路线说起。
它的技术路线,是MoE(Mixture of Experts),专家混合。
什么意思?我打个比方。
你突发头痛,去医院看病。你当然希望看病的医生,懂得越多越好。内科、外科、心血管、脑神经,全都精通。但问题是,要培养这样的全科医生,成本太高。每个医生,可能要花30年才能毕业。
问传统大模型问题,就像向全能医生问诊。无论什么专业问题,它都调动全部参数回答。虽然省心强大,但也很贵。
怎么办?DeepSeek换了个思路。
它没有训练一个什么都懂的全科医生,而是训练了多个专科医生。外科只管外科,内科只管内科。然后,设一个导诊台。你问问题,导诊台把问题分配给负责的医生,其他医生待命。
这就是:混合专家系统(MoE)。它虽然拥有巨大参数作为知识储备,却可以针对不同问题,激活部分参数干活。
所以,DeepSeek官方介绍才会这么说:
DeepSeek-V4-Pro总参数1.6T、激活参数49B,DeepSeek-V4-Flash总参数284B、激活参数13B。

拿V4-Pro举例,就是:参数总量1.6万亿,但每次问答激活490亿。
不过,MoE架构虽然神奇,但也有限制。比如:All-to-All通信。
几百个专科医生,如果想要顺利协作,就需要导诊台把病人快速分发到不同科室,再把结果汇总回来。用专业术语来说,就是All-to-All通信。每颗芯片,都要随时跟其他芯片说话,稍有延迟,效率就会大幅降低。
Moe的核心,是用通信换算力。通信跟不上,延迟就会成为瓶颈。
那么,如何把芯片间的通信做好?
02
英伟达的NVL72,碰到了铜缆的物理极限
英伟达说,芯片通信?我拿手啊。我还有套专门的技术:
NVLink。
NVLink,是英伟达的GPU连接协议。它能让GPU和GPU之间的传输速度达TB级,半秒就能搬空你主力电脑里的所有资料。英伟达的主力产品NVL72,就是靠这种技术,才把72颗芯片连成一个计算单元的。
那DeepSeek要不要用它提供算力呢?
理论上或许行,但实际上并不容易。这种顶级算力设备,会受美国出口管制。而且,作为MoE架构模型,同时参与的芯片越多,DeepSeek跑得越好。面对海量用户请求,72块芯片,可能还不够。
但依靠之前的方案,英伟达很难增加并行芯片数量。因为:铜缆。
如果你打开NVL72后盖,你会看到一个由几千根铜缆,编织而成的密网。总长度数公里,是机柜重量超过一吨的重要来源。

为什么这么麻烦?
在每秒上TB的数据传输下,铜缆信号的有效传输距离,可能还不到1米。再加芯片,要么机柜塞不下,要么铜缆够不着。靠普通网线,带宽延迟又成了问题。换句话说,目前密密麻麻的铜缆,已经逼近了物理上限。
怎么办?华为想到一个办法:光。
03
华为用光,把384颗芯片变成了一颗“超级芯片”
比起铜缆,光纤至少有2个核心优势。
1、传得远。
铜缆传不远,因为电信号传输越高速,损耗和干扰也会同步增加。但光子相对不受电阻电磁干扰,哪怕几百米传输依然稳定,让GPU跨机柜分布成为可能。
2、带宽高。
但光纤,可以同时传输多个波长的光信号,相当于一条路上开多个车道,互不干扰。所以,光纤的带宽,理论上能轻松达到几Tb每秒,甚至更高。
确实优势很大。可是,全世界的机房不都在用光纤吗?我家的宽带都是光纤的,华为用光有什么厉害的?
区别就在于:用在哪。
你家宽带的光纤,是从小区到楼栋,偶尔断几秒你感觉不到。数据中心的光纤,是从一个机柜到另一个机柜,断一下业务自动切换,你也没感觉。
但华为把光用在了芯片与芯片间的通信。这就要求,几百颗芯片要在纳秒级的时间内同步数据,任何芯片掉线、延迟,就会拖慢整体效率。这种场景叫:Scale-Up(纵向扩展),把多颗芯片变成一颗“超级芯片”。
2025年7月,华为首次展出了CloudMatrix 384超节点。

