

2026 年 1 月过半,我们依然没有等来 DeepSeek V4,但它的模样已经愈发清晰。
最近,DeepSeek 连发了两篇论文,一篇解决信息如何稳定流动,另一篇聚焦知识如何高效检索。
第一篇论文(mHC)出来的时候,打开论文的人都表示很懵,直呼看不懂,让 AI 助手用各种方式讲给自己听。我们也翻了翻网友的讨论,发现理解起来比较透彻的办法其实还是要回到研究脉络,看看这些年研究者们是怎么接力的。要理解第二篇论文(Conditional Memory)也是如此。
于是,我们就去翻各路研究者的分析。这个时候,我们发现了一个有意思的现象:DeepSeek 和字节 Seed 团队的很多工作其实是存在「接力」的 ——mHC 在字节 Seed 团队 HC(Hyper-Connections)的基础上进行了重大改进;Conditional Memory 则引用了字节 Seed 的 OverEncoding、UltraMem 等多项工作。
如果把这些工作之间的关系搞清楚,相信我们不仅可以加深对 DeepSeek 论文的理解,还能看清大模型架构创新正在往哪些方向突破。
在这篇文章中,我们结合自己的观察和学界专家的点评,尝试为大家梳理了一下。
残差连接的十年接力
要理解 mHC,得先回到 2015 年。
那一年,AI 大牛何恺明等人提出了 ResNet,用残差连接解决了深度神经网络训练中的老大难问题:网络层数一多,信息从前往后传递时会逐渐失真,到最后几层几乎学不到东西。残差连接的思路很简单,每一层不光接收上一层处理过的结果,还同时保留一份原始输入,两者加在一起再往下传。
这个设计堪称深度学习的基石,十年来几乎所有主流深度网络架构都以残差连接为默认配置。从视觉领域的各类 CNN,到自然语言处理领域的 Transformer,再到如今的大语言模型,无一例外。
期间,研究者们大多在注意力机制、归一化方法、激活函数等方面做了大量改进,但残差连接的基本形式几乎没有根本性变化。
直到 2024 年 9 月,字节 Seed 提出了 HC,论文后来被 ICLR 2025 接收。
HC 的核心创新在于显著提升了网络的拓扑复杂度,同时不改变单个计算单元的 FLOPs 开销。这意味着在相同的计算预算下,模型可以探索更丰富的特征组合方式。
