

这还上什么班啊,中一签就能挣几十万。
上周三,沐曦股份登陆科创板,开盘暴涨超568%,市值瞬间突破3000亿元。1.9万股民集体狂欢,因为中一签就能暴赚30万,这要比前几天上市的摩尔线程还要夸张。当下,两家公司市值合计超6000亿元,整个资本市场洋溢着一股近乎狂热的乐观气息。
更令人兴奋的是,就在沐曦上市的同一天,壁仞科技传来港股IPO已通过聆讯的消息,最快2026年初挂牌。这相当于给了前两次没赶上的投资者第三次机会,国产GPU板块即将掀起新一轮高潮。中国GPU的春天,似乎终于来了。
但冷静下来看,这场国产GPU的狂欢,似乎只有投资者赚得盆满钵满。
根据招股书中披露的财务状况显示,摩尔线程、沐曦、壁仞目前均处于大额亏损状态。其中,摩尔线程2025年前三季度亏损7.24亿,沐曦为3.46亿,壁仞在今年上半年亏损为16.01亿。更重要的是,目前三家公司都处在加大研发的阶段,商业化也都刚刚起步,根本不存在短期盈利的可能。
可在投资者眼中,这点亏损根本不算事。
因为三家公司的GPU可是AI时代的硬通货。从2023年大模型热潮爆发以来,全球算力供不应求。最大受益者英伟达在每个报告期都赚爆,成为人类历史上市值最高的公司。各大投行打着计算器,接连给国产GPU画出大饼——补充英伟达供给缺口+国产替代红利,市场空间数万亿简直就是洒洒水。
短期业绩兑现不了?没关系,AI圈这样的例子比比皆是。国内的寒武纪,靠着订单预期就让市值重回5000亿;国外的甲骨文,应了OpenAI的“空头支票”市值也能翻倍。
不过,公司对下一步的想法,却似乎没那么清晰。
摩尔线程上市募资80亿元,一周后就公告用不超过75亿元闲置资金买保本理财,引来市场一片争议。明明募资时说要支持各种研发目标,要锐意进取,怎么拿到钱就要“徐徐图之”了?
对此,摩尔线程向光锥智能回应称,项目实施周期为三年,资金是要根据实施结果分阶段使用的。对暂时闲置的资金进行现金管理,能整体提高资金收益。
或许是为了打消市场争议。摩尔线程在12月20日首届MUSA开发者大会上,预先公布了AI训推一体芯片“华山”和高性能图形渲染的芯片“庐山”。其中,“华山”的性能大致是在英伟达Hopper和Blackwell之间的水平。
但总之在这个狂欢的市场,谁要是说估值不合理,就显得很扫兴——反正时间会冷却一切情绪。
在这场连续的资本盛宴背后,到底还有哪些确定性?三家GPU公司,谁更接近英伟达?国产GPU,到底用得怎么样了?
摩尔线程、沐曦、壁仞
谁更像中国英伟达?
从大方向说,虽然摩尔线程、沐曦和壁仞都是国产GPU赛道,但三家公司的风格差异非常大。摩尔线程追求全功能和生态兼容,沐曦聚焦数据中心高性能计算,壁仞更喜欢拥抱“暴力计算”。
谁更像“中国英伟达”?或许没有标准答案。但摩尔线程的路径,最接近英伟达从游戏到AI的来时路。
摩尔线程创始人张建中,曾长期担任英伟达中国区高管。虽然张建中是销售出身,但销售很了解产品,也更容易实现资源整合。2020年创办公司时,摩尔线程的目标是想做“全功能GPU”,一张卡要同时扛起图形渲染、AI训练推理、视频编解码、科学计算等多重任务。
起步之初,摩尔线程的核心IP(可以理解为芯片基础设计图纸)来源于IMG授权。这里需要提一下IMG,该公司是一家位于英国的半导体IP商,手上有一些GPU的IP。虽然公司在2017年被中国方收购,但实际上运营独立。虽然摩尔线程在招股书中没有再提,但IMG对摩尔线程的影响暂时还没有定论。
对此,摩尔线程在招股书中提到在核心IP开发方面,公司已经构建涵盖单指令多线程向量计算核心、多精度张量计算核心等在内的完整体系。简单来说,就是GPU最关键的部分都是自己设计的,已经形成一套完整的自研技术体系。

