

最近一个月以来,AI大模型领域的火药味明显变浓了。Google与OpenAI这两家长期占据行业头部位置的玩家,几乎将产品迭代发布节奏压缩到“以周计算”。上一代AI模型尚未站稳脚跟,下一轮更新便已接踵而至,正面碰撞不断。
最新的一击,来自Google。
北京时间12月18日凌晨,Google官宣Gemini 3 Flash正式发布,这是Gemini 3系列中速度最快、性价比最高的模型,也是Google在一个月内第四次对大模型产品线进行实质性更新,这被解读为对Open AI的“精准打击”。

1
OpenAI拉响“红色警报”
将时间线拉回11月,全球最具影响力的两家AI公司——Google与OpenAI,几乎同时发布了各自的旗舰模型:Gemini 3与GPT-5.1。
随后,Gemini 3 Pro在多项基准测试中,大幅超越Gemini 2.5 Pro、GPT-5.1以及Claude Sonnet 4.5等现有旗舰模型,在短时间内建立起口碑。
几乎在同一时间轴上,另一边的OpenAI也不甘示弱。
在自家的新一代产品GPT-5.1正面迎战Google Gemini 3却处于下风之后,OpenAI内部迅速进入了应急状态。12月2日,据外媒披露,OpenAI CEO山姆·奥特曼在一份发给员工的内部备忘录中明确表示,公司已进入“红色代码(Code Red)”紧急状态。
这一状态下,OpenAI的资源和注意力被重新拉回到最核心的产品——ChatGPT本身。OpenAI应用总监菲吉·西莫随后证实,这一“警报”直接加速了GPT-5.2的发布节奏。
于是仅仅一周后,OpenAI十周年之际,GPT-5.2火速上线,并一次性推出了三个版本——Instant、Thinking、Pro。

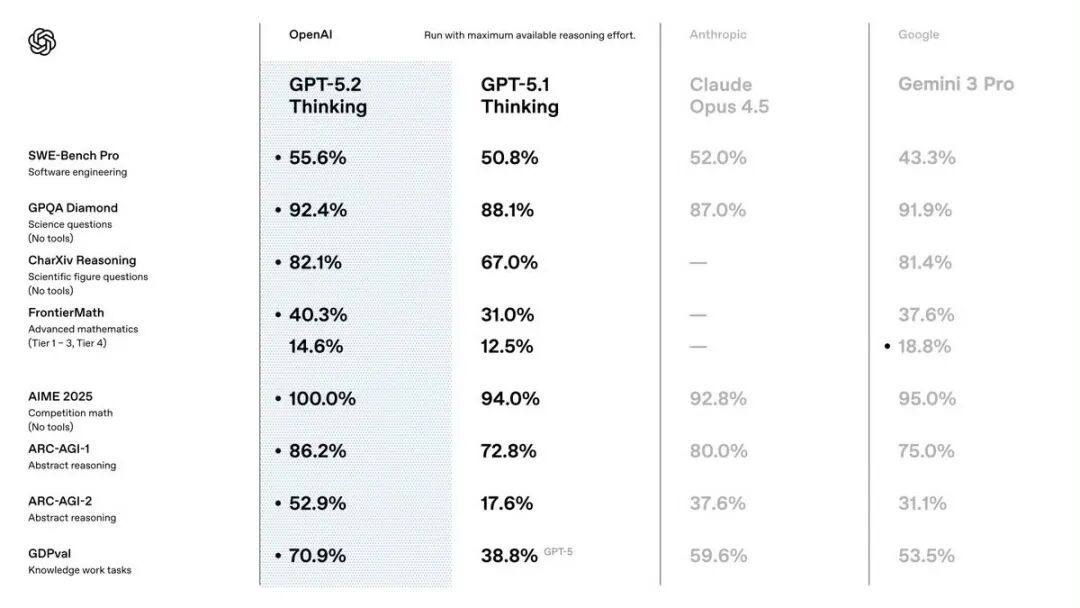
从官方公布的核心基准测试来看,GPT-5.2的表现极为强势。在多项对比测试中,面对GPT-5.1、Gemini 3 Pro等,GPT-5.2 Thinking几乎实现了“全线第一”。这也意味着,Gemini 3 Pro刚刚建立起不到一个月的领先优势,再次被打破。
2
ChatGPT
真要“替代”打工人了?