中国人民大学长聘副教授、博士生导师刘勇认为:HC 打破了由 ResNet 统治的恒等映射残差连接传统,提出了多路并发连接的新范式。它通过引入宽度动态性和跨层特征聚合,证明了通过增加残差路径的特征维(Expansion)和引入可学习的 Dynamic Hyper Connections 可以有效缓解 Representation Collapse 的问题并提升大语言模型的预训练效率,提供了一个超越传统残差网络的全新架构底座,即不再局限于单路径的特征叠加,而是通过超连接构建一个更高维、更灵活的特征流动空间。
DeepSeek 在 mHC 论文中表示:近年来,以 Hyper-Connections(HC)(Zhu et al., 2024) 为代表的研究,为残差连接引入了一个新的维度,并在实验上验证了其显著的性能潜力。HC 的单层结构如图 1 (b) 所示。通过扩展残差流的宽度并提升连接结构的复杂性,HC 在不改变单个计算单元 FLOPs 开销的前提下,显著提升了网络的拓扑复杂度。
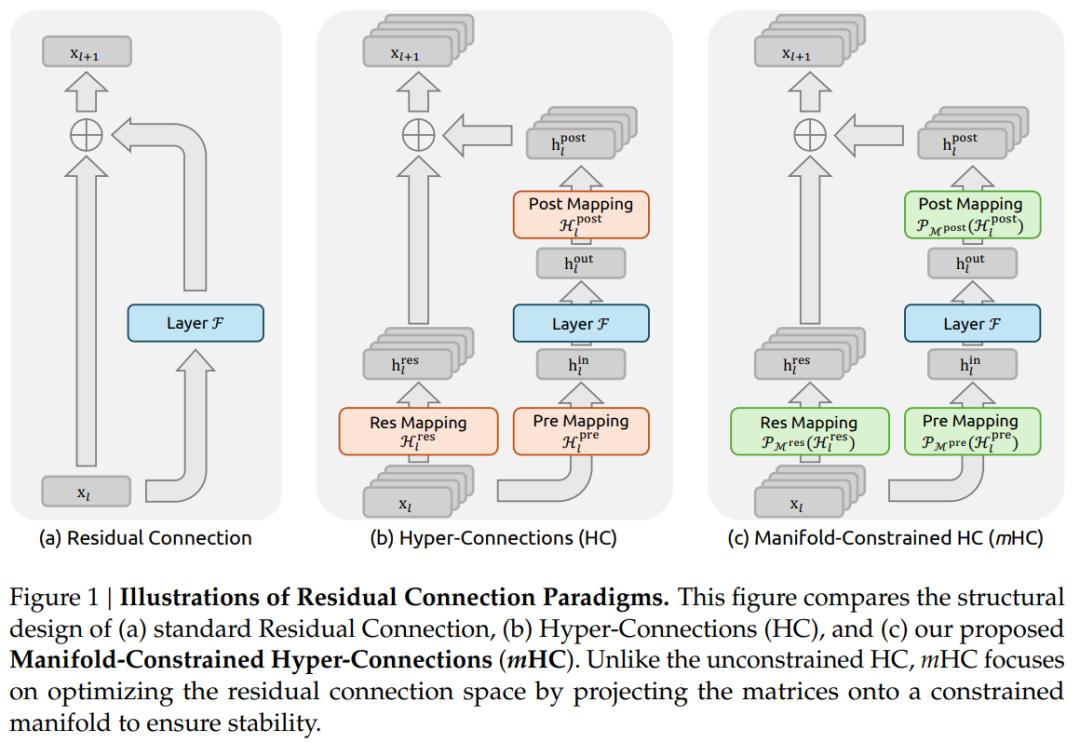
可以看出:字节 Seed 提出的「扩展残差流宽度 + 可学习连接矩阵」这一新的架构范式,构成了其后续方法设计的重要基础,相关工作正是在这一范式框架内进一步展开的。
但 HC 在走向大规模训练的过程中遇到了瓶颈,导致训练不稳定和受限的可扩展性。尽管如此,但其为后续研究指明了方向。刘勇认为,HC 论文为 mHC 研究提供了三个核心思路:
首先是宽度扩展(Stream Expansion),即通过将残差流维度扩大(如扩大至 4 倍或更多),能够显著增强模型的容量和学习能力;
其次是多尺度连接的权重化,通过引入可学习矩阵来分配不同层级特征的贡献,启示了连接权重管理(mHC 中的 Sinkhorn-Knopp 算法)的重要性;
最后是动态拓扑的潜力,论文展示了模型可以根据深度动态调整特征流向,这种软拓扑结构为解决深层网络训练难点提供了新视角。这些探索让 mHC 意识到,虽然拓扑结构的复杂化能带来增益,但也必须解决随之而来的训练稳定性与工程效率问题。
正是基于这些探索,DeepSeek 团队得以明确 mHC 的研究方向:在继承 HC 架构优势的同时,针对性地解决其规模化瓶颈。