摩尔线程的GPU跑起来到底如何?从参数上看,摩尔线程桌面级显卡S80对标英伟达 RTX 3060,但实际游戏效果非常不理想。根据游戏茶馆测试,在优化之后玩《黑神话:悟空》,1080P分辨率下,低特效加上打开性能档的TSR超分,帧数勉强稳定在30~40帧。对于一块功耗255W的全尺寸卡来说,玩游戏相当于打平了AMD R7核显,畅玩3A大作还有相当一段距离。
算力卡这边,摩尔线程旗舰S5000的参数表现还不错,由于算力卡更重视性能指标,算是英伟达H100的替代。摩尔线程在带宽、显存、算力表现都不错,支持主流计算精度,这代表着已经可以应用于AI大模型推训了。

或许是基于算力卡和智算集群(夸娥)的表现,摩尔线程在2025年打开了销路。招股书数据显示,摩尔线程2025上半年营收超过7亿元,远超前三年总和。“一步登天”的营收,显示出摩尔线程已经进入了新的发展阶段。
生态是摩尔线程接下来要主攻的目标。在MUSA生态大会上,摩尔线程不仅带来了个人算力平台(AIPC)的MTT AIBOOK。还有面向家庭AI NAS的MTT AICUBE。为了对标英伟达在具身智能领域的野心,摩尔线程也发布了MT Lambda具身智能的仿真训练平台、MTVERSE解决方案和具身物理仿真引擎,宣布在明年一季度全球开源MujoCo Warp MUSA。

沐曦团队核心人物出身AMD,公司成立的目标非常明确:不碰图形渲染的游戏显卡,直攻AI计算的通用GPU。
目前,曦云C500系列是沐曦主要算力硬件之一。基本参数上看,曦云C500也支持FP32到INT8的全精度混合计算,单卡算力也能达到对标英伟达A100水平,这已经算是达到行业主流使用算力卡的水平了。行业落地比较亮眼的是,沐曦已经走通了千卡集群的解决方案。对于面向AI大规模应用的算力卡来说,这代表着沐曦已经走通了大模型训推全流程。

沐曦现在最大的风险,在于生态。沐曦MXMACA软件栈,截至2025年10月22日,注册用户及实际使用客户只有150000人,网络API调用次数为1300多万次。这样的规模要走向大规模应用、对标英伟达CUDA,生态差距不是一点半点。
壁仞这边,主要是公司比较偏爱极致算力。2022年时,壁仞曾经靠首款旗舰通用GPU BR100的激进设计“出圈”过。在这块芯片上,壁仞用了数据流并行+Chiplet技术+TSMC N7工艺,达到了英伟达使用更先进的N4工艺的标称算力。整块芯片壁仞放了770亿个晶体管,数量直冲英伟达H100的80亿。
具体性能,根据官方宣称,16位浮点(FP16/BF16)算力大于1000TFLOPS。8位定点(INT8)算力大于2000TOPS。FP32等精度下更是超越英伟达A100、H100一个数量级。在商业场景的技术上,壁仞也非常喜欢“暴力计算”,公司目前在千卡集群、异构混训、光互连超节点等领域有项目落地。其推理卡壁砺110E则以1.3倍于主流方案的算力密度和70%的能耗节省,在文生图、语音识别等推理场景快速渗透。
不过,壁仞的营收规模相对比较薄弱。今年上半年,壁仞营收为5.87亿,与摩尔线程和沐曦还存在一定差距。靠“数值”赢得市场“尊重”之后,如何将技术优势持续转化成订单,是壁仞上市后相当长时间的重要课题。
国产GPU公司三条路径的差异,折射出创业者“残酷又写实”的抉择。
在英伟达一家独大的格局下,中国玩家必须对英伟达“亮剑”才能找到机会。只是其中的区别,是摩尔线程在“重走英伟达”,沐曦想做好“一部分的英伟达”,壁仞则是想做“最好的英伟达”。
在落地行业的过程中,商汤科技联合创始人、大装置事业群总裁杨帆向光锥智能表达了乐观的看法。“其实国产(GPU)正在跑出一个越来越大、越来越清晰的新兴市场领域。”
随着国产GPU逐步走向应用,中国的算力硬件大时代正在缓缓展开。
国产GPU走过市场检验期
对于一个未来可期的行业,为什么资本市场能现在给出如此夸张的估值?
