

【导读】VMem用基于3D几何的记忆索引替代「只看最近几帧」的短窗上下文:检索到的参考视角刚好看过你现在要渲染的表面区域;让模型在小上下文里也能保持长时一致性;实测4.2s/帧,比常规21帧上下文的管线快~12倍。
当你用一张图「逛」一套房子,来回转场、回到起点,还希望厨房看起来还是原来的厨房——这件事对视频生成模型并不容易。
牛津大学团队提出VMem(Surfel-Indexed View Memory):把「看过什么」写进一种叫surfel的几何小片里,下一次生成时只取真正相关的过往视角当上下文,实现了「一致性更强、资源更省、速度更快」的效果。

论文链接:https://arxiv.org/abs/2506.18903
· 几何做「记忆目录」
把过去生成的视图按3D表面元素(surfel)索引;每个surfel记录「哪几帧见过我」。
新视角来时,渲染surfel看谁「出现频率最高」,直接取这些帧当参考。显式遮挡建模,检索更靠谱。
· 小上下文,大一致性
在RealEstate10K、Tanks and Temples等基准上,尤其是团队提出的回环轨迹(cycle-trajectory)评测里,VMem在长序列回访同一位置时显著更稳。
· 即插即用
记忆模块可挂在SEVA等图像集生成骨干上;把上下文从K=17减到K=4仍能守住指标,还把时延砍到4.2s/帧(RTX 4090)。
为什么「回头看」这么难?
两类主流路线各有痛点:
- 重建+外延补洞(out-painting):先估几何再补图,误差会叠罗汉,越走越歪;
- 多视图/视频式条件生成:不做几何,但要吃很多参考帧,算力开销大、上下文窗口短,走远就忘。
VMem重新审视第二类:与其看「最近」,不如看「最相关」。相关性的度量来自几何可见性。
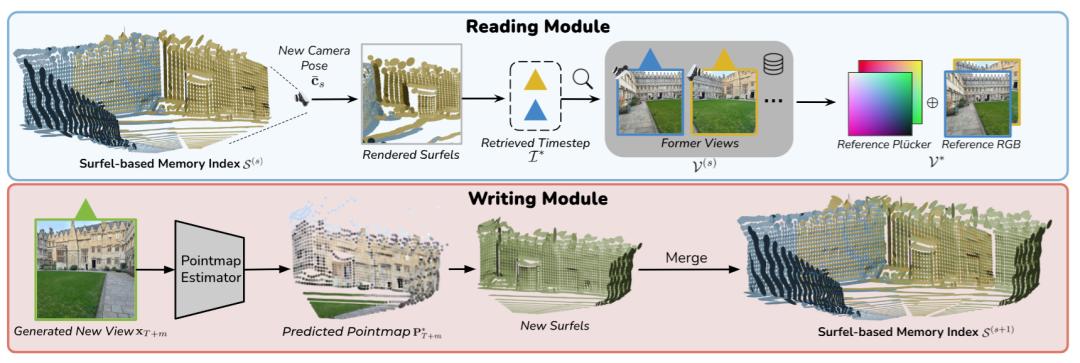
写入(Write):新生成的帧用CUT3R等点图预测得到稀疏点云→转成surfel(位置、法向、半径)→把「看到我的帧编号」写进surfel的索引集合;相近surfel做合并;整体放入八叉树方便检索。
读取(Read):面对一组待生成相机位姿,先求一个平均相机,从该视角渲染surfel属性图,统计每个像素投票到的「出现过的帧编号」,挑Top-K最高频作为参考视图集合;对位姿相近的参考做NMS去冗余。
生成(Gen):把(Top-K参考图像+参考/目标相机的Plücker表达)喂给图像集生成器(论文默认SEVA),一次自回归生成M帧。
直观理解,surfel是「看过的表面贴纸」,上面写着「是谁看过我」;新相机来时,把贴纸从新角度投影,谁名字出现最多就把谁叫来帮忙。
向世界模型的可插拔记忆层
为什么世界模型需要这样的记忆?