刘勇指出:mHC 针对 HC 在大规模部署时暴露的稳定性风险和内存访问开销进行了针对性改进。在研究思路上,mHC 延续了 HC 的宽度扩展与多路径聚合,并进一步通过 Sinkhorn-Knopp 等技术手段,施加流形约束,将 HC 的广义空间投影回特定流形,从而在保留 HC 性能优势的同时,重新找回了残差网络至关重要的恒等映射特性,解决了 HC 在超大规模训练时的不稳定性。在工程层面,mHC 中提出了更高效的内核优化(Infrastructure Optimization),使该范式从理论实验走向了万亿级参数规模的工业级应用。
基于这些改进,mHC 不仅解决了稳定性问题,且在大规模训练中(如 27B 模型)表现出卓越的可扩展性。
我们不难发现,mHC 解决了 HC 在大规模训练中的工程瓶颈。通过引入流形约束,mHC 在保留 HC 架构优势的同时恢复了训练稳定性,使得这一新范式真正具备了在主流大模型训练中应用的条件。
有网友认为:DeepSeek 提出的 mHC 是对字节 Seed HC 训练架构技巧的一次颇具说服力的推进。

从 2015 年残差连接问世,到 2024 年字节 Seed 提出 HC,再到 2026 年 DeepSeek 提出 mHC,我们清楚地看到残差连接在算法上的演进,是不同机构、研究者持续接力和优化的结果。
而在 DeepSeek 发布的另一篇论文中,我们看到了几乎相同的模式再次上演。
都用 N-gram,字节 Seed、DeepSeek 接连导出新结论
和 mHC 论文的「抽象」感不同,「Conditional Memory」论文解决的问题比较好理解:大模型被问到的很多问题是可以直接查表解决的,比如「法国的首都是哪里」,但由于标准 Transformer 缺乏原生的知识查找原语,即使这样简单的问题,模型也得去计算,就像你上了考场还要自己推导公式,这无疑是一种浪费。
对此,「Conditional Memory」论文提出的解决方案是给模型装一个「小抄本」(Engram),常见的词组直接查表,省下来的算力用来做更复杂的推理。
具体来说,Engram 的做法是:给模型配一个巨大的「词组词典」,当模型读到某个词(比如「Great」时,就把它前面几个词拼成 N-gram(比如「the Great」或「Alexander the Great」),然后用哈希函数把这个 N-gram 变成一个数字,直接去词典里查对应的向量。
