

所有人都能用,英伟达开源VLA自动驾驶模型。
日前,英伟达(NVIDIA)研究团队正式发布并开源全新的视觉-语言-动作(VLA)模型Alpamayo-R1,(简称:AR1)并明确宣布计划在未来的更新中开源该模型的部分核心数据集。
▲Alpamayo-R1对应的数据集已上传至开源社区
目前,该模型对应的数据集也已上传至开源社区,总大小约100TB,这也是英伟达首次将VLA模型进行开源。
在数据许可的部分,英伟达明确了数据集可以用于商业和非商业用途,这或许意味着之前没有太多VLA技术积累的公司,也可以通过英伟达快速上手VLA的开发了。

▲Alpamayo-R1模型架构
这一举措不仅打破了高端自动驾驶模型的封闭高墙,更标志着端到端自动驾驶技术从单纯的“模仿行为”迈向了具备深层“因果思考”的新阶段。
对于自动驾驶行业而言,Alpamayo-R1的出现直击了当前最令人头疼的痛点——长尾场景(Long-tail scenarios)下的安全性。
英伟达此次带来的 Alpamayo-R1正是为了终结这一困境,而其交出的实测成绩单也足够令人信服。

▲Alpamayo-R1相对基线的提升明显
在针对极高难度长尾场景的测试中,AR1的规划准确率相比仅有轨迹预测的基线模型提升了整整12%;
在闭环仿真测试里,AR1成功将车辆冲出道路的事故率降低了35%;
与其他车辆或行人的近距离危险遭遇率也大幅减少了25%。
更值得一提的是,即便在集成复杂的推理大脑后,该模型在NVIDIA RTX 6000 Pro Blackwell车载硬件上依然保持了99毫秒的端到端超低延迟,完全满足了实时自动驾驶的严苛需求。
01.
解决自动驾驶端到端黑盒问题
引入因果链数据集
过去几年,基于模仿学习的端到端大模型虽然通过堆砌数据量取得了显著进步,但它们本质上更像是一个只会死记硬背的“黑盒”。
这些模型能够精准模仿人类驾驶员的操作,却缺乏对场景的因果理解。它们知道“前面有车要刹车”,却不知道“为什么要刹车”。
这种知其然不知其所以然的缺陷,导致车辆在面对从未见过的高风险复杂路况时,往往表现脆弱,决策逻辑甚至自相矛盾。
VLA模型这种将“世界知识”引入驾驶舱的能力,是突破 L4 级自动驾驶长尾难题目前的公认解决方案之一。

