

1.芯原股份拟港股上市,加速国际化布局
2.LPU 掀热潮!传英伟达即将发布,国内厂商重点布局
3.AT&T宣布投资2500亿美元,以建设美国网络基础设施
4.定点突破300万套,鉴智机器人千元级行泊一体方案即将大规模量产
5.日本订半导体新目标,2040年国产芯片销售增至5倍
1.芯原股份拟港股上市,加速国际化布局

3月10日,芯原股份发布公告,公司已于当日审议通过了关于筹划发行H股股票并在香港联合交易所有限公司(简称“香港联交所”)上市的相关议案。
根据公告,本次发行上市旨在满足公司日益增长的业务发展需求,持续吸引并集聚全球优秀的研发与管理人才,进一步强化国际化战略,并以此为契机,建立国际化资本运作平台,全面提升公司的资本实力与市场竞争力。
芯原股份表示,公司将充分考虑现有股东的利益,并结合境内外资本市场的情况,在股东会决议有效期内(自股东会通过之日起24个月内)审慎选择适当的时机与发行窗口推进本次上市工作。
公司强调,本次发行上市能否通过后续审议、备案及审核程序并最终成功实施,仍存在重大不确定性。
作为一家领先的半导体设计服务企业,芯原股份此次筹划H股上市,展现了其进一步融入全球市场、提升国际影响力的坚定决心。未来,若成功登陆香港资本市场,公司将有望借助国际资本的力量,加速技术创新与业务拓展,为全球客户提供更优质的服务。
2.LPU 掀热潮!传英伟达即将发布,国内厂商重点布局
随着AI大模型从训练阶段全面转向规模化推理,LPU(语言处理单元)成为全球算力竞赛的新焦点。近期行业消息显示,英伟达计划在GTC 2026大会推出专为推理优化的LPU新品,并将在下一代Feynman(费曼)架构中深度集成LPU核心。与此同时,国际国内芯片厂商也在同步发力,围绕低延迟、高能效推理赛道密集布局。一场由LPU驱动的AI算力变革正在加速到来。
推理时代来临,LPU成行业新风口
AI产业正在进入推理为王的阶段。实时对话、多模态交互、自动驾驶、金融高频决策等场景,对算力提出低延迟、高吞吐、低成本的需求,传统通用GPU在推理环节的效率短板日益凸显。
LPU作为专用推理芯片,接近ASIC,核心设计围绕三大要点:架构专一,面向大模型推理优化,不兼顾训练与图形渲染,极致聚焦效率;采用SRAM近存,以片上SRAM替代传统HBM作为核心存储,可大幅降低数据访问延迟,突破“内存墙”;确定性执行,采用静态数据流调度,消除延迟波动,实现毫秒级实时响应。
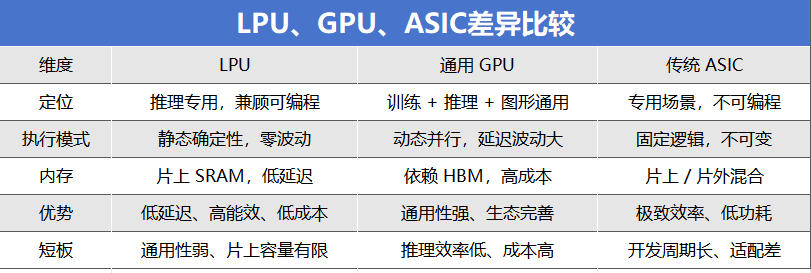
行业普遍认为,LPU将成为AI 推理的标配算力单元,是继GPU之后,下一代AI基础设施的关键芯片。
英伟达重兵押注,国际巨头同台竞技
从近期的运作来看,英伟达计划通过技术整合与产品迭代,把LPU打造为抢占推理市场的关键产品。2025年底,英伟达以200亿美元获得AI芯片初创公司Groq的LPU技术非独家许可,并吸纳其由“TPU之父”Jonathan Ross领衔的公司核心团队。
业界分析,英伟达此举的目标有两个:一是补强即时推理能力,借助Groq的低延迟,解决GPU在实时对话场景延迟高、波动大的问题。二是减轻对HBM的高度依赖:LPU的存储单元采用SRAM,而非一直供给紧绷的HBM,可以降低规模化部署门槛。
外界推测,英伟达将在GTC 2026上发布首款原生LPU推理芯片,主打边缘/低延迟场景,延迟<1ms;2026年Q3将推出Blackwell-2、GPU+LPU混合架构,推理性能提升3倍,能效比提升4倍;2028年在下一代Feynman架构上通过3D堆叠集成LPU,形成CPX(Prefill)+LPU(Decode)分工,全栈优化的推理流程。
面对英伟达的策略规划,国际大厂纷纷跟进。谷歌以TPU v4/v5为基础,内置推理专用核,依托Gemini与云服务构建封闭生态。英特尔通过Gaudi系列芯片,在推理场景下持续优化片上存储架构,抢占市场份额。AMD在MI400/500系列中优化推理模块,提升能效与延迟表现。三星在硅谷组建专门团队,研发对标英伟达LPU的AI芯片,主打边缘计算与高性价比数据中心市场。LPU已成为全球芯片巨头推理战场的必争之地。
