

日前,在英特尔重庆举办的生态大会“AI新技术和软件创新论坛”上,集中展示了AI PC的创新成果。这场论坛恰逢英特尔入华40周年的关键节点,更踩准了端侧AI爆发的行业窗口期—— 据预测,2025年全球AI PC出货量将突破1亿台,占整体PC市场40%,端侧智能正成为重构产业格局的核心变量。

现场汇聚了戴尔、联想等头部终端厂商及上百家生态伙伴,英特尔中国区技术部总经理高宇携核心团队登台,不仅揭秘了 AI PC 从技术概念到规模化落地的演进路径,更通过硬核演示呈现算力、存力与互联技术等多重突破,以实际成果印证了英特尔在端侧AI赛道的引领地位,为全球AI PC产业发展锚定新方向。
三年性能提升50倍 推动端侧AI创新
经历了2023年的概念提出,2024年的商业化产品落地,以AI PC、AI手机为代表的端侧AI正在迎来爆发式发展。
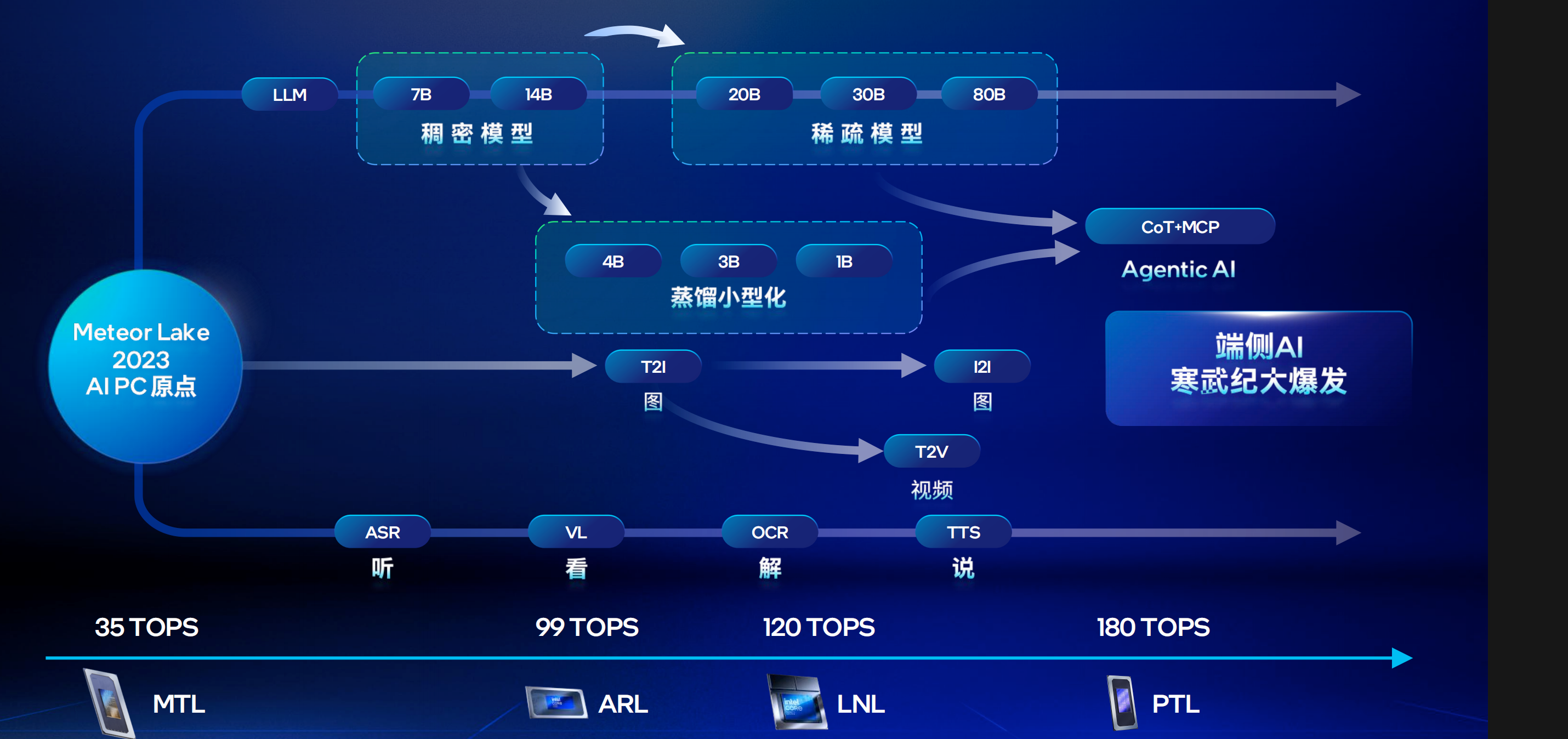
大语言模型一方面在走向MOE(稀疏化)参数量大,激活少,需要高存力、低算力,非常适合端侧部署。另一方面是“小而精”,在蒸馏、压缩等核心技术的推动下,优质高效的小模型开始出现,在某些专业领域和特定场景能力突出,也为端侧部署奠定了基础。
同时,AI正从“纯文本逻辑思考”转向“多模态感官交互”,通过ASR、VL+OCR、TTS 等技术,具备了类似人类 “听、看、说” 的感知与表达能力,这种多模态交互已成为当下主流的应用形式。
作为AI PC的行业引领者英特尔持续通过技术创新,提升端侧算力能力,推动端侧AI的落地和部署。
2023年,行业首发AI PC处理器——35TOPS算力的第一代酷睿Ultra。2024年,100TOPS规模算力的Arrow Lake和Lunar Lake相继面世。而在明年CES即将亮相的Panther Lake,也将凭借180TOPS重新定义AI PC的算力天花板。
如果说Meteor Lake比之前产品的AI性能提升了8倍,那么三年之内,英特尔将端侧AI的性能提升了50倍,显著加速了端侧AI的部署速度。
此次大会上举办期间,英特尔携手生态伙伴,展示了由酷睿Ultra赋能的端侧AI领域的全面布局。从AI PC到工作站,以及盒子、车载AI Box、NAS等更广泛的边缘AI的终端产品。
可变显存 玩转大模型
论坛现场,英特尔中国区技术部总经理高宇重点介绍了基于Arrow Lake平台酷睿Ultra家族285H。酷睿Ultra 9 285H处理器自今年1月份发布以来已经成为AI PC轻薄本的首选产品,其受到市场欢迎主要在于如下几个特征:

一是大内存。相较于市面上16G、32G的内存配置,该平台最高支持128G内存容量。
二是内存可动态分配于显存。用户可自由选择,支持最高将96%的容量用于显存,从而支持大体量的模型运行。该平台最大支持1200亿参数的模型。
三在上述硬件能力的加持下,可以解锁更多的场景。
四是带来更多产品的选择。
此次大会期间,包括戴尔、HP、联想,包括华硕的NUC等大厂,以及极摩客、零刻、创盈芯、Geekom、机械式、六联、Khadas等厂商带来了多种形态的产品,包括轻薄笔电、设计师笔电、Mini PC以及嵌入式灯,展现出基于英特尔AI PC处理器的创新生态。
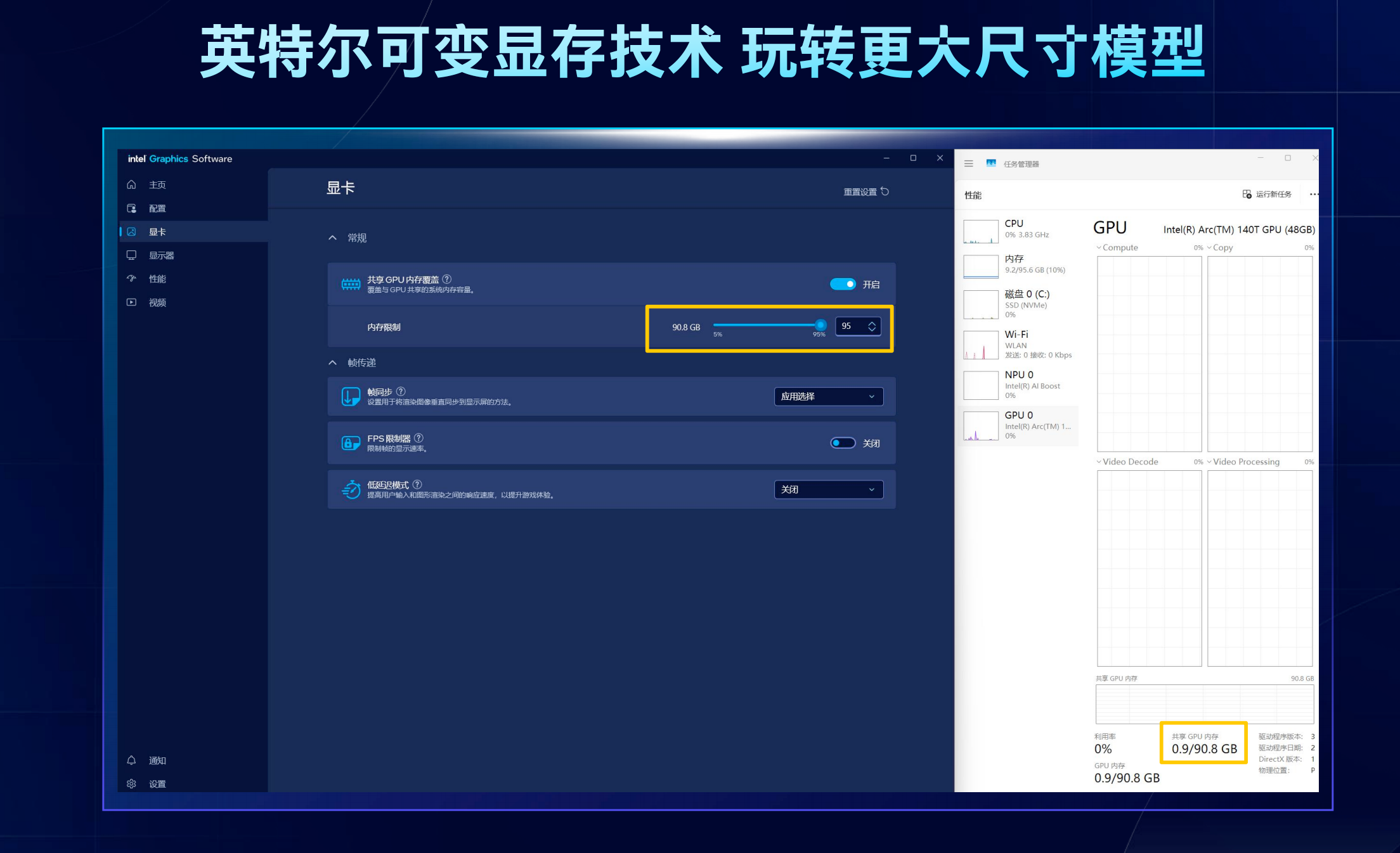
论坛现场,为展现AI PC的强大性能,英特尔进行了几个重要的演示。通过在英特尔显卡的控制面板上的选项,既能够调节显存比例,在5%-95%之间选择,英特尔在现场展示了基于96GB内存机型的展示,通过最大化使用显存(90G),在一台轻薄笔记本上,就能够流畅运行从20B-120B大模型。
高宇表示,英特尔的共享显存和竞争对手相比,重要的区别是内存是CPU和集显共享的,CPU的内存并不会因划拨给集显而收到限制。
双机互联 复杂任务轻松拿捏
大模型不仅要在端侧运行起来,还要有出色的表现,特别是针对复杂任务而言。在另一个演示中,通过给大模型输入红楼梦前五章的内容(超过30K input长窗口)并让其续写一个新的第六章故事情节,同样基于英特尔AI PC处理器也在极短的时间内出色完成,且保持了一致的写作风格。
在解锁新场景方面。英特尔还演示了酷睿Ultra 9 285H平台上运行DeepSeek OCR的演示,实现更快的文档整理、财务报表提取、图片内容摘录等。在TTS方面,目前英特尔对所有主流TTS模型都实现了第一时间适配,并可以完全在本地实现运行,其合成声音效果复刻程度可以达到90%。

