


文|白 鸽
编|王一粟
当月活千万的APP面临AI转型,该怎么做数据存储?
2013年成立于大湾区的货运物流App货拉拉,目前所积累的数据量已达40PB+,在整个行业中属于中等规模,“我们现在数据量增速也非常快,每一年还会增加几PB。”货拉拉大数据专家章啸说道。
如此庞大数据量,需要一个既能够稳定、安全,又能够提高读写能力的数据存储设施。
“自建的稳定性跟云的稳定性相比,还是差一些。”章啸说道,“所以我们现在基本99%的数据都存储在云上,不过也保留了一些自建的基础设施,属于自建+云服务的混合架构体系。”

货拉拉大数据专家章啸
混合架构增加了管理难度,所以找到一朵适合自己业务的云,更加关键。
一年多前,货拉拉将40PB+数据,进行了一次大规模云上迁移,最终迁移目的地,是腾讯云。
用章啸的话说,这次迁移可谓是“开着飞机换引擎”,但最终结果是好的,0故障完成了40PB+的大数据基建搬迁。
数据迁移一年后,依托腾讯云Data Platform数据平台解决方案,货拉拉实现货运报表产出提前40分钟,让任务提速10%。
而这离不开腾讯云Data Platform数据平台解决方案旗下的两个拳头产品:对象存储 COS、元数据加速器Metadata Accelerator。
随着AI大模型时代的到来,货拉拉也在积极拥抱AI,但又面临着新的难题——AI大模型所需要的海量数据频繁访问,拉低了整个数据访问的速度。
那么,AI大模型时代,货拉拉该如何面对海量数据爆炸式增长的挑战?这也是所有面临AI转型的公司们,共同的难题。
40PB+数据的云上迁移
开着飞机换引擎
12年时间积攒的数据量,货拉拉将其一次全部迁移到了腾讯云存储系统架构中,如此大规模的数据迁移,挑战相当大。
业内皆知,企业积累的海量数据,就是一座尚未被挖掘的“金矿”,数据不光要存起来,更重要的还要能用,才能够真正发挥数据的价值。
但往往在使用数据的过程中,一方面存在着数据误删、数据勒索、机房灾难等导致核心数据丢失的情况,另一方面,海量且持续增长的视频、图片等非结构化数据,也面临着存储成本增加、传统存储架构响应慢,难以满足企业实时调用等需求。
事实上,当前货拉拉业务规模已经达到超亿级文件数量规模,在此规模下,数据存储需要保障数据可靠性满足不丢失需求的同时,还需要实现业务高可用,满足任务执行期间业务不受损。
针对这些问题,货拉拉已经形成了自建+混合云服务的大数据存储架构。