相比令人眼花缭乱的跑分体系,ChatGPT 5.2最值得关注的变化来自一个完全不同维度的评测体系——GDPval。
GDPval并不考模型“会不会做题”,而是直接衡量其完成真实、明确知识型工作任务的能力。该评测覆盖44个职业,横跨对美国GDP贡献度最高的9个核心行业,其测试内容也并非选择题或问答,而是要求模型生成真实可交付的工作成果——例如销售PPT、会计与财务表格、急诊科排班表、制造业数据图表,甚至短视频内容。

换句话说,这套评测体系不是在模拟工作,而是把模型直接“拉进职场”。
根据人类专家的盲评结果,在高难度知识型工作任务中,GPT-5.2 Thinking有70.7%的任务表现优于或至少持平于行业顶尖专家。
在效率层面,差距更加明显:GPT-5.2 Thinking完成同类任务的速度,约为人类专家的3倍,而综合成本仅为人类的约1%。
在更具代表性的金融场景中,这种提升也得到了验证。在“初级投行分析师”电子表格建模测试中,GPT-5.2 Thinking的综合得分达到68.4%,相较GPT-5.1 Thinking的59.1%有显著提升,成为OpenAI目前在该类任务中表现最好的模型。
综合来看,在GDPval覆盖的知识型工作任务中,GPT-5.2 Thinking“赢过或打平行业专家”的比例达到70.9%。而上一代GPT-5 Thinking,这一数字仅为38.8%。
GPT-5.2的产品分层变得异常清晰:Thinking版本长上下文推理更稳、表格、PPT、复杂方案能力明显提升,面向真正的重度专业工作;Instant版本对话更自然、解释问题更清楚、写教程、做说明、职场日用效率更高;Pro版本拥有最强的推理与代码能力,是科研、复杂系统设计的首选。
一句话总结就是,Thinking干重活,Instant管日常,Pro顶天花板。
正因如此,GPT-5.2 Thinking也被外界调侃为,真正开始“和牛马打工人抢工作”的一代模型。
3
职场“专家”和“老黄牛”
该选谁?
两家巨头明显带有“赶工”色彩的发布节奏,引发了另一波更为直接的市场反馈——大量用户的差评开始出现。有网友晒出GPT-5.2在SimpleBench上的“成绩单”,GPT-5.2的得分低于Claude Sonnet 3.7,后者是一个差不多一年前发布的模型;GPT-5.2 Pro的表现也没好多少,勉强超过GPT-5。
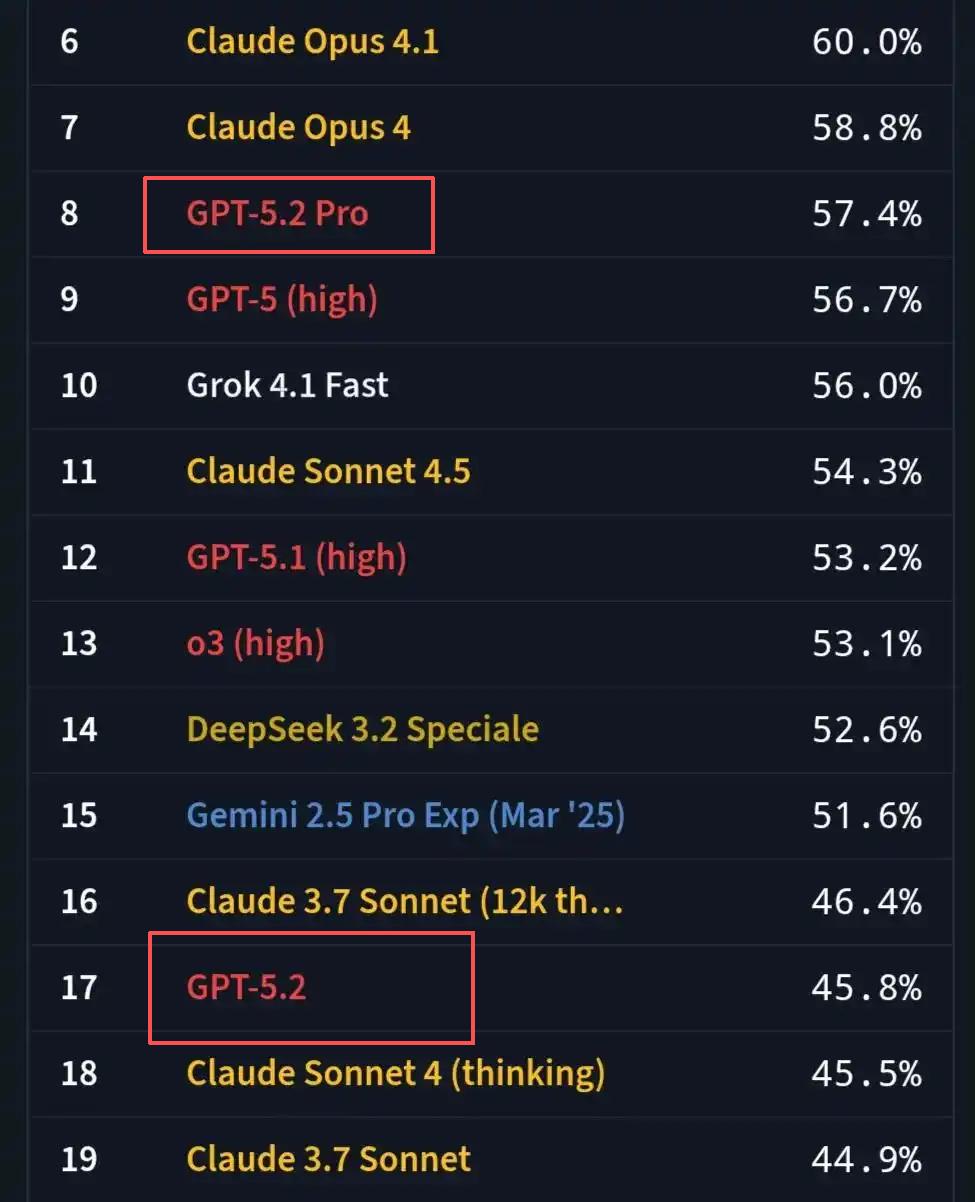
图源:SimpleBench