这个计算单元,通过6000多个光模块,3000多根光纤,把384颗昇腾芯片连在了一起,就像一颗“超级芯片”。任何两颗芯片之间通信,延迟极低,带宽极高。
本质上,它是一个两层结构:
机柜内,GPU之间依然用铜互连,先把一组GPU变成一个小单元。机柜间用光纤连接,扩展成384卡规模。
这也是2025年9月,华为轮值董事长徐直军在大会上,所强调的:
超节点在物理上是多机柜、多个卡联接成一个超节点,但是它们能够像一台计算机一样工作、学习、思考、推理。
这只是开始。预计今年年底,华为将推出支持8192张昇腾卡互联的计算单元。未来,还会实现万卡互联。
你相信光吗?不管你信不信,华为先信为敬。
04
DeepSeek的反向适配,从去年就可以看到了
讲到这,你可能会问:
那DeepSeek又做了什么呢?只是挑了个供应商吗?
不是的。早在2025年8月,DeepSeek发布V3.1,就有这样一句话:
DeepSeek-V3.1 使用了 UE8M0 FP8 Scale 的参数精度。
UE8M0 FP8。啥意思?
模型的参数,是它的肌肉记忆。用什么格式的存储参数,几乎决定了它在芯片上跑得多快。英伟达的芯片,习惯用E4M3等格式,而华为昇腾的芯片,原生支持UE8M0格式。
这就像一个人本来的设备,都用Apple的Lightning接口。但现在,他把家里所有设备的充电口、数据线、转接头,全换成了Type-C。
看着是个小动作,但却意味着,对生态的彻底押注。
所以,才有了DeepSeek官方,在文章下边放出的一句话:

今年4月,多家外媒同时报道:
DeepSeek团队拒绝了像英伟达等芯片公司,提前介入做优化的请求,只和华为等国产公司合作,进行底层架构的优化。
这进一步说明,DeepSeek已经决意,把整个底层架构,从英伟达的CUDA,迁移到华为的昇腾芯片上。
但绕开英伟达,确实不是一个轻松的选择。
要知道,英伟达不只提供算力,还提供一整套“把算力榨干”的方法。
大多数AI模型,都运行在英伟达的芯片上。CUDA,则是英伟达配套的开发环境。他们俩,就像电脑主机和Windows操作系统。
过去十几年,全世界的AI科学家、开发者,都习惯在CUDA上,写代码、开发应用。一旦绕开CUDA,就意味着数百万行代码从头开始,意味着大量过往的经验不适配。甚至,工程能否进行下去,都是两说。
据透露,2025年年中,DeepSeek在用华为芯片训练V4的过程中,遇到了大量中途崩溃、芯片间通信速度未达预期等问题。但他们没有放弃。最终,DeepSeek-V4在昇腾上的推理速度,比迁移初期提升35倍。
据传言,梁文锋还曾说:
V4从英伟达生态搬到华为,相当于“在飞行中的飞机上更换引擎”。
05
这行小字,意味着中国的AI产业,正在迈过3道坎
现在,我们终于能知道,为什么那行小字,那么重要了。
因为它可能意味着,中国AI产业,正在迈过至少3道坎。
比如,算力坎。
过去几年,AI算力的默认逻辑,可能是:单卡更强,更有优势。
但今天,打法换了。既然AI要解决并行计算问题,那当单卡性能足够,我们能不能用系统把算力堆出来?超节点、光互连的本质,就是让很多张卡,像一张卡一样协同工作。
1个灯泡不够亮,10个灯泡放到一个灯盏里,亮度总是够的。
比如,生态坎。
英伟达最可怕的,不只是GPU强,而是用CUDA,把开发者二十多年的习惯、训练框架、调优经验,绑在了一起。换国产芯片最难的一关,是原来那套工具和经验,不能直接平移。
但DeepSeek全面支持华为芯片,意味着从今往后,你部署DeepSeek,不必依赖CUDA。国产芯片,国产工具,也能跑顶级模型。
甚至,是默认路径的坎。
未来,AI一定会逐渐走向东南亚、中东、非洲。这些地方的开发者,不会从零开始。哪个生态里的模型最多、最好用,他们就用哪个。
一旦我们的模型+芯片生态,在海外生根发芽,全球的开发者,就会基于昇腾+DeepSeek写教程、搭框架、做应用。生态,就会像滚雪球一样越滚越大,默认的标准和路径,就成了中国。
当你定义接口和标准,你就定义了竞争的方式。
今天,AI世界的权力游戏,正式进入下半场。
上半场,是拼谁先把模型做大,拼谁先把GPU堆满。下半场,是拼谁能用最低的成本、最自主的生态,把AI能力像水电煤一样输送出去。
在这条路上,DeepSeek走出了最关键的一步。
这一步,价值连城。
参考资料:
1、DeepSeek-V4 预览版:迈入百万上下文普惠时代
2、关于DeepSeek-V4,普通人可以知道的6件事
3、一文读懂DeepSeek V4:1.6万亿参数、百万上下文、华为芯片
4、AI算力扩容的新瓶颈竟是铜缆,英伟达押注光互连
5、一次搞清楚:光通信、光模块、光芯片、CPO是什么 | ETF风向标
6、超节点+集群,中国重新定义“算力竞争”丨新经济观察
7、这个不起眼的赛道,像极了爆发前夜的光模块!
9、华为首次展出“算力核弹”真机,获评镇馆之宝