在其大数据存储架构中,底层接入层是采集用户数据层,将数据采集之后针对不同时效性要求,会经过批处理和流处理等方式,写入到在线存储或提供给业务使用。
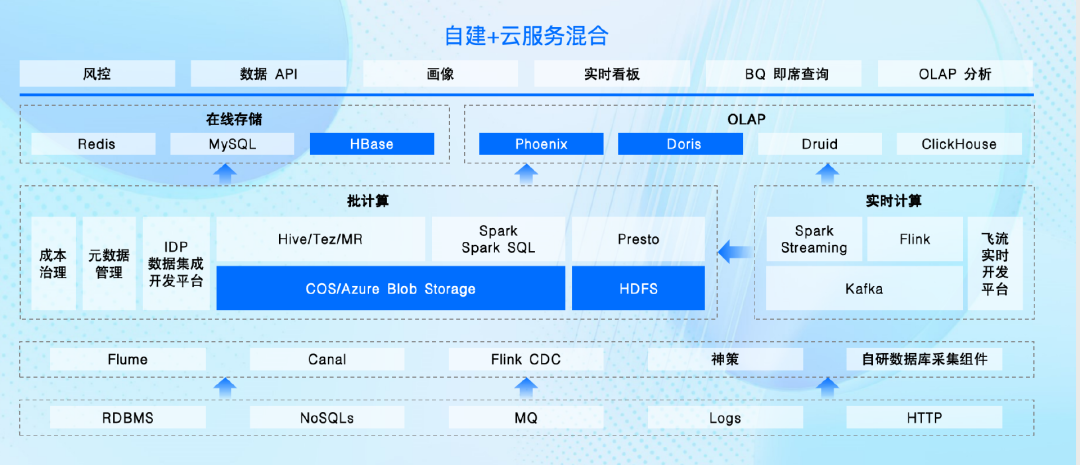
其中,批计算主要是处理永久存储在存储系统中的数据,流计算则处理实时生成的数据,“批处理的部分我们是部署在腾讯云上,其他的板块则在其他云上。”章啸说道。
另外,针对数据灾备可能出现的核心数据丢失问题,货拉拉打造了两套体系化的数据灾备架构:
一是元初-元数据管理平台,针对七天内被误删的数据,能够通过多层防护,快速恢复数据;
二是自研灾备系统Kirk,针对数据勒索和机房灾难,可实现PB级数据灾备,并全链路灾备;
基于这两套系统的能力,货拉拉可以实现数据误删的100%召回,核心数据 100%灾备。
“随着我们与腾讯云的深入合作,最终决定将整个40PB+规模数据都迁移到了腾讯云上。”章啸说道,“腾讯云Data Platform数据平台解决方案能够提供多种能力和服务,不过我们现阶段主要使用了底层存储和元数据加速能力。”
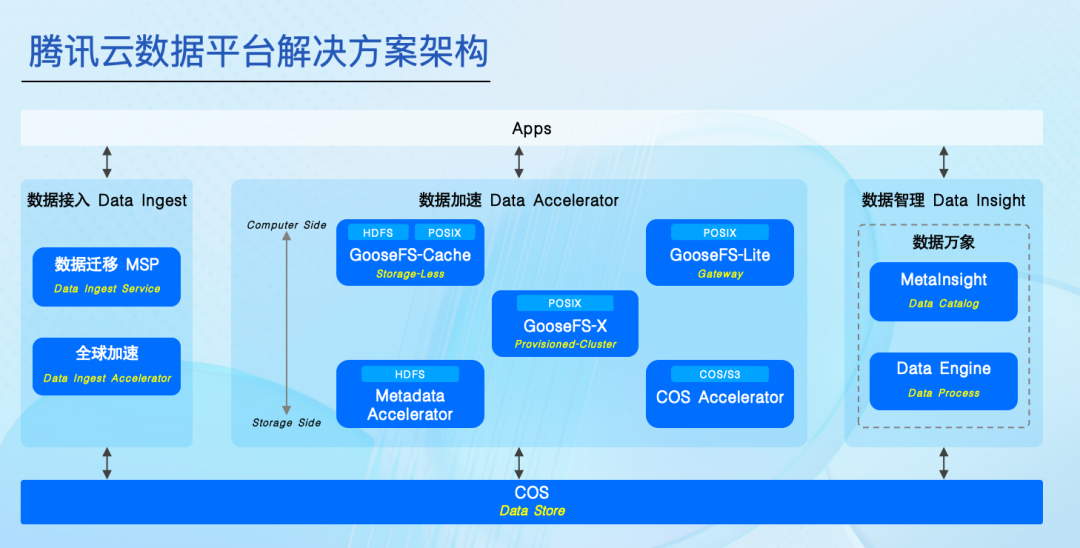
据章啸介绍,整个数据迁移大概分为几个步骤:
首先是基于Kirk系统和数据离线开发平台做数据迁移和任务迁移,会同时在两朵云中跑任务,跑完之后会自动进行数据对比,防止数据出错。对比的结果完成后给到业务做验收。
当整个数据验收能持续验收成功,会对整个开发平台做封网,在当天把整个链路跑完后,再次对比数据准确性,确保准确之后,再将所有系统全部切换,从而完成整个云的迁移。
“我们将数据迁移过来一年多,目前没有出现由于COS这种存储所导致的问题,真正做到了0故障率,整体的建立过程也非常平稳。”章啸说道。
AI时代数据大爆炸
存储的难题怎么解?
企业面临AI业务的转型,带来了许多对数据的新需求。
最近两年,货拉拉落地了许多新的AI业务板块。
“我们现在AI业务主要有ChatBI、AI客服等相关的内容,在AI方面目前跟腾讯合作的很深入。”章啸说道。
AI应用在进行模型训练时,对数据的调用需要有高吞吐、低延时。
这就带来了新的问题——AI数据和传统大数据混合。
“我们的数据都在腾讯云上,现在存在一些模型训练的任务,会把整个桶的下行带宽持续拉满,这样会对我们整个离线链路的稳定性有很大影响。”章啸说道。
企业传统业务的大数据存储计算需要高稳定性,而AI大模型的数据训练却需要高吞吐、大带宽,两个数据存储需求相互抢占资源,又该如何在一个系统架构中实现共存?