SimpleBench的设计初衷是用来测试大模型在“普通人看来很简单、但对机器而言极具挑战”的逻辑推理任务上的表现。
质疑声不止于此,前AWS与Google高管Bindu Reddy在社交平台发文指出,GPT-5.2在LiveBench上得分低于Opus 4.5和Gemini 3.0,它在token成本和消耗数量上也比5.1多得多,目前可能不值得从5.1切换升级。
GPT-5.2与Google抛出的“新招”Gemini 3 Flash形成了正面碰撞。如果说GPT-5.2的关键词是“专业性”,那么Google强调了一个词:性价比。
这并不是简单意义上的“更便宜”,而是一次对“性能、成本、规模”三者关系的系统性重构。
Google CEO桑达尔·皮查伊在官方博客中直言,Gemini 3 Flash在性能和效率上同时突破了“帕累托极限”:其综合性能超过上一代旗舰模型Gemini 2.5 Pro,推理速度提升约3倍,而价格却显著降低。
皮查伊说:“Gemini 3 Flash证明,速度和规模无须以牺牲智能为代价。”
从评测结果来看,这并非一句简单的营销口号。
根据Imarena.ai的数据,目前Gemini 3 Flash在文本、图像和编程领域排名前5,数学和创意写作类别排名第2,是性价比最高的前沿模型,输入仅0.5美元/百万Tokens,输出3美元/百万Tokens。
作为对比,Claude Sonnet 4.5的输出是15美元/百万Tokens,GPT-5.2的输出是14美元/百万Tokens,是Gemini 3 Flash定价的近5倍。
Gemini产品管理高级总监Tulsee Doshi称,谷歌将Gemini 3 Flash定位为“老黄牛”式模型。该模型保持了接近Gemini 3 Pro的推理能力,同时运行速度达到Gemini 2.5 Pro的三倍,成本仅为Gemini 3 Pro的四分之一。
4
智能体是未来的竞争点
纵观OpenAI与Google近段时间的密集更新,短期内谁胜谁负仍难下定论,但从产品设计、宣传重点与落地路径来看,大模型演进的下一个趋势已经愈发清晰。
无论是ChatGPT 5.2在宣传页面中反复强调的“专攻智能体”,还是Gemini 3 Flash将“高性能”直接推向大规模应用场景,这两条看似不同的路线,最终都指向同一个终点——智能体。
AI基础大模型的竞争,已经从“云端模型能力”全面下沉至“终端与系统层”。
从近期动作来看,Google与OpenAI的竞争早已不限于参数规模、推理能力与基准测试成绩。
