


(图片来源:亚马逊网络服务)
本月,亚马逊网络服务(AWS)推出了其第五代定制通用服务器处理器——Graviton5。该处理器旨在AWS数据中心中,与AMD和英特尔的行业标准CPU一较高下。这款新处理器进一步拓展了AWS内部的基于Arm的CPU计划,配备了多达192个核心和180MB的L3缓存,意在与高端AMD EPYC和英特尔至强处理器展开竞争,甚至有可能在AWS数据中心中取代部分处理器。
概览
AWS Graviton5处理器采用3纳米级工艺打造,可能由台积电负责代工生产。该处理器集成了192个Neoverse V3核心,并配备了180MB的L3缓存。AWS表示,与前代产品相比,新CPU的性能将提升25%。这一数据看似保守,毕竟Graviton5的核心数量实现了翻倍。该芯片采用了Armv9.2 ISA,带来了多项微架构改进,并且L3缓存容量提升了五倍。
(图片来源:Arm)
这款新处理器现已在预览版的Amazon EC2 M9g实例中亮相,而计算优化型C9g和内存密集型R9g变体则计划于2026年正式推出。据AWS介绍,与M8g相比,当前的EC2 M9g实例在数据库方面的运行速度提升了高达30%,在Web应用方面的运行速度提升了高达35%,在机器学习工作负载方面的运行速度同样提升了高达35%。
深入剖析:192个Neoverse V3核心
亚马逊网络服务对于Graviton5 CPU的确切规格和内部设计,有意保持了一定的神秘感。尽管如此,它还是提供了与上一代Graviton4芯片的对比信息,这让我们能够从中解读出一些细节,并展开更深入的探讨。
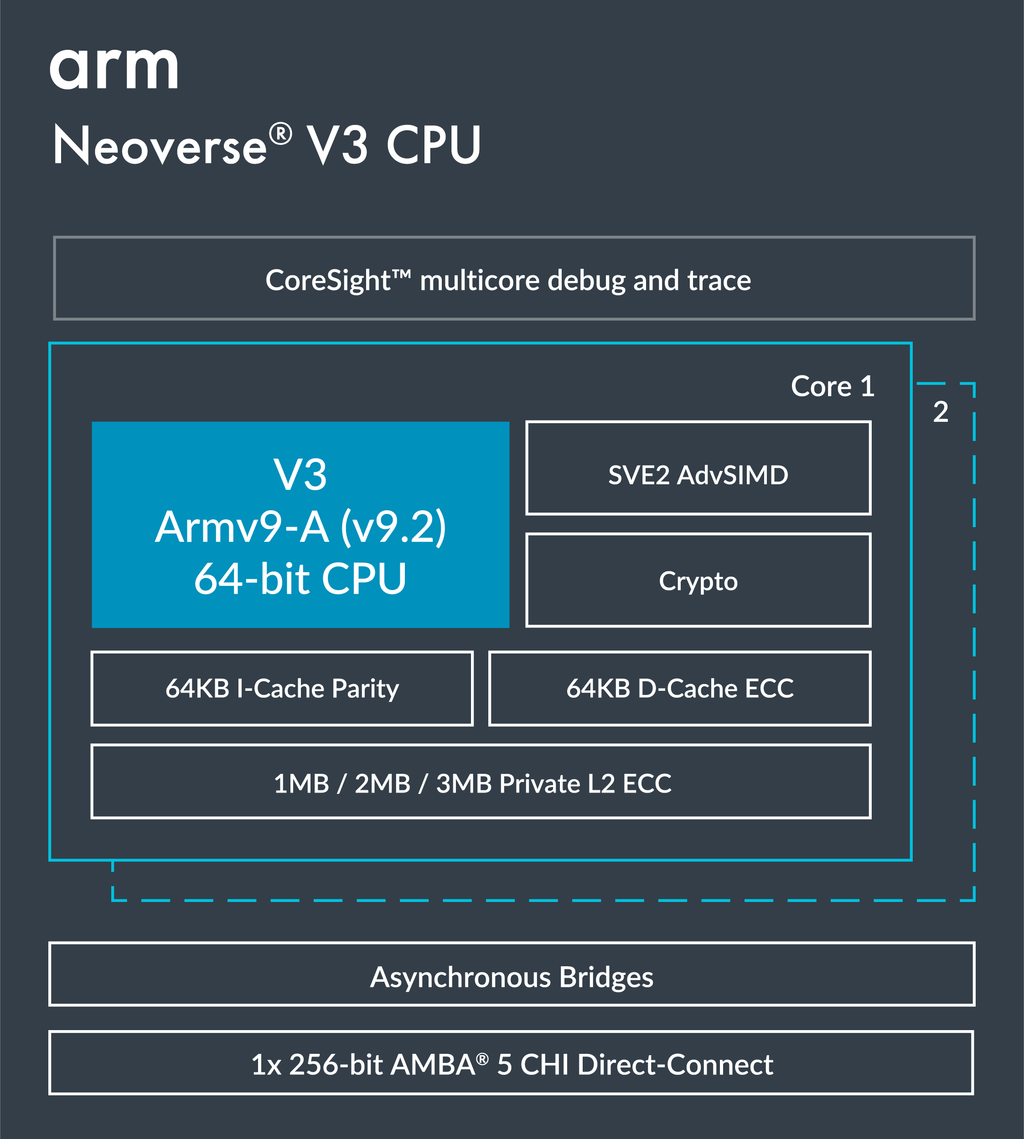
AWS和Arm官方均确认,Graviton5每个封装中集成了192个Neoverse V3核心,采用3纳米级工艺制造,使其成为Graviton系列中密度最高的CPU,同时也是迄今为止密度最高的Armv9.2处理器。处理器的内部布局经过了重新设计,以减少通信开销。AWS声称,核心间延迟降低了高达33%,考虑到核心数量翻倍,这一点尤为引人关注。
(图片来源:Arm)
当我们谈及Neoverse V3时,自然会联想到Arm开发的计算子系统(CSS)。尽管Arm确认我们讨论的是Neoverse V3,但亚马逊和Arm均未确认Graviton5是否采用了Arm开发的CSS。这意味着,我们在Graviton 5中看到的可能是一个独特的设计。
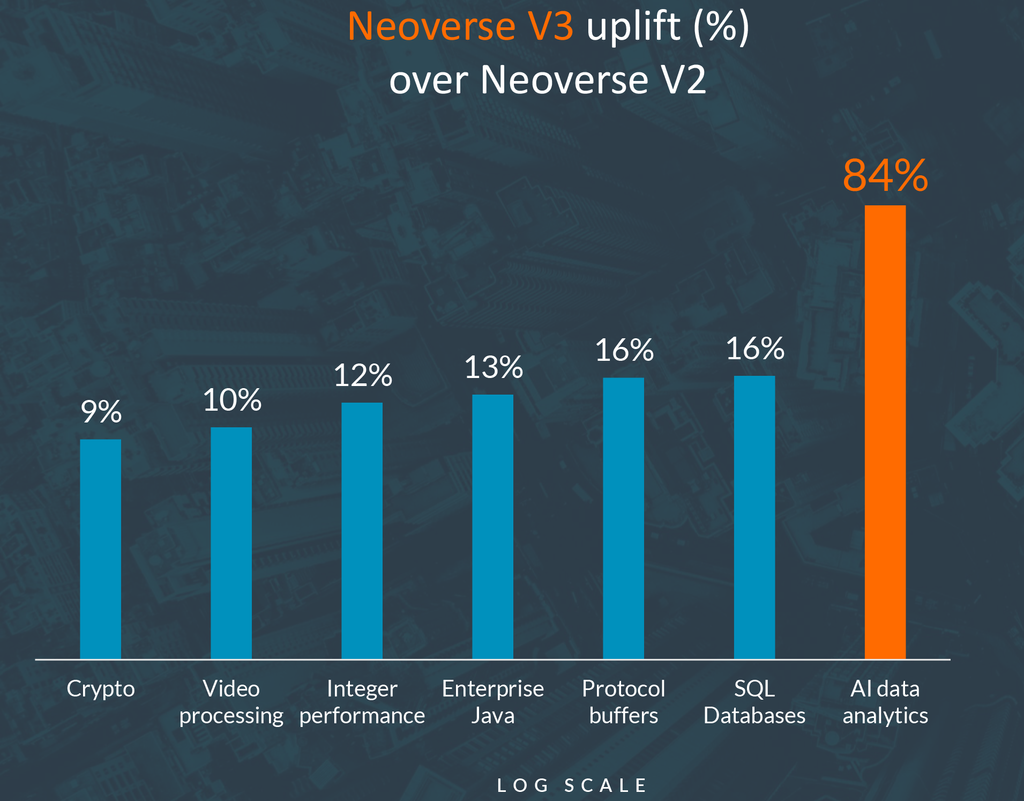
在Neoverse V3核心与其前代核心的性能对比中,Arm声称,在通用云工作负载方面,Neoverse V3相比Neoverse V2有9%-16%的提升,在AI数据分析方面则有高达84%的提升。这也是AWS对Graviton5以及计算密集型M9g实例的性能提升持保守态度的原因之一。另一个原因是,AWS并不像AMD或英伟达那样追求极致性能,而是更注重每美元的可预测性能和云中的可扩展性。尽管如此,凭借192核处理器,AWS已然跻身于CPU开发者的顶尖行列。