一个残酷又确定的答案是:当前摩尔线程和沐曦的市值,已完全偏离正常价值逻辑。
对于科技股来说,在成长阶段采取一般是PS估值法,基础起点应该是10倍,可以理解为未来营收还有10倍的成长空间,苹果就在这个区间。对于前景特别乐观的公司,例如市场会给英伟达20倍的PS。这一数值,放在摩尔线程和沐曦身上,已经是惊人的300多倍和150多倍。
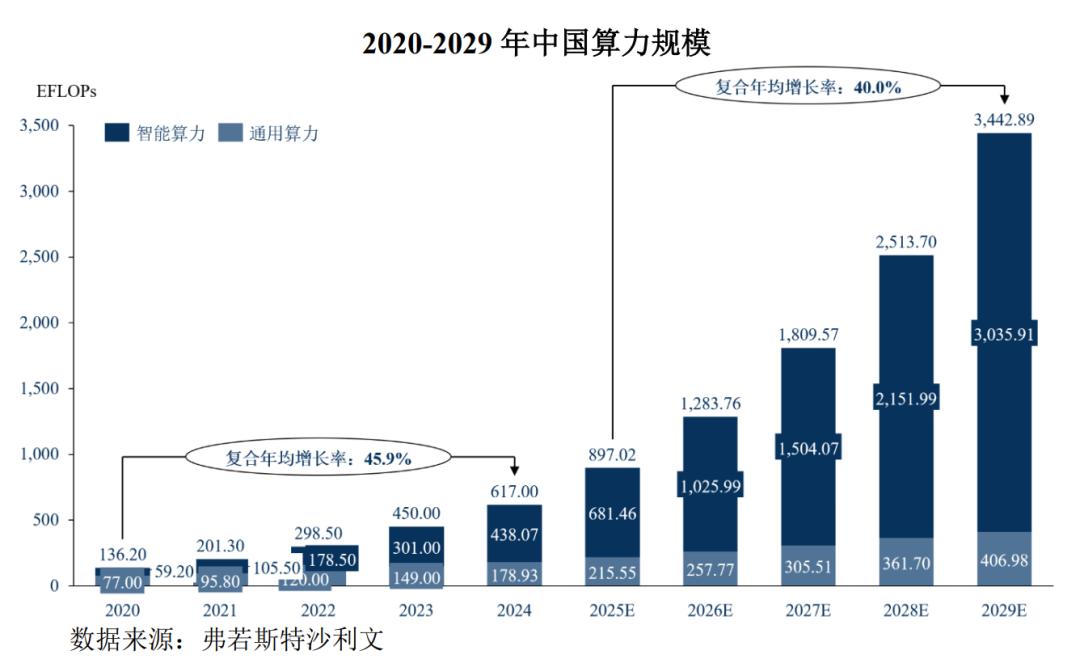
需要承认,AI算力市场的想象空间很大。根据弗若斯特沙利文预测,2029年中国算力总规模将达到3442.89EFLOPs,预测期年均复合增长率达40.0%。换算到人类历史上市值最高公司的英伟达上,那就是预期50%的增长对应43的PE,也算是基本合理。这说明,按照市场空间算,摩尔线程和沐曦的市值也是失真的。
市场哄抬两家公司市值的原因,归根结底还是因为情绪和筹码。由于两家公司在科创板上市,浮筹极少(两家流通盘都在5%左右),网下配售被险资、基金重仓,这就相当于公司市值上了一个大幅度的杠杆。再加上AI算力国产替代的宏大题材,寒武纪“造富神话”珠玉在前,这就使得投资者们愿意冒险。
至于国产GPU上市公司的利润何时能够回正?