“针对这些问题,我们也跟腾讯交流分享了几次,最后提出了分桶而治,专项优化的解决方案。”章啸说道,基于腾讯云对象存储COS,是在底层做了两个存储集群,即COS桶1和COS桶2:
COS桶1,专做大数据存储,上层支撑整个大数据市场相关业务;
COS桶2,则写入专做AI大模型训练的数据,上层对应整个AI项目;
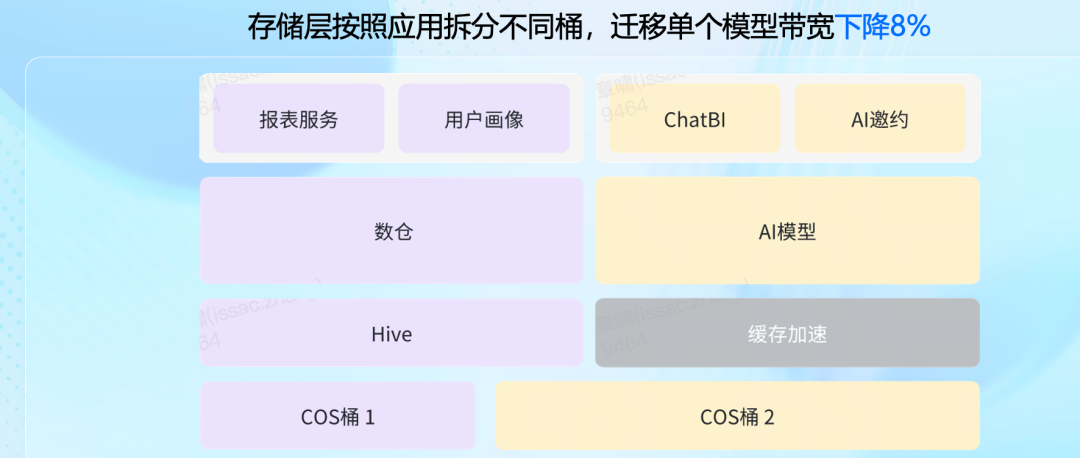
基于此,“存储层按照应用拆分不同桶,仅迁移单个模型下行带宽下降8%。”章啸说道,“不过,我们也明显感受到AI业务对带宽吞吐的诉求要比大数据大的多,后续也会逐步把AI业务通过这样的方式迁移过来,再进行专项优化。”
在底层COS存储设立两个桶,虽然缓解了大数据和AI大模型数据在使用时对带宽需求的压力,但AI大模型数据存储桶自身,也仍面临着需要非常高的带宽吞吐能力。
针对这一问题,货拉拉正与腾讯云基于数据加速器GooseFS进行探索。
据介绍,腾讯云数据湖存储GooseFS可支持Tbps级吞吐、千亿级元数据规模、单链接速度轻松达到 GBps 级别,相比于行业内百兆级规模提升10倍,大模型分发效率10倍跃升。
而实现数据高速调用的背后,GooseFS主要是通过对数据的亲和力调度能力,将数据调度到跟计算相关节点更近的本地磁盘上,提供Tbps级的吞吐性能。
“我们用起来体验感最好的,就是GooseFS的元数据加速能力。”章啸坦言。
最后,针对跨云的问题,章啸也表示,目前基于COS的模式进行训练,可以实现按需配置,“数据将持久化存储在COS Data Lake中,训练数据按需通过GooseFS拉取到云上或者IDC计算端,做到一份Dataset,多地训练。”
可以看到,COS作为云存储底座,为货拉拉40PB+的数据提供统一存储池,能够提供安全稳定的数据存储能力,在大幅度提升系统可用性、可靠性等性能的同时,也还可以大幅降低存储成本。
而GooseFS则提供元数据的数据缓存加速服务,能够满足大规模数据处理和训练对高性能存储的需求,帮助货拉拉落地AI应用业务。
数据万象助力企业
释放数据价值
随着企业非结构化数据不断增长,带来了AI识别难,处理速度慢等新难题。
为了让数据的价值能够释放,需要在存储端就开始做预处理。
而腾讯云数据万象,能够有效帮助企业解决这一问题。数据万象,主要包含两个功能,一个是数据管理Metalnsight,一个是数据处理Data Engine。

Data Engine,就是数据处理,把计算下沉到存储端,提供大量标准化的图片、音视频的处理能力。比如小红书用户上传图片,它能在数据层就把图片进行压缩+裁剪+上水印,在图片质量不受损的情况,提升图片访问性能,保护知识产权。
MetaInsight,通过智能检索能力为客户提供一种高效的数据管理服务,它能让用户使用自然语言快速检索海量非结构化数据(图片、音视频等)。比如网盘、手机相册中的“以文搜图”,之前找照片只能按时间一张张找,现在可以输入关键字直接搜到。
举个例子,在电商商品搜索中,基于MetaInsight的以图搜图功能,用户在上传商品图片后,系统通过特征提取与索引库中的商品图进行相似度对比,快速返回同款或相似款商品信息,解决传统关键词检索的局限性。
而在AI大模型训练场景中,MetaInsight 可对海量非结构化数据进行智能预分类,通过语义检索(如输入“雨天”“行人穿行”)快速筛选特定场景数据。相比人工标注,该方案能减少70%以上的预处理时间,同时支持跨模态检索(如图像+文本描述),帮助企业在数据清洗阶段高效构建高质量训练集。
“因为非结构化数据的日益增长,云存储平台一定要有向量化的能力。”章啸说道,“数据万象CI,就可以很好的提升对非结构化数据的管控。”
可以看到,AI大模型时代,存储不再是之前只做数据的仓库,而是结合一系列数据处理和计算的能力,成为了数据加速运转的新引擎。