L3缓存取代系统级缓存
关于Graviton5,一个值得关注的有趣点是它配备了L3缓存,而非像Graviton4那样的系统级缓存(SLC)。尽管数据中心CPU中的L3缓存和SLC有许多相似之处,但它们并非同一概念。
传统上,L3缓存是位于数据中心CPU中每个计算单元或核心集群内部的末级缓存。它主要通过减少对DRAM的访问来为CPU工作负载提供服务,针对低延迟进行了优化,并直接参与核心的相干协议。因此,L3缓存与核心紧密相连,且在物理上与之接近。

(图片来源:英特尔)
相比之下,SLC位于SoC架构中核心集群的外部,由所有CPU核心、各种其他加速器、I/O设备、NIC和DMA引擎共享。它往往规模更大(通常为100–300MB以上),并针对吞吐量而非延迟进行了优化,因为它充当了一个全局缓冲区,减轻了DRAM的压力,并为异构计算块提供了相干访问。SLC能够提升极高核心数量的扩展性,并实现CPU、GPU和片上加速器之间的统一内存语义,这是传统L3缓存无法独自承担的角色。
亚马逊并未公开解释这一设计决策,但基于Graviton4的架构以及我们对Graviton5的了解,原因几乎可以肯定是架构可扩展性。从Graviton4中的SLC到Graviton5中大型的180MB L3的转变,并非表面上的改变,它反映了192核处理器在数据移动、延迟管理和相干性维护方面的根本性变化。
Graviton4的架构——96个Neoverse V2核心、CMN-700网格、12个DDR5-5600通道——在采用集中式或半集中式SLC的情况下运行高效。然而,将核心数量翻倍至192,会显著增加网格流量、跳转距离以及任何统一缓存结构上的争用。在这种规模下,单一的SLC几乎肯定会成为延迟瓶颈,并且无法支持AWS所声称的核心间通信延迟降低高达33%的说法。分布在芯片上的L3缓存允许热门数据在物理上保持接近计算集群,从而降低平均访问延迟并改善整体相干行为。
AWS宣传的五倍缓存扩展进一步强化了这一架构的必要性。按照这一比例扩展Graviton4的36MB SLC,将得到180MB,而AWS的额外声明——每个核心的缓存增加2.6倍,核心数量翻倍——意味着总缓存约为187MB,这与大型、多切片L3缓存相符,而非会产生路由复杂性的单一SLC块。
最后,基于L3的设计提供了更强的多租户性能可预测性,这对AWS来说至关重要。在云工作负载下,共享缓存会经历严重的跨租户干扰和可变延迟。因此,在设计缓存子系统时,开发者必须充分考虑AWS的使用场景。总而言之,转向分布式L3缓存是Graviton5架构演进的必然选择。
新的内存子系统、I/O和安全特性