世界模型通常靠隐式隐状态(latent state / RNN / Transformer cache)来跨时保留信息,但在长视野、部分可观测(POMDP)的场景中,隐式状态容易「遗忘」早期细节、且不可解释。
VMem提供的是显式、可查询、几何对齐的外部记忆:以surfel为「记忆索引」,把「谁看过我」这类可见性线索结构化存起来。这样做带来三点直接收益:
- 长时一致性:记忆容量与步数解耦;跨数百步仍能稳定回访同一地点与外观。
- 可解释与可裁剪:按可见性投票做检索,遮挡/误配更少;内存可按区域/密度/热度做剪枝。
- 高效取证:把「看很多不相干的历史帧」变成「只看与当前表面相关的少量关键帧」,大幅缩小上下文与算力。
如何接入现有世界模型?(三种常见用法)
外部记忆(External Memory):把VMem作为Key-Value存储,Key=surfel(位置/法向/半径等),Value=出现过该surfel的帧与特征。模型在每步预测前,通过相机姿态渲染surfel可见性图,检索Top-K参考视图与特征并融合到当前状态更新。
检索前端(Retrieval Front-End):在视频/多视图生成backbone(如图像集扩散或时空Transformer)前,用VMem先选参考视图,再走主干网络;等价于把「上下文选择」外包给几何索引。
策略+世界模型联合(RL/Embodied):将VMem作为共享记忆供「世界模型+策略」共同读写:世界模型用它做长期一致的模拟,策略用它做定位/导航/回忆证据,减少长时信用分配的难度。
实验与结果
评测设置:单图起步,沿真值相机轨迹自回归生成;长期评估看≥200帧位置;团队额外提出回环轨迹,专测「走一圈再走回去」的一致性。
标准长期设置
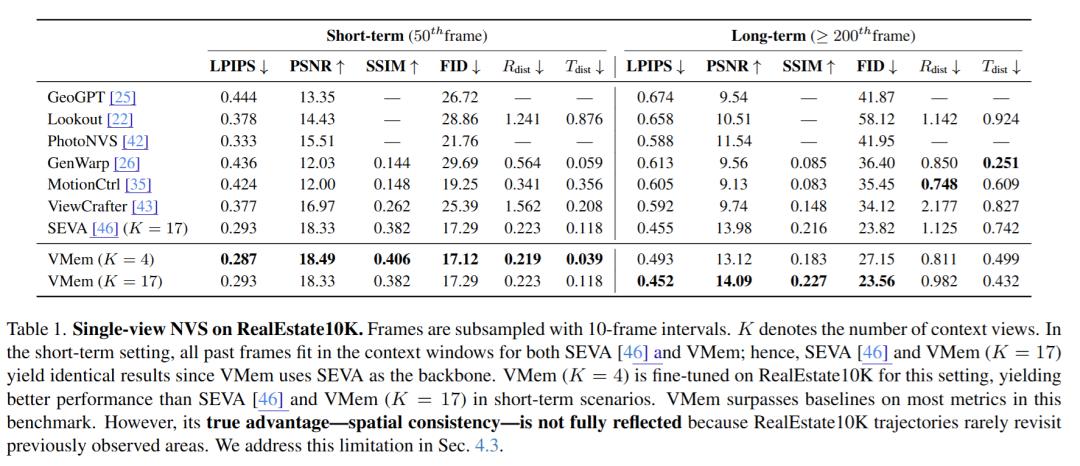
VMem在多数指标优于公开基线;当轨迹很少回访时,优势不完全体现在LPIPS/PSNR上,但肉眼一致性更好。
回环轨迹
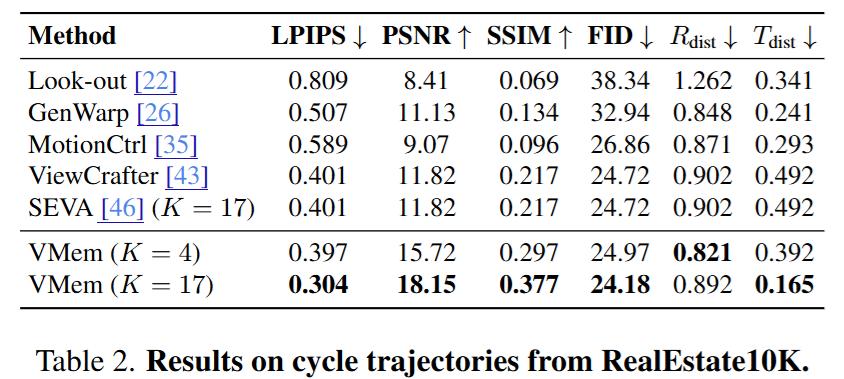
VMem在PSNR、LPIPS等指标上对比LookOut、GenWarp、MotionCtrl、ViewCrafter等普遍领先,回到起点时的外观与布局更一致。
效率:LoRA微调的K=4/M=4版本+VMem,~12×推理提速(4.2s/帧 vs 50s/帧),而画质和相机对齐指标接近或更优于K=17的大上下文。
消融:把检索策略换成「最近帧/相机距离/FOV重叠」,一致性明显变差;说明基于surfel的可见性投票是关键。K越小越显著。
和谁不一样?
相比重建+补洞线:VMem不把几何当最终表征,只用它做检索,因此对几何误差相对更鲁棒;
相比FOV/距离/时序检索:VMem的surfel显式考虑遮挡与可见区域的真实重叠,相关性更准;
相比隐藏状态记忆(如世界模型的隐表征):VMem的「记忆」是可解释的空间索引,便于裁剪与加速。
局限与展望
非实时:扩散采样仍需多步;作者估计未来可借助单步图像集模型与更强算力进一步加速;
数据域:微调主要在RealEstate10K(室内),对自然景观/动态物体的泛化仍待拓展;
评测标准:现有指标对「真正的多视角一致性」刻画有限,回环协议是一个开端,还需更系统的评测。
参考资料:
https://arxiv.org/abs/2506.18903