国内厂商发力,紧跟国际前沿
这些年国内AI芯片的发展很快,紧跟国际前沿,目前有多家初创公司在技术路线上均可与Groq形成对标。

无问芯穹成立时间于2023年,创始团队来自清华大学电子工程系,核心技术路线为异构计算优化+软硬协同 (M×N中间层),不单纯依赖单一硬件架构,而是通过软件栈和编译优化技术,打通不同芯片之间的壁垒,实现算力资源的池化和高效调度。
从相似点来看,无问芯穹明确提出了LPU的概念——无穹LPU,旨在提供类似Groq的高吞吐、低延迟推理能力。其目标是让一张卡就能高效运行大模型。但无问芯穹早期更多是以IP核或解决方案的形式出现,利用其编译优化技术(M×N中间层)在异构芯片上实现LPU般的效果。它不一定像Groq那样只卖自研的独立物理芯片,而是提供一种让现有或定制芯片具备LPU能力的“软+硬”全栈方案。
后摩智能成立于2020年,核心技术路线为存算一体,通过将计算单元嵌入存储器中,大幅降低数据搬运功耗,提升算力能效比。有媒体将后摩智能称为“中国LPU的破局者”。后摩智能发布的首款存算一体智驾芯片鸿途H30,基于SRAM存储介质,最高物理算力 256TOPS,典型功耗35W。
与LPU相较,两者都是为了解决传统冯·诺依曼架构中数据搬运导致的功耗高、延迟大的问题,适合用于大模型推理。不同之处在于Groq LPU的核心是将大容量SRAM作为主存,通过编译器静态调度实现确定性执行;而后摩智能是将计算单元直接嵌入存储器,从根本上消除数据搬运。
清微智能成立于2018年,核心团队源自清华大学以及海思、英伟达、苹果、AMD等公司。核心技术路线为可重构计算。公司提出并实现了RPU架构。该架构兼具高能效和高灵活性,硬件电路可根据算法需求动态重组。
与LPU相较,两者都强调数据流驱动而非传统的指令驱动。清微智能的芯片可以通过软件定义硬件结构,动态调整计算资源,具有极高的灵活性和能效,同样能实现低延迟推理。不同点在于Groq LPU是固定的数据流架构,依赖编译器进行静态规划;清微智能的RPU具备“可重构”特性,硬件电路可以根据任务需求实时重组。
智芯科成立于2019年,核心技术路线同样为存算一体,专注于超低功耗场景。基于SRAM存内计算技术,主打精度无损和极致低功耗,主要解决端侧设备的续航和算力矛盾。与LPU相较,智芯科更侧重于端侧超低功耗场景(如智能开关、AI眼镜、玩具等),而非数据中心级的大模型推理集群。其芯片规模和通用性可能不如Groq那么大。
此外,国内还有很多厂商都在推进低延迟、高能效,降低对HBM依赖的方向进行开发,如在现有架构中增加推理专用加速核,优化SRAM调度与延迟表现,实现“LPU化”升级,包括寒武纪、华为昇腾、海光、壁仞等头部厂商。差异在于国内更侧重于成熟制程、自主工具链,并与国产大模型进行适配。
3.AT&T宣布投资2500亿美元,以建设美国网络基础设施
3月10日,AT&T宣布,将在未来五年内投资超过2500亿美元用于美国网络基础设施建设,并计划今年招聘数千名技术人员。
人工智能、云计算和联网设备的快速普及促使电信运营商大力投资光纤和5G网络,以应对来自有线宽带供应商日益激烈的竞争。AT&T在美国拥有约11万名员工,该公司表示,新招聘的员工将有助于其基础设施的建设和维护。
AT&T表示,这笔投资包括资本支出和其他支出。投资重点将放在扩展其光纤和无线网络上,包括加速部署光纤宽带、5G家庭互联网和卫星连接,以扩大城市、郊区和农村地区的覆盖范围。
“AT&T必须加大投入,但也要精打细算,它与AST SpaceMobile的合作是投资者密切关注的焦点,”AJ Bell财务分析主管Danni Hewson表示。
电信运营商竞相扩大高速连接,2019年至2023年间,AT&T在其无线和有线网络方面投资超过1450亿美元。此次投资热潮与2021年基础设施法案下设立的美国联邦宽带计划相呼应,其中包括425亿美元的宽带公平、接入和部署计划(BEAD)。然而,由于实施方面的挑战以及特朗普政府政策的变化,资金的发放遭遇了延误。