一个好消息是,摩尔线程、沐曦、壁仞三家公司的订单和商业化都已经在2025年迎来拐点。根据招股书显示,摩尔线程和沐曦的产销率均已经超过100%,且明显好于2024年,这反映出两家公司开始进入商业化加速阶段。从合作客户看,目前国产GPU正在从早期测试逐渐转到国内头部厂商商用。
国产GPU,已经真正开始用起来了。
在三家中,摩尔线程目前的商业化情况走的相对比较通畅。根据招股书显示,摩尔线程早期几乎全部出货靠经销商,现在已经有90%能够实现直销。这代表着摩尔线程现在有能力直接完成项目,有能力对接客户需求。
目前,摩尔线程的终端客户涵盖互联网企业、AI企业、算力服务商、运营商等。向下游也很早适配了国产CPU(飞腾、海光、龙芯)、OS(麒麟、统信)、PC品牌(联想、浪潮)。对于算力硬件厂商而言,与集成商合作意味着产品可以根据需求“打包交付”。毕竟,集成商们更懂得如何与客户沟通具体的解决方案。
需要警惕的一点风险,是摩尔线程的客户比较少“续费”,营收主要靠新“大单”支撑。因为算力卡的采购不是“一锤子买卖”,客户遇到产品更新、扩容、新智算中心建设、AI大模型扩展使用等情况都会倾向购买同一品牌(考虑到产品一致性)的产品。摩尔线程今年拿到两个大单,只能证明客户开始认可产品。后续的出货稳定性,还需要持续观察。
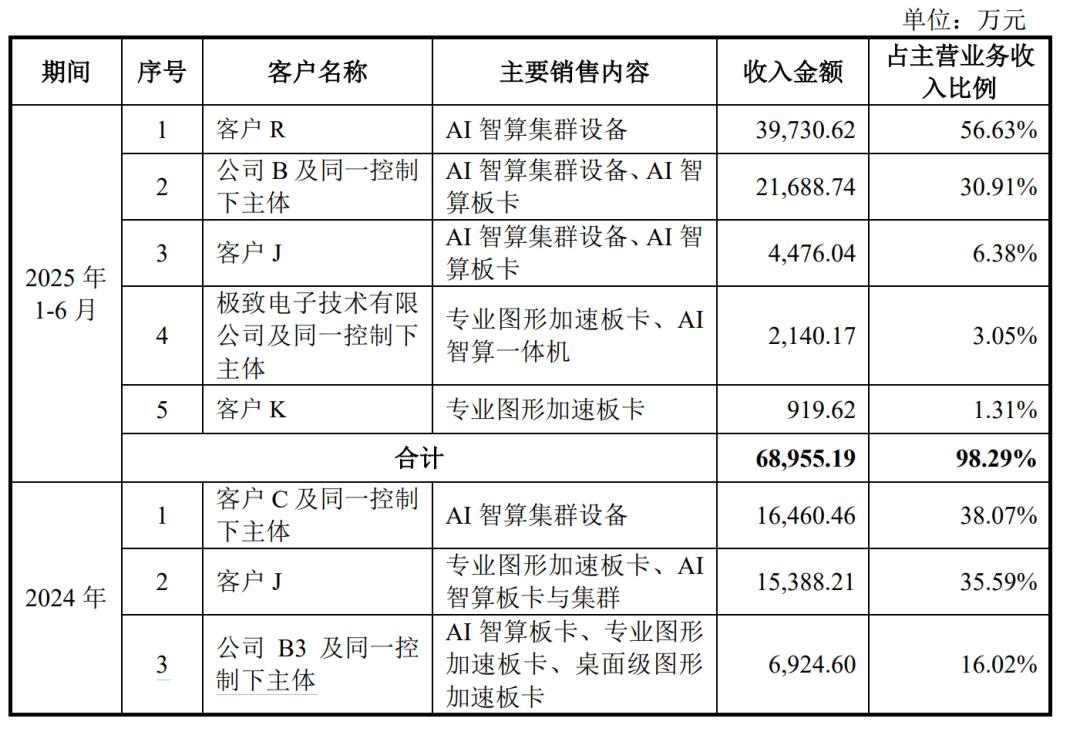
壁仞和沐曦的业绩主要来源于智算集群项目。公司客户主要为大型运营商和智算中心,产品用于大模型推训(千亿参数LLM)、科研(模型优化)和商业应用(AIGC、多模态AI)。目前,壁仞GPU已经在中国电信落地千卡集群并开展商业化落地应用。训练效果,能实现连续训练30天不中断,连续训练5天无故障,千卡集群千亿参数断点续训时间小于5分钟。已经基本满足大模型训练稳定性要求。
值得一提的是,为了弥补国产算力卡单卡性能的不足,并满足未来万卡集群和分布式AI训练的需求,壁仞拥有亮眼的超节点技术——光跃LightSphere X。技术原理上说,壁仞跟华为的超节点原理近似,都是用光信号串联GPU,实现比英伟达超节点更大规模的连接能力。与华为更注重大规模并行计算不同,壁仞超节点更关注并行计算的灵活性,通过在每个GPU集成光交换功能,实现算力卡之间的互联拓扑结构。好处简单来说,就是如果一张卡“挂了”,后面立刻就能顶上这部分工作。这对于智算中心场景来说,可谓是非常好用了。