这个「N-gram 哈希查表」的做法,字节 Seed 之前也用过。在提出OverEncoding 方法的论文(题为「Over-Tokenized Transformer: Vocabulary is Generally Worth Scaling」)中,他们发现:给模型配一个巨大的 N-gram 词典,几乎是「白捡」的性能提升。为什么说白捡?刘勇分析说,因为这些海量的嵌入参数是稀疏激活的,每次推理只查其中极少数,所以既不怎么吃显存,也不怎么费算力。更重要的是,论文发现词典越大、性能越好,而且提升幅度是可预测的。
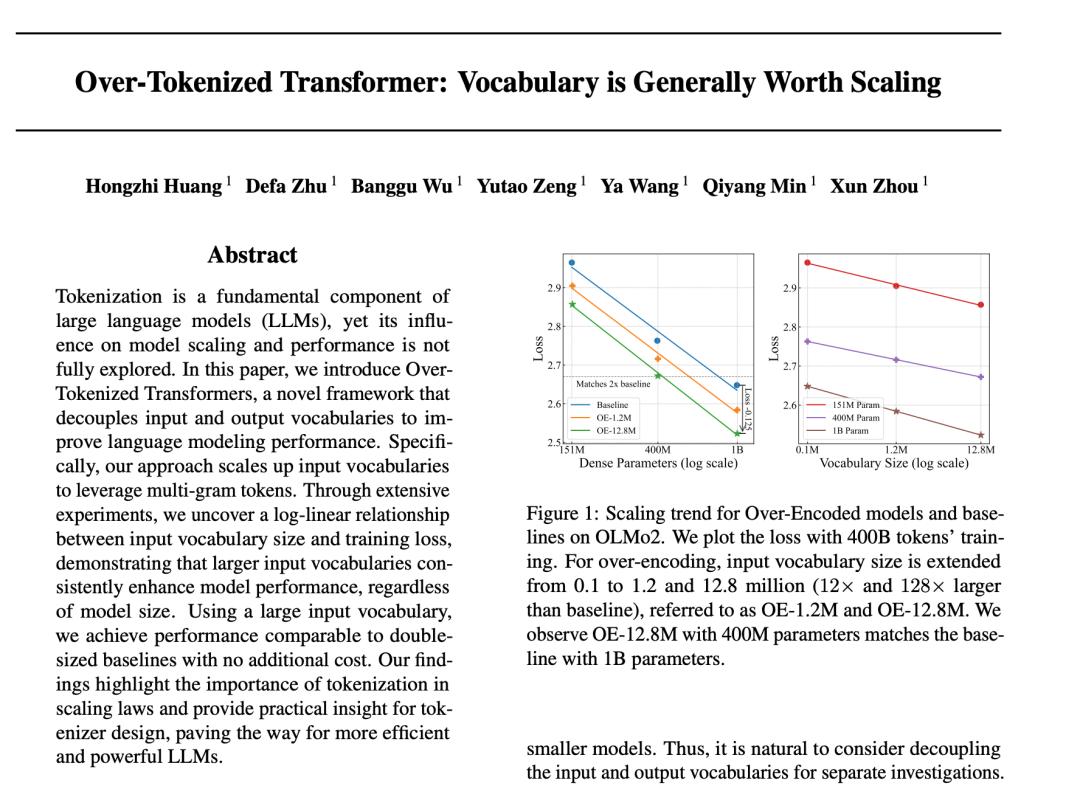
论文地址:https://arxiv.org/pdf/2501.16975
如果说字节 Seed 论文用实验告诉我们「把输入词表加大就能涨分」,DeepSeek 论文则另开一条赛道:把 N-gram 做成外挂存储 Engram,与 MoE 分工,正式提出「条件存储」这条新轴线,并告诉我们该怎么分参数才最划算。
还是回到考场的比喻:字节 Seed 发现给学生发公式手册成绩会提高,于是得出结论 ——「大词表是更好的输入表示」。DeepSeek 则进一步追问:这种做法还能以什么方式提高成绩?他们通过 LogitLens 等工具进行机制分析,发现这种 lookup 机制能将模型从繁重的局部静态模式重建中解放出来,使早期层直接获得高阶语义,从而增加了模型的有效推理深度。
基于这个洞察,DeepSeek 不再仅仅将 N-gram 视为简单的词表扩展,而是将这一实验性结论升华为「条件存储」(Conditional Memory),这是一条与条件计算(MoE)并列的 scaling law 新轴线。在此基础上,他们提出了「稀疏分配」(Sparsity Allocation)问题:在固定参数预算下,如何在 MoE 专家与静态存储模块之间分配参数?实验揭示了一条 U 型缩放规律 —— 全押 MoE 并非最优解,将约 20%-25% 的参数分配给 Engram 反而效果更好。
刘勇表示,在工程实现上,DeepSeek 也进行了系统性的技术改良。架构层面,它改进了前作仅在输入层(Layer 0)注入信息的局限,将 Engram 模块注入到模型的中间层,使存储访问与深度计算实现并行与融合。交互机制上,它放弃了简单的嵌入加和,引入了「上下文感知门控」,利用隐状态动态调节检索结果。系统优化上,它通过分词器压缩提高存储效率,并利用硬件层面的预取技术(Prefetching)解决海量参数导致的延迟问题,使该技术真正具备了大规模工业落地的能力。