在终端侧,Gemini 3已全面取代传统Google Assistant,成为Android生态的中枢。在最新的Android Auto更新中,这一变化尤为直观。用户在驾驶过程中,可以通过一次自然语言指令,完成跨应用、多步骤的复杂操作,例如查询邮件信息、发起导航并同步通知相关联系人。
在办公场景,Google正试图将这种“系统能力”延伸至Workspace。依托1M至2M tokens的超长上下文窗口,Drive、Docs、Gmail被整合为一个可直接对话的统一知识空间。用户不需要在文件与邮件之间反复切换,而是可以直接基于全部历史资料提出分析型问题,并生成结构化结果。这种工作流层面的改变,显著提升了企业用户的使用黏性。
企业市场的反馈正因此发生变化。
Salesforce创始人Marc Benioff近期公开表示,基于Gemini 3在推理速度和准确性上的表现,其个人及企业内部的AI首选已从ChatGPT转向Gemini。随后,Salesforce宣布将Gemini纳入Agentforce 360平台。这一动作,被视为Google在原本由微软与OpenAI主导的企业SaaS领域取得的重要突破。
面对Google的垂直整合,OpenAI选择了与科技巨头结盟扩张。在消费级市场,最重要的变量来自Apple。预计将于2025年底至2026年初推出的iOS 26,将深度整合GPT-5.1。这不仅是Siri后端能力的升级,更涉及系统级的视觉智能。通过硬件级相机入口,用户可直接调用GPT模型对现实环境进行识别和理解。
对OpenAI而言,这种“硬件直达模型”的路径,是其在移动端对抗Android生态优势的关键抓手。在企业与办公领域,Microsoft仍是OpenAI最稳固的支点。通过Windows 11与Microsoft 365,微软的人工智能助手Copilot持续将GPT-5.1推向企业核心流程。微软在操作系统层与企业云服务层的长期积累,仍构成OpenAI的重要护城河。
回顾过去三年,自2022年ChatGPT横空出世以来,行业竞争的核心始终围绕两点:对话是否自然、知识是否足够广。但到了2025年,随着企业对AI的期待从“内容生成”转向复杂问题解决、跨工具协作与自主任务执行,竞争维度已经发生根本变化。
看似路线不同,但终点一致:真正的分水岭,不在于谁更会聊天,而在于谁能把事干完、干好,并且持续稳定地干下去。而Gemini 3与ChatGPT 5.2,正好站在这条分岔路的两侧。