沐曦这边,目前公司已经实现千卡规模商业化应用,正推动万卡集群落地。产品(主要是曦云C500和C600)累计销量超过2.5万颗,主要应用于国家级人工智能公共算力平台、运营商智算平台等智算项目。
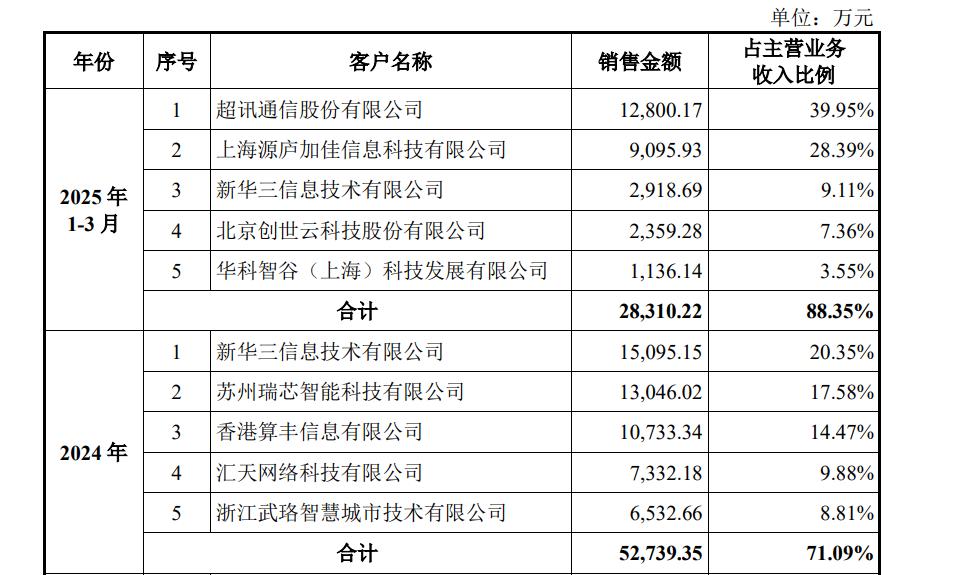
由于沐曦公布了前五大客户,所以我们能够清晰看到沐曦是以进入到下游集成商的方式实现落地。其中比较亮眼的,是沐曦出货给服务器厂商的新华三。这一方面意味着,AI服务器厂商可以用沐曦的产品“赚钱”。另一方面意味着,沐曦的商业化策略比较灵活。在今年DeepSeek刚爆发时期,沐曦就找到国内服务器一线巨头的联想推出了DeepSeek一体机。从这一举动中,能看到沐曦积极将自家产品打造成行业需求“标准件”的心态。
“早几年真的是很难用,但现在都能用了。”
正如杨帆的总结。商汤作为中国AI大模型和AI基础设施的代表,尝试过太多与国产GPU磨合。虽然与英伟达直接交手还有一段距离,但国产GPU在整个中国AI产业链的帮助下,逐步发挥应有的价值。
“任何新的任务都会存在一次性work,但现在这些任务的成本在逐步降低。如果长期跑同类型的任务的话,国产GPU在今天已经成为了一个选择。”杨帆说。
万事开头难,国产GPU也是。
结语
从2014年开始崛起,到2025年走向舞台中央,中国半导体行业走过了无比艰辛的十年。
在AI大模型“无穷无尽”的算力需求下,国产GPU迎来了最好的时代。为了填上英伟达的需求缺口,国产GPU在近几年间开始被用户愿意了解、尝试,最终走向大规模使用。
每当研究未来可期的宏大叙事,游离于行业亏损的现实和未来的梦想时,我常想起信息技术“传奇老资历”香农的逸事。
香农刚开始“炒股”时,曾读了大量价格图表、头肩顶、V字反转的“技术分析”。但最后,香农选择了基本面研究,并认为了解一家企业需要拉长时间才能判断价值,“我认为关键数据不是过去几年或几个月里股价的变化幅度,而是过去几年里企业收益的变化幅度”。
从这些上市的公司中,是否会诞生下一个英伟达?没有人敢打包票。但我们可以从现在开始拭目以待。