据New Street Research的数据显示,AT&T获得了BEAD光纤建设资金的最大份额,约10.6亿美元。
随着运营商和有线电视供应商竞相满足家庭互联网用户的需求,光纤宽带已成为他们争夺的关键领域。Comcast是AT&T的主要竞争对手,该公司在进行战略调整的同时,也在努力维护其用户基础。3月10日,该公司在美国哈特福德都会区和米德尔敦启动了一项耗资590万美元的网络扩建项目,预计将于今年晚些时候完工。另外,Verizon在今年早些时候完成对Frontier Communications的收购后,加快了其固定宽带的扩张步伐,并推出限时折扣套餐以吸引客户。
4.定点突破300万套,鉴智机器人千元级行泊一体方案即将大规模量产

近日,鉴智机器人(PhiGent Robotics)宣布,其基于地平线征程®6B芯片打造的PhiGo Entry行泊一体方案(含域控及一体机项目)已获得多家头部主机厂量产定点,累计总量突破300万套。这一里程碑标志着高性价比行泊一体方案正从“可选配置”转变为智能汽车的“基础门槛”,全民智驾时代加速来临。
此次大规模定点覆盖南方某合资车企、华东某国资车企、华中头部央企、北方某国资车企等多款平台化车型,充分展现了“PhiGo Entry@J6B”组合强大的市场适配性。作为地平线征程®6B芯片平台的全球首批大规模交付方案,PhiGo Entry即将进入量产阶段,彰显了鉴智机器人在中低算力行泊一体领域业界领先的产品定义与规模化交付能力。
PhiGo Entry定位为千元以内成本区间的标杆产品,堪称“行泊性价比方案样板”。该方案全面满足C-NCAP及E-NCAP最新法规标准,支持出海各区域定制化开发,可高效适配不同地区的法规细则、路况特征与驾驶习惯,为主机厂车型下沉与全球化布局提供坚实技术支撑。
区别于行业普遍的第三方软件授权模式,鉴智机器人实现了硬件、底层软件、全模块算法的自主可控与全链路自研。与征程®6B高效计算能力深度融合后,PhiGo Entry不仅突破性能瓶颈,更具备行业独有的长期可升级性,可随法规、场景、需求快速迭代,为车企提供可持续的智能化核心支撑。
作为征程®6系列面向普惠级市场的核心产品,征程®6B以极致性价比重塑主动安全新标杆。其AI芯片架构针对端到端技术优化,可实现L2级辅助驾驶(ADAS)、泊车辅助(APA/RPA)及多项主动安全功能的高度集成。
值得期待的是,双方合作持续深化。鉴智机器人基于征程6E芯片开发的PhiGo Pro强标合规行泊一体方案已完成核心开发,进入“平台复制阶段”。2026年,搭载该方案的车型将正式进入10万元最主流价格区间,让更多消费者享受到前沿智驾体验。
此次300万套量产定点的达成,释放出明确市场信号:高性价比行泊一体方案正成为智能汽车标配。鉴智机器人凭借PhiGo Entry成功定义了该细分市场的技术与产品标准,将与产业伙伴深化协同,通过可演进的技术体系与开放合作,深度参与并推动全球汽车产业的智能化进程。
5.日本订半导体新目标,2040年国产芯片销售增至5倍
日本政府10日根据首相高市早苗的成长投资策略设定新目标,拟于2040年将国内生产的半导体销售额提高至目前的5倍,借此追赶全球竞争对手,并把握人工智能(AI)热潮商机。
路透社报道,日本政府将2040年目标设定为日制芯片年度销售额达40万亿日元。 这是在2030年达15万亿日元的现行目标基础上进一步提高,目前销售额则为8万亿日元左右。
芯片是日本政府列为经济安全战略重点的数十项关键产品之一,将成为扩大公共投资的焦点以刺激经济成长。 更详细发展蓝图将于未来数月敲定,并纳入明年的预算规划。
日本1980年代在全球芯片市场的市占率高达一半,但于1990年代因美日贸易紧张及国内电子产业规模缩水而迅速失去优势。 日本如今的市占率不到10%。
东京当局指出,随着AI推动先进芯片设计与制造快速成长,日本必须积极布局,以把握这波扩张趋势。