此外,针对复杂任务场景,英特尔还进行了双机互联后的能力展示。通过雷电4.0接口将两台酷睿Ultra 9 285H的连接,将235B的模型用Q4KM形式进行加载,实现双机并发的AI推理。

高宇强调,6-7token,这是目前达到的速度,但英特尔的工程师还在持续打磨细节和技术,预计明年1月,即在Panther Lake发布时,双机雷电互联会带来更加震撼的效果。
“双机互联有很多新玩法,双机互联后,通过张量并行加上专家并行,把参数拆到两个盒子里,实现双机算力的叠加和存力的叠加,从而跑更大的模型,并且算力实现了叠加,也就是说两机运行起来的速度要比一台机器快很多。可以支持更大的并发,数据并行,承载更多客户群。”高宇称。
此外,双机下可以实现不同机器的不同模型部署,通过设计路由模型,实现不同任务对应机器上的分配。高宇表示,英特尔还会专门出雷电互联的AI加速助手,从而让低时延的特征非常容易通过一个开关的形式打开。
以存代算 破局算力瓶颈
尽管端侧算力近年来得到明显提升,但目前仍然存在一些局限。比如大模型生成过程中,最消耗算力的是预处理阶段,产生KV Cache的结果,而很多KV Cache是重复且可以复用的。传统软件架构下,KV Cache要么在内存,要么就被丢弃,但未来可能面临将被丢弃掉的KV Cache重新计算一遍的情况,这对算力是一种浪费。
因此,英特尔和PHISON共同开发了aiDAPTIV+技术,基于PCIe Gen5×4的专属的NVMe通道,可以将已经计算过的KV Cache存储在PHISON的AI SSD上进行持久化,极大节省了计算时间以及内存,从而实现加速。
在第一RAG的演示中,英特尔通过两台酷睿Ultra 9 285H 96GB的PC,一台是经过了英特尔和PHISON共同开发的aiDAPTIV+加速设备,其中一个119GB的R盘用作AI SSD。比对中,可以看到在回答基于RAG事先学习文档方面的应用,速度明显领先于对比机型。
第二个代码解析的演示中,两台机器同时运行开发者常用软件VSCode,在加载游戏应用并提出修改需求后,采用aiDAPTIV+技术的设备,实验数据有7-8倍的速度提升。

结语
此次论坛上,除了AI PC外,英特尔也针对于盒子、Mini PC等不同形态上的功能进行了演示,可以说英特尔推出的AI 全家桶,正反映着端侧AI的蓬勃的创新生态。
从算力三年50倍跃升的硬核突破,到可变显存、双机互联、aiDAPTIV+“以存代算” 的技术革新,英特尔以全链条创新重构AI PC核心能力,让120B大模型端侧流畅运行、复杂任务高效落地成为现实。依托开放生态,英特尔联动全球伙伴覆盖多终端形态,既夯实了AI PC的技术标杆,更推动端侧 AI 从 “可用” 走向 “好用”。