与Graviton5其他设计方面的许多细节一样,AWS也未透露太多关于该CPU内存子系统的信息。不过,可以肯定的是,Graviton5的内存子系统比Graviton4更为强大,因为它支持更高的内存速度,这很可能意味着它至少保留了Graviton4的12通道内存子系统,但数据传输速率更高(即高于DDR5-5600)。
以6400MT/s运行的12通道DDR5设计将提供约614GB/s的总带宽,即每个核心约3.2GB/s,这实际上低于Graviton4每个核心5.6GB/s的速度。然而,更大的L3缓存可以弥补内存带宽的这一降低。话虽如此,我们并不知道Graviton5支持的确切内存通道数。
据AWS介绍,输入/输出吞吐量也得到了类似提升:网络带宽在实例大小上平均提升了15%,最大配置下的吞吐量提升了一倍。通过Amazon EBS的存储带宽平均提升了约20%。这些提升旨在不仅改善计算密集型应用的性能,还改善依赖快速存储和网络技术的分布式系统的性能。
在安全方面,Graviton5基于AWS Nitro系统构建,配备了处理虚拟化、网络和存储的第六代Nitro卡。AWS还引入了一个名为Nitro隔离引擎的新组件,该公司将其描述为一种经过形式验证的隔离层。该隔离引擎不依赖传统的安全验证方法,而是使用数学证明来确保工作负载之间以及与AWS操作员之间的隔离。该架构实施了零操作员访问模型,AWS计划允许客户审查其实现及背后的形式证明,以确保最高级别的安全性。此类安全措施可能是该公司吸引传统上使用本地服务器的客户所做出的努力的一部分。
总结
AWS的新Graviton5处理器是一款192核、3纳米的基于Arm的CPU,拥有约180MB的L3缓存。这使这家云服务巨头成为了数据中心高端AMD EPYC和英特尔至强解决方案的有力竞争对手。该CPU集成了Neoverse V3核心,并提供了宣称的25%性能提升。考虑到核心数量翻倍、Armv9.2 ISA中的大型微架构改进以及缓存容量五倍提升,这一数据显得较为保守。此外,AWS确认由于内部布局重新设计,核心间延迟降低了33%,但并未透露是否使用了Arm的CSS,这表明Graviton5可能是围绕Neoverse V3核心构建的独特Annapurna Labs设计。
一个关键的架构转变是用大型分布式L3取代了Graviton4的SLC,以实现192个核心之间更好的相干性扩展和可预测的延迟。该处理器还配备了更快的内存子系统(可能保留了12个通道,但DDR5速度更高)、改进的网络和存储带宽以及新的Nitro隔离引擎,该引擎使用形式验证来保证租户隔离并实施零操作员访问。
目前,Graviton5为新的EC2 M9g实例提供动力,在数据库、Web服务和机器学习方面的运行速度提升了高达30%-35%。计算优化型C9g和内存优化型R9g变体将于2026年正式推出。