▲理想汽车VLA模型架构
但是,VLA不仅存在模型幻觉(Hallucination)、延迟等问题,VLA的研发对于算力、算法、数据集的要求极高,目前也只有小鹏、理想、小米、元戎启行等头部企业在推动VLA上车。
开源项目方面,除了英伟达此次的AR1,也只有OpenDriveVLA 等学术界项目在迭代。
所以说,此次英伟达的VLA模型和数据集的开源犹如一颗炸弹,给VLA的研发落地带来了一些新的变化。
具体来看英伟达的项目,为了让AI真正学会像人类老司机一样思考,英伟达并没有选择在现有模型上修修补补,而是从最底层的数据构建开始了一场革命。
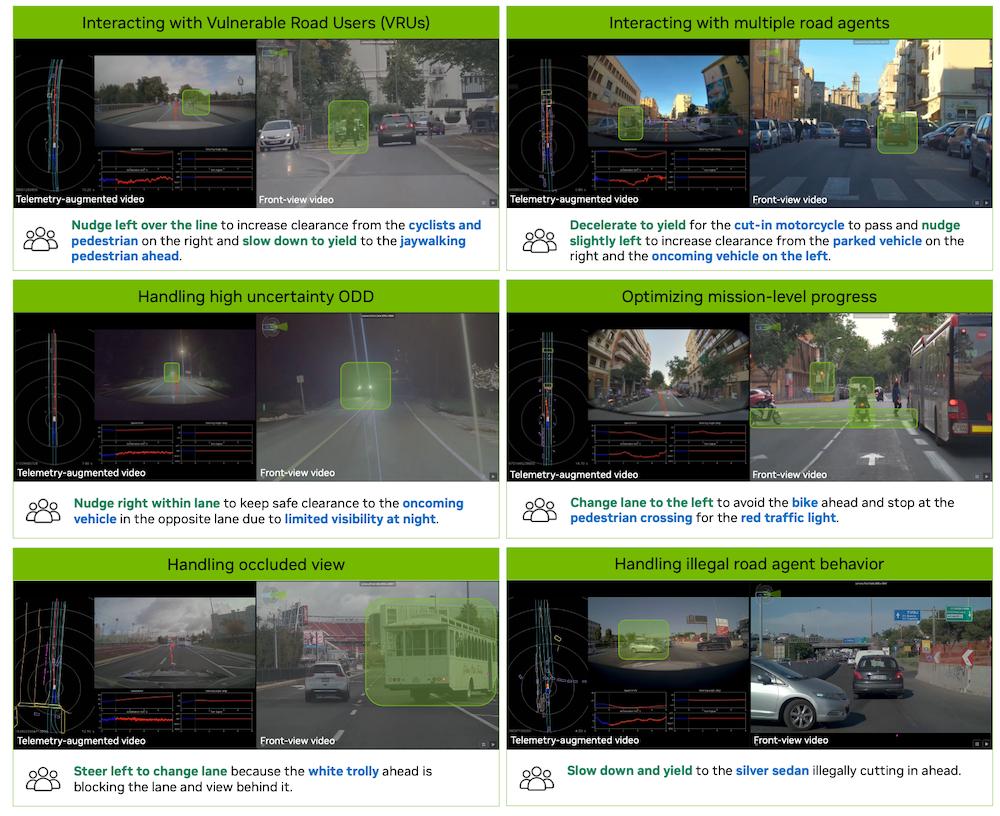
▲因果链推理演示
为了解决传统数据集中描述模糊、缺乏逻辑关联的问题,研究团队构建了一套全新的“因果链”(Chain of Causation, CoC)数据集。
这套数据集的核心在于教会模型建立“观察-原因-决策”的严密逻辑闭环。它不再让AI生成诸如“天气晴朗、路面宽阔”这类无关痛痒的旁白。
在这套模型下,提示词可明确指出“因为左侧有车辆正在强行并线,且前方有行人横穿,所以我决定减速避让”。
这种数据构建方式不仅消除了因果混淆,更有效提升了模型的逻辑性。
02.
引入新架构 平衡模型性能
在强大的数据支撑下,Alpamayo-R1采用了一种模块化且高效的架构设计,巧妙地平衡了“慢思考”与“快行动”。
其大脑由英伟达专为物理AI打造的Cosmos-Reason视觉语言模型驱动,负责处理复杂的环境理解和逻辑推理。
而行动则交由一个基于流匹配(Flow Matching)技术的动作专家解码器来控制。
这种分工合作的机制,让模型既能利用大语言模型的广博知识进行深思熟虑,又能通过扩散模型生成丝般顺滑且符合车辆动力学的行驶轨迹,完美解决了大模型通常反应迟钝的弊病。
不过,真正让Alpamayo-R1与众不同的,是其在训练阶段引入的强化学习(RL)机制。
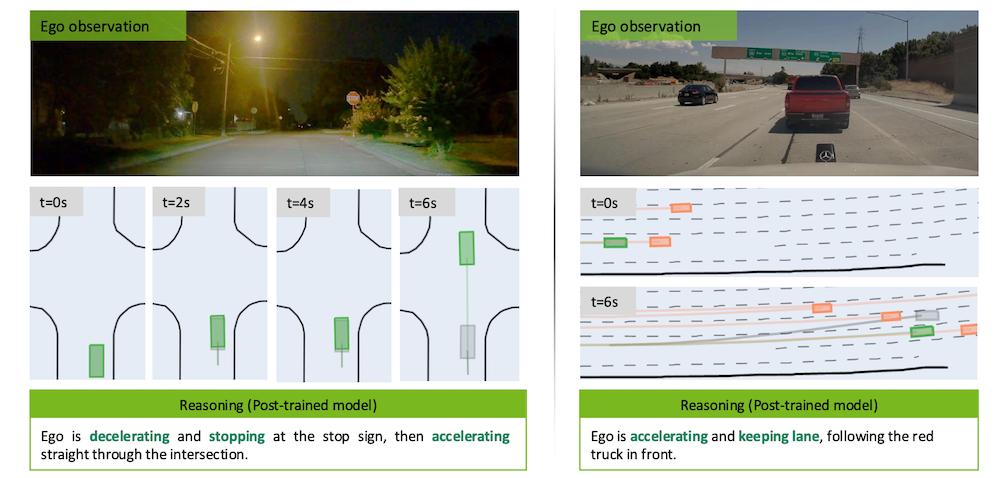
▲推理-动作高一致性将提升奖励
在监督学习教会模型基本的驾驶技能后,研究人员引入了一个更为严苛的“判卷老师”——利用更大规模的推理模型作为批评者(Critic),对AR1的表现进行打分。
这个阶段的训练目标非常明确——要求模型言行一致。
对此,该模型中的奖励函数不仅看重车辆是否开得安全,更看重模型嘴上说的推理逻辑与实际做出的驾驶动作是否吻合。
如果模型推理说“因为红灯要停车”,但实际动作却在加速,它就会受到严厉惩罚。

▲采用强化学习新模式后质量显著提升
这种训练方式让AI的解释不再是一种事后的敷衍,而是真正成为了指导车辆行动的决策纲领,推理质量因此提升了45%,推理与行动的一致性也提高了37%。
在论文的最后还有一个小彩蛋,致谢中排在第一位的正是英伟达自动驾驶方面的负责人吴新宙。

▲吴新宙在致谢第一位
吴新宙可谓是自动驾驶圈内的红人,在加入英伟达之前,他曾担任小鹏汽车自动驾驶副总裁。
2023 年 8 月,吴新宙正式加盟英伟达,出任英伟达汽车业务副总裁(Vice President of Automotive),直接向 CEO 黄仁勋汇报,他目前全面负责英伟达自动驾驶软件算法的研发与落地。
03.
结语:英伟达首次开源VLA模型
Alpamayo-R1的发布与开源,其意义不仅仅是发布高性能模型本身,对于自动驾驶行业而言,这可能是一次重新洗牌的开始。
长期以来,高阶端到端自动驾驶的研发门槛极高,仅掌握在拥有海量数据和算力的巨头手中。
英伟达通过开源AR1及数据集,实际上是向全行业提供了一套L4级自动驾驶的“参考答案”,这有效地降低了中小厂商和研究机构的入场门槛,也可能会催生出一批基于AR1微调的自动驾驶方案。
而对于英伟达自身,这一动作更是其“软硬一体”战略的体现。AR1 展现出的强大性能,必须依赖于英伟达强大的 GPU 算力和配套的Cosmos 框架工具链。
通过定义最先进的软件范式,英伟达正在潜移默化地锁定未来的硬件市场。