在论文的 3.2 章节,我们发现,DeepSeek 把自己的 Engram 与字节 Seed 的 OverEncoding 方法进行了对比,指出虽然两者都能从更大的嵌入表中获益,但在相同的参数预算下,Engram 的缩放效率明显更高。
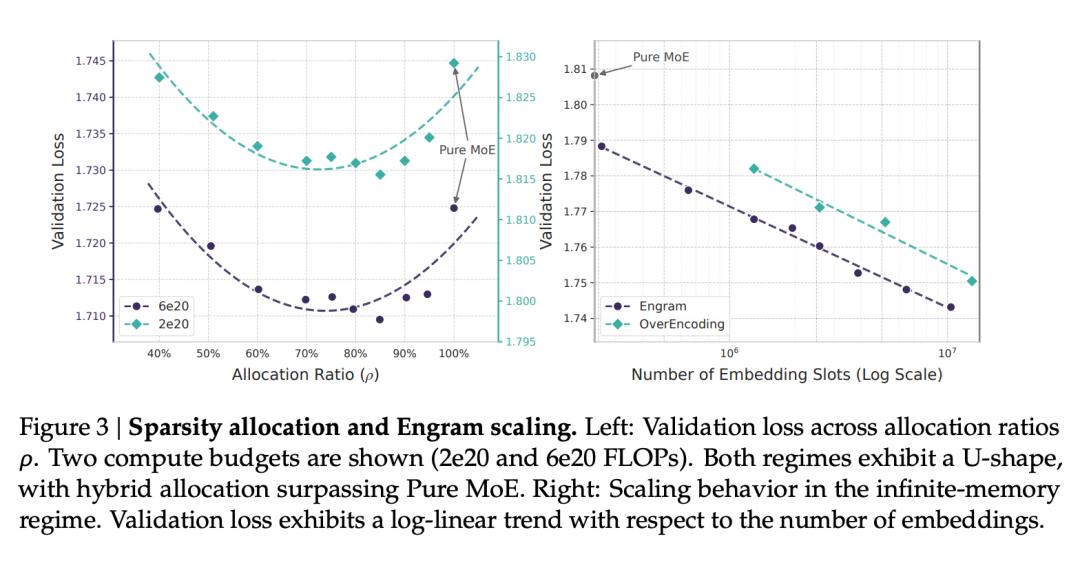
一起上分、互相启发
研究发表的意义具象化了
每次 DeepSeek 一发论文,推特上都能引发不小的轰动,有位博主甚至提到他搭乘的飞机上有 30% 的人都在看 DeepSeek 刚发的论文。
归根结底,这反映出一个问题 —— 目前还愿意公开自己研究成果、带着大家一起「上分」的头部大模型厂商已经越来越少了。DeepSeek 和字节 Seed 在研究上的接力让我们看到了公开研究成果的价值。
同时,DeepSeek 对于社区内优秀成果的挖掘也给了我们一些启发,类似字节 Seed 这样的国内头部大模型团队其实有很多想法值得继续探索。
比如,在架构层面,除了前面提到的 OverEncoding,DeepSeek 论文中还提到了几篇字节 Seed 的相关研究,包括稀疏模型架构 UltraMem 和它的新版本 Ultramemv2。这个全新的模型架构通过分布式多层级联内存结构、Tucker 分解检索与隐式参数扩展优化,有效解决了传统 MoE 架构在推理阶段的高额访存问题,同时验证了其优于传统架构的 Scaling Law 扩展特性。

此外,字节 Seed 在基础研究上还发表过很多大胆探索全新范式的尝试,比如Seed Diffusion Preview,系统性地验证离散扩散技术路线作为下一代语言模型基础框架的可行性;SuperClass,首次舍弃了文本编码器,直接用原始文本的分词作为多分类标签,在视觉任务上效果优于传统的 CLIP 方法;甚至提出了新型神经网络架构FAN,通过引入傅里叶原理思想,弥补了 Transformer 等主流模型在周期性建模方面的缺陷。
这些底层技术的研究,虽然在短期内无法用于商业模型的训练,但是科技行业的进步,正是在无数研究者对未知领域的探索中发生的。
毕竟,真正推动技术进步的,从来不是单一的突破,而是持续的积累与相互启发。
